作为运维人员,大家可能已经习惯了出问题的时候,找日志,看日志,或者打包日志发给研发。那么,大家有没有想过,在软件研发人员的角度,可以怎么理解日志的作用呢——尤其是目前研发人员主导监控埋点,指标监控似乎也要亲研发远运维的情况下,日志系统的未来会是什么样子呢?
最近看到一篇发表在2016年《软件学报》上的综述文章,来自国防科技大学计算机学院李珊珊博士,名叫《大规模软件系统日志研究综述》。今天推荐给大家一读: http://www.jos.org.cn/1000-9825/4936.htm
文章从三个方面做了综述,分别是:
- 日志特征分析
- 基于日志的故障诊断
- 日志的增强
日志特征分析部分
这部分,分别引用了2012-2014年国际会议的三篇不同论文,其中一些分析结论在我看来是很有度量意义的,摘录出来,供大家自我评审参考:
- 在软件开发中进行日志记录是普遍的,平均 30 行代码中就有一行是日志
- 日志信息对实际部署系统的运行故障调试帮助较大,缩短故障调试时间的加速比为 2.2
- 日志代码的更新频率比其他代码要快约 1 倍
- 约四分之一的日志修改是把新的程序变量写入日志
- 约一半的日志修改是对日志消息静态文本的修改
基于日志的故障诊断部分
这部分也是业界最热点的部分,因为它直接和工作相关。在综述中,我们可以看到这部分技术的发展也是经历了明显的阶段:
第一阶段,大概是十多年前,将某种单一类型的日志,视为时间序列,与故障的发生做关联。
第二阶段,由现清华大学的徐崴教授开始,当时他应该是在伯克利和谷歌工作,突破点主要是:日志量更大更复杂;离线转在线分析;挖掘的是状态图变化——事实上徐崴教授回国后也在公开场合做过少量AIOps演讲,我印象中有百度机房的磁盘故障分析、openstack集群的故障定位等等。
第二阶段的另一条分支,其实也是目前日志分析的主流,由LogSig为代表,通过算法,将日志文本分为「签名」和「参数」两部分。然后在这个思路基础上,大家开始五花八门的分类或聚类,以及五花八门的工作流关联挖掘——由于综述是16年写的,偏偏AIOps在16年之后爆发,所以之后两年清华大学裴丹教授的FT-tree、犹他大学李飞飞教授的DeepLog/Spell、港中文郑子彬教授的Drain、南京邮电李涛教授的FLAP等都不在综述里。
此外,还有一些研究把日志分析技术,和源代码静态分析技术结合起来,以获取更好的结果。这里就不细说了。
有趣的是最后一段基于日志的检测算法效果评价部分。主要是通过给程序源码注入失效代码的方式来产生数据。相关文献主要结论如下:
- 即使都有log level结构的不同类型日志,在不同系统架构、执行环境上的差异,也会导致日志检测算法效果的巨大波动;
- 在web应用环境中,资源枯竭和程序异常比较容易检测,而应用相关的则难以应对;
- 即使著名如apache和MySQL,也只有35.6%-42.1%的错误有日志记录。
综述还按照针对的日志类型做了一个研究统计表,也可以发现,确实针对应用/中间件日志的研究很少:
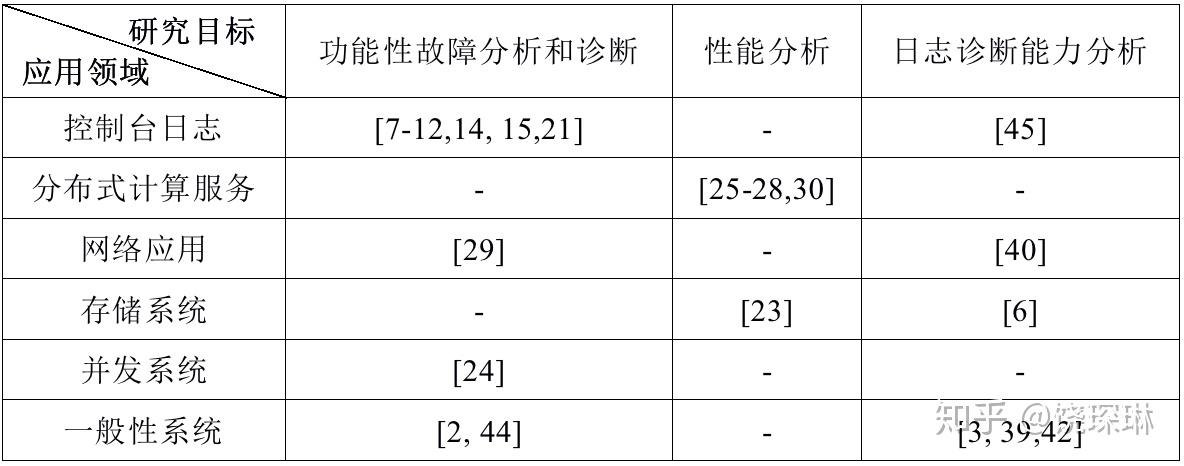
日志的增强部分
通过上面两部分的分析,可以得到一个结论:有日志以后能做什么,其实是比较清晰的,最多是算法还不够通用化而已。但更麻烦的是没有日志。所以引出了第三部分:怎么帮研发人员在编程过程中识别哪里该加日志,日志该记什么,也就是日志的增强部分。
这两个问题,分别以多伦多大学袁丁教授的Errlog和LogEnhancer论文为代表。综述中并没有涉及太多,毕竟方向比前两个更新一些。2012年的时候,袁丁还是周媛媛教授的学生——有兴趣的可以把周教授及弟子们的成果都翻翻,他们专攻软件可靠性,包括综述里提到我这没摘录的lprof和SherLog也是他们做的——在2017年,袁丁又指导自己的学生发表了Log20,算是Errlog的升级版。
这一部分综述几乎除了袁丁教授的成果就没怎么提其他的,不过本文自己也补充了一些这方面的调研结果(应该就是他们团队自己的SmartLog摘要),在第3节,这里就不细说了。
综述最后,也提出了后续的一些研究方向:
- 日志的评价打分标准和工具欠缺——这块也是我最近参加信通院AIOps标准工作组讨论会时发现的问题:不像指标异常检测那么清晰,日志检测算法好不好,很难评价。
- 日志的上下文分析,在关联模式以外需要辅以语义分析——可能同一个函数,在某些高性能场景下就不方便打日志。
- 日志的增强方面,还比较重规则,不够智能化——类似与看到create和connect函数下面都应该log这样,太粗糙了。
- 多事件日志与故障的关联方面,实践不足——事实上,我觉得这事最难的是如何确定当前收集的日志足够覆盖和故障相关的所有事件呢?



