智能运维平台的内核驱动力来自数据(日志和指标)分析。从广义范畴来说,所有可以用作数据处理的软件系统,都可以用来构建这个平台。从远古时代的awstats到piwik,到人手一个的hadoop集群(确实没有更抽象具体的运维向子产品),到目前最流行的ELK,包括新近的基于PostgreSQL搞的TimeseriesDB,基于Solr搞的Rocana等等。
在对比所有这些产品的技术选择和接口设计的时候,总让我想起一句话:「一个幽灵,查询语言的幽灵,在社区徘徊」。
SQL 与 DSL
其实在刚流行hadoop的时候,并没有这么多事儿。熟悉java的开开心心写mapreduce,不熟悉java的人也乐呵呵的走streaming API,用自己熟悉的旁的编程语言写mapreduce。
但随后各种SQL-like的项目就雨后春笋般的涌现了。SQL的全称:structured query language。虽然在数据库面前,SQL更像是一种API,但是在谈论DSL的时候,SQL无疑就是最成功的DSL之一。
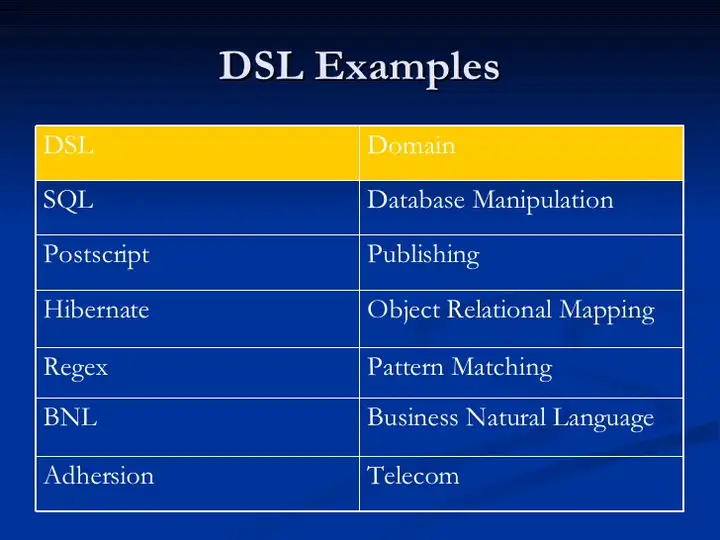
对于我这个半吊子程序员来说,上图这些样例只了解regex和SQL两样。不过最给我印象深刻的DSL设计,是Ruby社区的sinatra项目。
# myapp.rb
require 'sinatra'
get '/' do
'Hello world!'
end
这个漂亮的语法简直让我惊为天人。从此对DSL大法深信不疑。
SQL 是数据处理 DSL 的唯一选择么?
SQL虽然是最成功的DSL之一,但它当然不是数据处理领域唯一的DSL——因为数据处理这个「领域」还是太大了。
比如,细分到CEP(复杂事件处理)领域,更通行的就是CQL。像Esper、Siddhi等,大致写法是这样(注意看分号的位置):
define stream TempStream (deviceID long, roomNo int, temp double);
from TempStream
select roomNo, temp * 9/5 + 32 as temp, 'F' as scale, roomNo >= 100 and roomNo < 110 as isServerRoom
insert into RoomTempStream;
包括oracle,华为等,也都有CQL设计(是的,我就是在写这行文字前刚搜索得知的)。
又比如,细分到BI(商业智能)领域,行业老大tableau,有一套自己的VizQL™。这也是证明DSL设计很有趣的一点。infoQ上有一篇文章叫《领域专用语言(DSL)迷思》,其中第三条误解就是「DSL必须以文本代码的形式出现」。tableau的VizQL就是一个典型的范例——这完全是一种视觉交互式的查询语言,和文本代码半点不相干。
那么 DSL 怎么搞?
我在 http://t.cn/Ra53rH9 上看到有这么一个回答:

分解任务、解决任务、归并相似任务、把解决方案原型化、最终产品化。真是漂亮的步骤,把这个步骤,套回到我们最原始的目的:智能运维平台,就可以发现,所谓DSL设计,主要考验的是设计者对运维工作的理解力。
BTW:这个问题里的另一回答把crontab作为一个DSL范例举出来了,这么说我要收回前文有关sinatra的惊叹……
到底智能运维平台需要什么样的DSL?
从problem看,我们有这么几大类:
- 按照某些逻辑查找或排除日志中的有效部分;
- 分析某些系统的状态并判定其异常;
- 按照某些逻辑确定异常是否发送以及以何种形式发送给哪些处理方(人或系统)。
第一类显然最简单了,仿照grep -E或者grep -P的搞法可以是一种,仿照搜索引擎的搞法也是一种。(是的,并不是所有的日志产品都用lucene querystring syntax)
第三类也是比较明确的,nagios的object group设计就很棒,而近来流行的IFTTT风格也不错。我见过携程的朋友提供这种风格的DSL给开发做主动监控,而prometheus的alertmanager里也是一样的玩法。
唯独第二类话题极其大。系统状态,包括了性能指标、行为基线等不同方面,可以动用各种简单的复杂的数学统计乃至机器学习知识。所以还要继续拆解。
简单的均值趋势、占比统计,这也是大多数监控系统仪表盘最爱用的功能了。这些统计函数,基本上在SQL里也都有。由此很自然会引发一个想法:是不是可以用SQL来解决第二类需求?
为什么SQL不适合?
我们再念一遍SQL的全称:structured query language,structured * 3。
这和智能运维平台所承载的logdata是冲突的。和metricdata也在渐渐冲突……(越来越多的metric系统也在JSON化)
logdata是带有时间戳属性的非结构化数据。虽然平台为了权限管理和分析方便,除了timestamp,一般还会内置有hostname、tag、logtype等少量信息,但是总体上来说,日志信息依然是非结构化的。
即使在目前常见的 ELK 系统中,logstash 的预解析字段有点类似 create table 的意思,也不能改变这个字段解析结果只存在于单条日志中的事实。对于日志整体来说,这个 schema 依然是不固定的。
把眼光从ELK系统再往上一层,需要搭建的是一个智能运维平台,平台用户是横跨部门的。这时候还会有更严重的一个问题:同一份日志,业务部门、运维部门、安全部门可能需要关注的信息完全不一样。即便是单条日志内的预解析为结构化数据都不可行。
由此,就得到了_第一个problem:不同人对同一条日志可能采取不同的字段解析。_
其次,日志信息受限于码农水平或者心情,很可能是极其杂乱无章的。多线程交叉多行打印一个事件是经常会发生的事情。怎么抽丝剥茧,从复杂文本中获取业务处理请求的关系链,以及各级关系的权重,这是第二个problem。
再次,异常状态如何表达,表格并不是唯一的选择,甚至多数时候表格完全表达不出来重点和非重点数据的区别。针对不同场景理所当然应该有不同的表达方式。虽然这涉及更多是可视化效果的选择,(即便我们抛开VizQL这种特例不谈)我们也需要自己的 DSL 给出前端可用的特定属性信息作为一种指向。比如,我们希望根据横向对比的情况来查找某种异常的可能性,就会同时用到 GROUPBY 和 HISTOGRAM 两个方式的组合,而根据 group 的层级和含义,可能就会选择简单的多折线,联动的 timeline,或者表格里的 sparkline 迷你图。这是第三个problem:需要有针对场景的表达力。
当然,比起饼图,还是表格更好。
那什么合适呢?
这个事情可能真的就是看个(P)人(M)偏好了。比如我作为一个运维+perl/ruby爱好者,就觉得不管是UNIX pipeline式,还是method chaining式,都很棒。这两种设计,把复杂方案隐藏起来,只留给最终用户一个command/method给用户按需选用即可。(让JSON地狱去死)
不过从保持一致性的角度出发,对于日志系统,可能还是选用shell pipeline式更合适一点。jordansissel 在介绍 Logstash 的内部原理时,就使用了 pipeline 的概念(事实上连代码里也叫 pipeline):
inputs filters outputs
所以对数据的后半段,继续沿用pipeline概念就是很顺理成章的事情了。
这是其一。
其二,在处理尤其常用的检索需求时,pipeline比method更灵活一些。还是一致性的考虑,最初的inputs,对于pipeline可以直接无缝对接,但是对于method,是不是我们还需要搞个Object.new?
让我们来看看两个示例吧,其实我觉得都还好?:
index=summary starttime=now-7d/d endtime=now/d domain=(aaa OR bbb)
| bucket timestamp span=15m as ts
| stats avg(apache.reqtime) as avg_ by ts
| esma avg_ timefield=ts futurecount=24
| where typeof(_predict_avg_) == "double"
| eval time = formatdate(ts, "HH:mm")
| table time, _predict_avg_
| join type=left time [[
starttime="now/d" *
| bucket timestamp span=15m as ts
| stats avg(apache.reqtime) as avg_ by ts
| eval time = formatdate(ts, "HH:mm")
| table time, avg_
]]
然后写成:
Search(index="summary", starttime="now-7d/d", endtime="now/d", domain=["aaa", "bbb"])
.bucket(timestamp, span=15m)
.avg(apache.reqtime)
.esma(timefield=ts, futurecount=24)
.select { |ts| ts._predict_avg_.is_a?(Double) }
.formatdate("HH:mm")
.table("time", "_predict_avg_")
.join(type=left, id=time,
Search(starttime="now/d", "*")
.bucket(timestamp, span=15m)
.avg(apache.reqtime)
.formatdate("HH:mm")
.table("time", "avg_")
)
对比一下,可能最明显的感觉就是:.table()函数里的那些字段名是怎么突然出现的?因为一个method对object的作用不是显式的,你不看文档是没法知道调用一个method以后会生成什么object,拥有哪些attributes的。而前者的as参数就非常的简明扼要。
你扯了这么多,别人的想法呢?
是的,其实做一个PM很多时候相互关心一下同行的思路太应该了……国内同行不太开放,所以只能收集到国外同行的数据。下图为主要AIOps产品的DSL所提供的的指令/函数数量的雷达图:
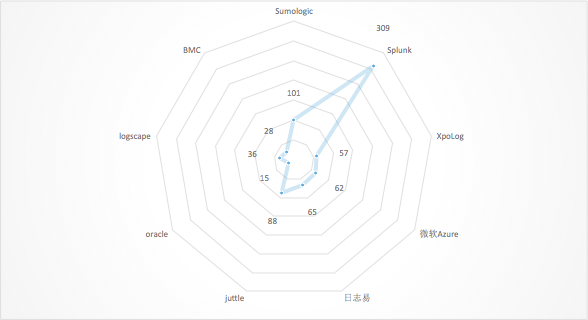
(基于2017.05数据,毕竟AIOps的公司大多在高速发展中) 此外:
HPE也有类似形式的AQL,不过他们太疯狂,直接跟自己另一款分布式R语言产品捆绑销售,AQL里可以调用R函数,尼玛那一下子太多了……
logscape是半pipeline半method方式,很奇葩的写法,如下。我个人觉得连一致性都无法保证的设计是失败的。
type='agent-stats'
| hosts(cache,db) cpu.avg(_host) chart(line) buckets(1)
ELK中timelion是method方式,如下:
.es('metric:0', metric='avg:value')
.label("#0 90th surprise"),
.es('metric:0', metric='avg:value')
.showifgreater(
.es('metric:0', metric='avg:value')
.movingaverage(6)
.sum(
.es('metric:0', metric='avg:value')
.movingstd(6)
.multiply(3)
)
).bars()
.yaxis(2)
.label("#0 anomalies")
这里几乎把所有的query和aggregation都合并到.es()的参数里,导致method本身功能局限在图形设置和最终的pipeline aggregation功能上,感觉还是有待改进~
最后的补充
能扯的其实已经扯完了,不过突然发现之前我一直保留的1.4.2版本的a life of logstash event链接已经失效,目前最新的 ELK 文档里对logstash pipeline的描述改成了这样:
inputs -> filters -> outputs
.和->是最常见的两种调用方法的意符。感觉 ELK 全线走向method chaining风格的节奏啊~



