云原生日志的趋势(1):logscape和logiq
作为日志产品的PM,跟进国内外日志产品动向是个长期工作。这几天翻新一些历史记录,发现logscape自2017年开源以来,突然2019年10月又更新了一会。于是顺着翻翻logscape的github账号,起了兴致来写点文字。
logscape
先聊logscape这个产品吧,从源码里可以大致看出:这是一个不基于elasticsearch的日志分析产品,而是基于linkedin老早之前开源的一个叫krati的KV存储上做的。
从logscape自己的文档来看,性能部分表现不算很好:
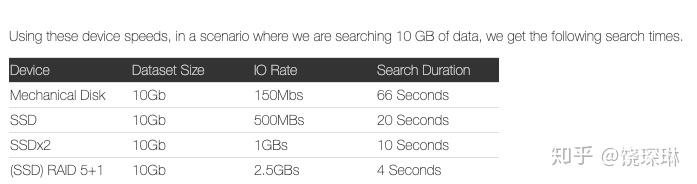
但是在资源控制上做的还蛮细:

此外,几乎各种功能都有:
- 告警插件:groovy和js支持
- 日志分组:基于日志源的组合和额外的host过滤
- 多租户支持:不过是知识级别,不是数据级别
- 字段字段发现:主要是kv和grok两种,kv和splunk一样其实也包括json,按照文档所说,自动kv的每个模式20MB/s,grok的每个模式14MB/s。但是注意:logscape其实还是事先提取,自动发现的字段是会做flatfile存储的。
- 数据概要:可以创建新字段,包括stats和eval,并且设置为summary。也可以直接通过summary.index(write)指令手动或定期生成。
但是,logscape这个莫名其妙的SPL设计简直反人类啊:
首先,它模仿了一段lucene的querystring全文搜索,然后对字段值又要单独采用Obj.
cpu | cpu.max(_host,1h) _host.equals(LAB-UK-XS-UB1) offset(1h) chart(line)
([A-Za-z\.]+)Exception | 1.count() _host.equals(LAB-UK-XS-UB1)
* | _type.contains(UNX) _type.equals(unx-ps) usedMB.avg(server,UsedKB) RSZ_MB.avg(server,rszKB) eval(EACH * 1024) chart(table) buckets(1)
* | _type.equals(UNX-cpu) CpuUtilPct.avg(server,AvgCpu) +AvgCpu.eval(CpuUtilPct > 10) chart(cluster) buckets(6)
Agent and cpu | cpu.max(_host,POST) +POST.max(,Max) +POST.min(,Min) +POST.avg(,Avg) chart (c3.area)
* | _type.equals(log4j) package+level.count(,PackageLevel) level.not(INFO) chart(line)
谁能单从语法上看懂这是要干嘛……
总结一下:logscape最大的问题:底层引擎性能不给力,顶层DSL设计乱糟糟。白瞎了中间层细致的管理功能。
logiq
然后顺着logscape的github账号,发现难怪他们开源以后就没咋更新呢,原来后来又做了一版NG(liquidlabsio/logscape-ng),叫serverless and opensource log aggregation,并很快又放弃掉改成了一个更加serverless的项目,这次名字叫fluidity:https://github.com/liquidlabsio/fluidity
这次,这个项目的设计目标,是单纯利用amazon S3和lambda来实现长期存储和即时计算!
由于项目还很初期,所以就不看他们源码实现了。但是这个让我想到前几天,同样在CNCF landscape上看到的另一个产品:LOGIQ Observability for monitoring, logs, and predictable pricing。
这个产品,直接提供helm-chart和amazon cloudFormation template文件供运行启动。如果是本地helm-chart,日志存储在开源对象存储minio里;如果是cloudFormation template,日志存储在amazon的S3对象存储里。
然后,logiq产品本身,除了日志查看页面,也就还提供一个命令行的logiqctl,进行日志的query和tail。
可以说,二者非常相像,都是放弃自己对数据存储引擎的构建,彻底交给云平台,交给S3——因为,S3太便宜啦!



