上一篇文章里,我试图论证了一个观点:在日志分析场景下的DSL设计,宜采用数据管道风格。
不过,并不是所有时候,数据分析的流程都是单向的一条线。
下图是阿里云PAI平台文档中的一个示例截图:
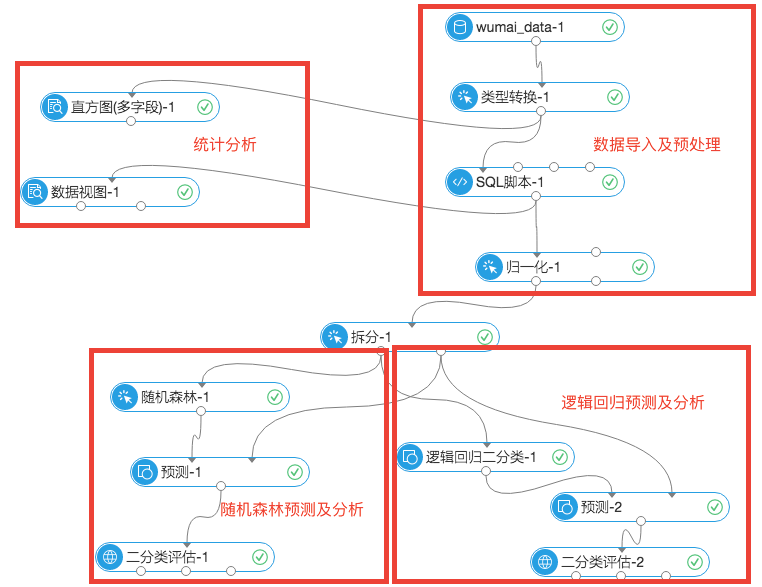
这是一个做机器学习时非常常见的流程图。虽然我们一般说法中,也是下面这种单向的:
数据导入 -> 数据预处理 -> 特征工程 -> 模型调整 -> 效果评估
但是在预处理和特征工程的时候,少不了需要通过统计分析手段来决定一些调整方案;在效果评估和模型选择的时候,也是需要同时运行不同模型来相互参照。
最终就变成了一个图而非线性的流程了。
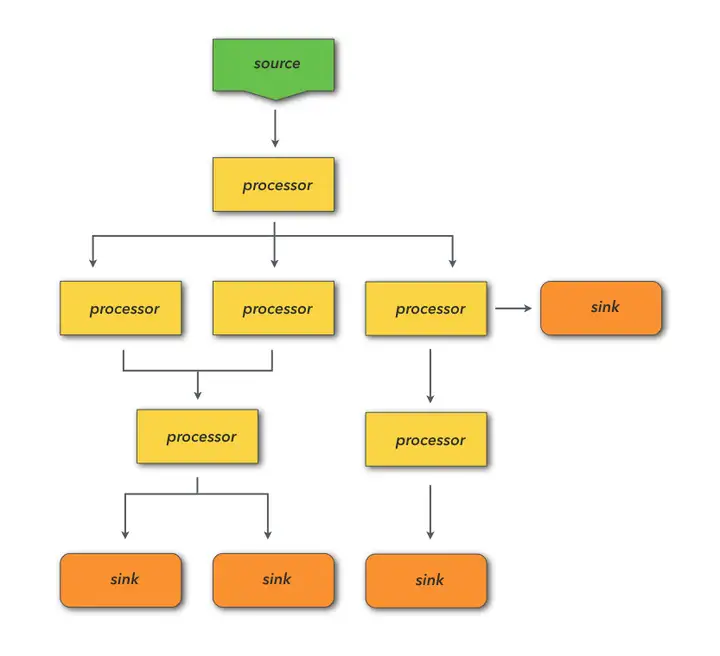
当然,并不是说用线性管道就达不到相同目的了——我们可以通过子查询的形式达到最终一致的结果。但是这个过程意味着一部分流程的计算是重复运行的。在普通的搜索统计时,这个无所谓。第一消耗可能不大,第二诸如Elasticsearch等后台引擎对一模一样的query是有query cache的,所以子查询的搜索聚合结果,在主查询的时候其实是复用的。
但是在机器学习的时候,问题可能就严重一些了。因为这些可能消耗的资源不少,运行时间也不短,每次都从头开始确乎就是一种浪费了。所以有必要在DSL语法上,想到一种更合适的结构。(像阿里云等平台这样搞可视化拖动当然也行,但是对智能运维产品本身设计不一致)
这时候,我想起来年初的时候,在devopsweekly邮件上看到过的一个开源项目,名叫dgsh。地址见:https://www.dmst.aueb.gr/dds/sw/dgsh/。
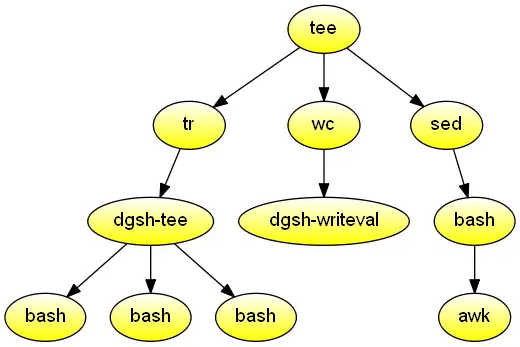
dgsh的写法示例如下:
#!/usr/bin/env dgsh
tee |
\{\{
printf 'File type:\t'
file -
printf 'Original size:\t'
wc -c
printf 'xz:\t\t'
xz -c | wc -c
printf 'bzip2:\t\t'
bzip2 -c | wc -c
printf 'gzip:\t\t'
gzip -c | wc -c
}} |
cat
看起来就是我们想说的这个意思。不过在语法设计上,靠空行来切分并行任务,还是有点怪怪的。
此外,去年曾经还有一个项目,在做竞品调研的时候闯进过我的眼界:Juttle。这是Jut.io开源的项目,jut.io曾经入选过2015年的Gartner ITOA Cool Vendor名单,不过2016年就倒闭了,关门前把这个系统开源出来……
read elastic -from :2015-01-01: -to :2015-07-01:
category = cat_in AND type ~ '*${type_in}*'
|(
reduce count()
| view tile -title 'GitHub events count (${cat_in}, ${type_in})' -row 0 -col 0;
reduce count() by repo_name
| sort count -desc
| head 10
| view table -title 'GitHub events for top 10 repos (${cat_in}, ${type_in})' -row 0 -col 1;
reduce -from :2015-01-01: -over :w: -every :d: count() by repo_name
| view timechart -keyField 'repo_name' -title 'Rolling count of GitHub events (${cat_in}, ${type_in})' -row 1 -col 0;
)
这里采用了分号;来区分并行任务。显然比单纯的空行好看且明确一些。不过使用圆括号()来作为并行任务的区域表达,又有另一种误解,因为加减乘除运算是使用圆括号来表达优先级的。
所以综合来看,采用花括号\{\{}}配合分号;可能是最好的结构了。那么文首的那个机器学习流程可以表达成这样:
wumai_data_1
| eval feature_XXX = somecommand(xxx)
| \{\{
bucket feature_XXX span=1000 as numberrange
| chart numberrange over other yyy,zzz;
fit StandardScaler *
| sample ratio=0.2
| \{\{
fit RandomForestClassifier predict_field from feature_* into rf_model
| apply rf_model
| `confusionmatrix("predict_field","predicted(predict_field)")`;
fit LogisticRegression predict_field from feature_* into lg_model
| apply lg_model
| `confusionmatrix("predict_field","predicted(predict_field)")`;
}}
}}
看起来还不错呢~哼哼,看我这个思路后续会跟其他竞品雷同不~



