时隔一年没有更新,日志的模式发现,已经变成了大大小小各家厂商的标配功能。前几天看到阿里云日志服务,也刚刚支持了相关特性。而且从系统设计层面来说,有些想法蛮不错的,这里给大家介绍一下。
功能的主要说明,来自阿里云官方文档:https://help.aliyun.com/document_detail/100039.html
从文档中,可以看到阿里云日志聚类相比之前介绍的一些厂家实现,有两个特点:
- 针对的数据类型:文档上明确说「支持log4j和json」格式。
- 开启聚类功能占用磁盘:文档明确说「增加原始日志大小的10%」。
数据类型问题
实时上,我们看之前的各家产品截图也好,看很多本领域的科研论文也好,一般采用的日志,都是这么几类:
- 网络设备、主机操作系统的syslog日志;
- hadoop、openstack等分布式系统日志;
- nginx、weblogic等访问日志。
相比这几种日志,log4j会有很多多行事件,而json日志则很容易出现语序变动的情况。
比如说:
{"num":123,"str":"abc"}
和
{"str":"abc","num":123}
这么两行json日志,我们一看就知道他们其实是一模一样的内容。但对于采用文本距离来聚类的算法来说,这两行的差别就非常大了。
所以由此可以判断,阿里云日志聚类,应该采用的不是文本距离(edit distances,已知有logmine、logsig、spell等)的方法。那么,可能就是通过频繁模式挖掘(frequent pattern mining)了。可以参见裴丹教授的FT-tree论文。
目前来说,我个人只看过这么两个大思路。
磁盘占用问题
在之前各种介绍中,大家的使用方法基本一致,都是基于某次搜索的结果,进行聚类或者模式发现。
阿里云日志服务是唯一一个,要求提前在索引配置上,设定该索引开启聚类分析,然后才能使用的:
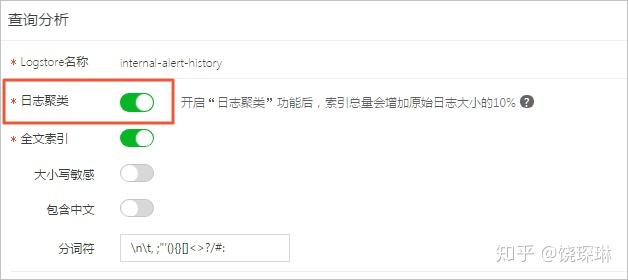
也就是说,阿里云是在日志索引入库流程中,就完成对日志的模式计算,并直接存储下来。
此外,文档中还有一段SPL语句,用来实现sumologic中的logcompare命令功能:
* | select
v.signature,
v.pattern,
coalesce(v.cmp[1],0) as count_now,
coalesce(v.cmp[2],0) as count_before,
coalesce(v.cmp[1],0) - coalesce(v.cmp[2],0) as count_diff
from (
select
p.signature as signature ,
arbitrary(p.pattern) as pattern ,
compare(p.count,300) as cmp
from
(select log_reduce() as p from log) group by p.signature
)v order by count_diff desc
可以看到同时存在signature和pattern两个不同的输出。
在多数地方,signature=pattern=log_key≈cluster。所以这又是一奇。
在NEC美国实验室与蚂蚁金服合作的LogLens论文中,正好有log-signature和pattern-group的区别。简单的说,比如下面这行原始日志:
2016/02/23 09:00:31.000 127.0.0.1 login user1
它的log-signature是可以流式处理得到的,是:
DATETIME IP WORD NOTSPACE
它的pattern则取决于实际的聚类结果,比如可能是
2016// ::** 127.0.0.1 * *
也可能是
2016/02/* ::* * login *
所以,多出来的10%存储,应该分为两部分:一部分是和每条日志的索引一起,单独出来的一个log-signature字段,里面是几个常见的Grok正则定义,压缩比应该蛮高的;另一部分,是定时或者半实时生成的pattern树;最后是这二者的映射关系表。后两部分应该是额外存储的,总量应该不大。
由于没有阿里云账号,无法实际通过SPL运行来验证signature和pattern的输出到底是什么样子。本次实现推测,只能到此为止了。
btw:LogLens论文中还有关于多行日志的行为模式检测的一些内容,请大家自行阅读咯~~



