继续捡宝贝~
http_accounting 是 Nginx 的一个第三方模块,会每隔5分钟自动统计 Nginx 所服务的流量,然后发送给 syslog。
流量以 accounting_id 为标签来统计,这个标签可以设置在 server {} 级别,也可以设置在 location /urlpath {} 级别,非常灵活。
统计的内容包括响应字节数,各种状态码的响应个数。
公司原先是有一套基于 rrd 的系统,来收集处理这些 syslog 数据并作出预警判断、异常报警。不过今天不讨论这个,而是试图用最简单的方式,快速的搞定类似的中心平台。
这里当然是 logstash 的最佳用武之地。
logstash.conf 示例如下:
input {
syslog {
port => 29124
}
}
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|(?:200:%{NUMBER:count.200:int}\|?)?(?:206:%{NUMBER:count.206:int}\|?)?(?:301:%{NUMBER:count.301:int}\|?)?(?:302:%{NUMBER:count.302:int}\|?)?(?:304:%{NUMBER:count.304:int}\|?)?(?:400:%{NUMBER:count.400:int}\|?)?(?:401:%{NUMBER:count.401:int}\|?)?(?:403:%{NUMBER:count.403:int}\|?)?(?:404:%{NUMBER:count.404:int}\|?)?(?:499:%{NUMBER:count.499:int}\|?)?(?:500:%{NUMBER:count.500:int}\|?)?(?:502:%{NUMBER:count.502:int}\|?)?(?:503:%{NUMBER:count.503:int}\|?)?"
}
date {
match => [ "timestamp", "MMM dd HH:mm:ss", "MMM d HH:mm:ss" ]
}
}
output {
elasticsearch {
embedded => true
}
}
然后运行 java -jar logstash-1.3.3-flatjar.jar agent -f logstash.conf 即可完成收集入库!
再运行 java -jar logstash-1.3.3-flatjar.jar web 即可在9292端口访问到 Kibana 界面。
然后我们开始配置界面成自己需要的样子:
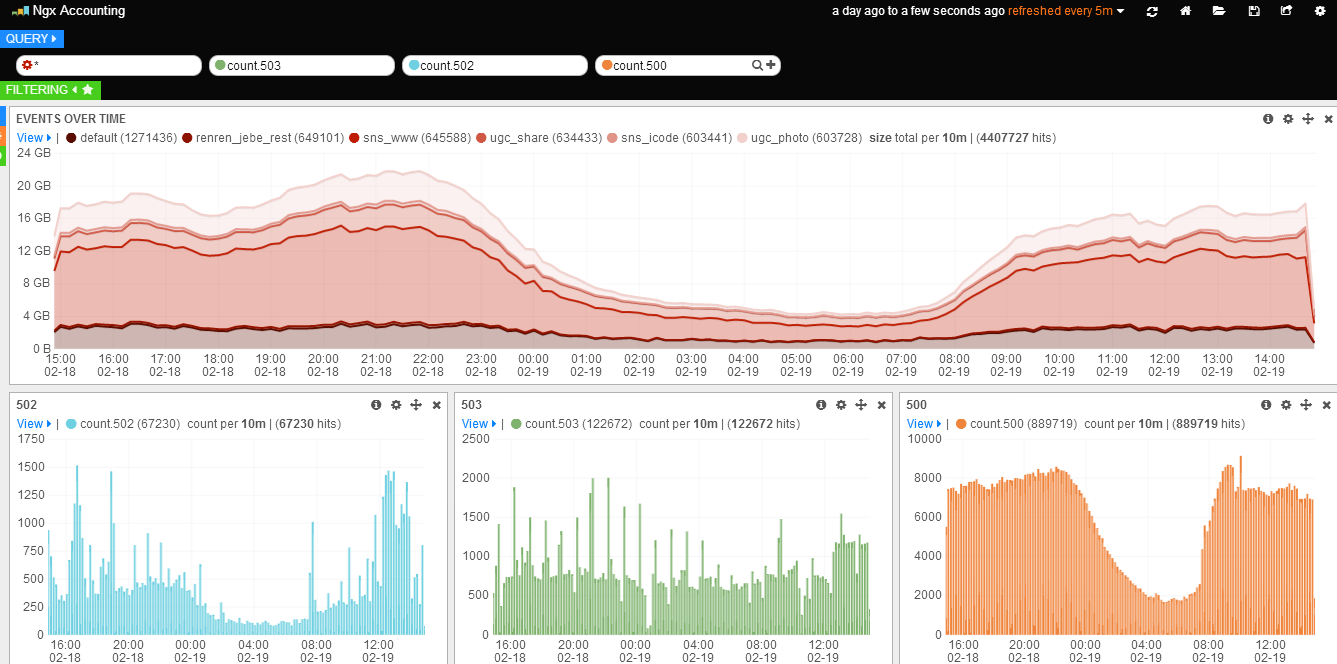
- Top-N 的流量图
点击 Query 搜索栏左边的有色圆点,弹出搜索栏配置框,默认是 lucene 搜索方式,改成 topN 搜索方式。然后填入分析字段为 accounting。
点击 Event Over Time 柱状图右上角第二个的 Configure 小图标,弹出图表配置框:
- 在
Panel选项卡中修改Chart value的count为total,Value Field设置为 size,勾选Seconds项,转换 size 的累加值成每秒带宽(不然 interval 变化会导致累加值变化); - 在
Style选项卡中修改Chart Options的Bars勾选项为Lines,Y Format为 bytes; - 在
Queries选项卡中修改Charted Queries为selected,然后点中右侧列出的请求中所需要的那项(当前只有一个,就是*)。
保存退出配置框,即可看到该图表开始自动更新。
- 50x 错误的技术图
点击 Query 搜索栏右边的 + 号,添加新的 Query 搜索栏,然后在新搜索栏里输入需要搜索的内容,比如 count.500;
鼠标移动到流量图最左侧,会移出 Panel 快捷选项,点击最底下的 + 号选项添加新的 Panel:
- 选择 Panel 类型为
histogram; - 选择 Queries 类型为
selected,然后点中右侧列出的请求中所需要的那项(现在出现两个了,选中我们刚添加的count.500)。
保存退出,即可看到新多出来一行,左侧三分之一(默认是span4,添加的时候可以选择)的位置有了一个柱状图。
重复这个步骤,添加 502/503 的柱状图。
- 仪表盘设置存档
页面右上角选择 Save 小图标保存即可。之后再上界面后,就可以点击右上角的 Load 小图标自动加载。
上面这个 grok 写的很难看,不过似乎也没有更好的办法~下一步会研究在这个基础上合并 skyline 预警。
2014 年 5 月 10 日更新:
在 logstash/docs 上发现一个 filter 叫 kv,很适合这个场景,可以大大简化 grok 工作,新的 filter 配置如下:
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|%{DATA:status}"
}
kv {
target => "code"
source => "status"
field_split => "|"
value_split => ":"
}
ruby {
code => "n={};event['code'].each_pair{|x,y|n[x]=y.to_i};event['code']=n"
}
}
不晓得为什么 filter/mutate 不提供转换 Hash 的功能,所以只能把这行写在 filter/ruby 里面。kv 截出来的 value 默认都是字符串类型。
2014 年 5 月 28 日更新:
发现默认的 LVS 检查导致的 400 会记录到默认的 accounting 组(“default”)里,虽然不占带宽,却占不少请求数。这类日志可以在 logstash层面就干掉:
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|%{DATA:status}"
}
if [accounting] == 'default' {
drop { }
} else {
kv {
target => "code"
source => "status"
field_split => "|"
value_split => ":"
}
ruby {
code => "n={};event['code'].each_pair{|x,y|n[x]=y.to_i};event['code']=n"
}
}
}
另外说明一下,ngx_http_accounting_module 中设定 http_accounting_id 这步是预先处理的,所以只能写固定字符串,不能用 $host 之类的 nginx.conf 变量。



