日志管理领域研究现状(三)
去年看过一篇 2016 年国防科大的日志管理综述,这几天看到 2020 年北京大学贾统也发了一篇综述:《基于日志数据的分布式软件系统故障诊断综述》。综述集中在分布式系统的日志如何在故障相关话题中发挥作用。
注意:这里只包括分布式系统,不包括业务日志、网络日志、操作系统日志。综述把分布式系统日志分为两大类:第一叫事务性日志,也就是和请求相关的、工作序列式的。第二叫操作性日志,就是单条日志足以描述完毕的。
技术话题主要包括四个部分:
- 日志处理与特征提取技术、
- 基于日志数据的异常检测技术、
- 基于日志数据的故障预测技术、
- 基于日志数据的故障根因诊断技术。
日志处理
主要就是模板挖掘。分为:基于频繁项集和基于聚类两类。(基于静态分析的我们厂商就不用想了)优缺点对比见下表:
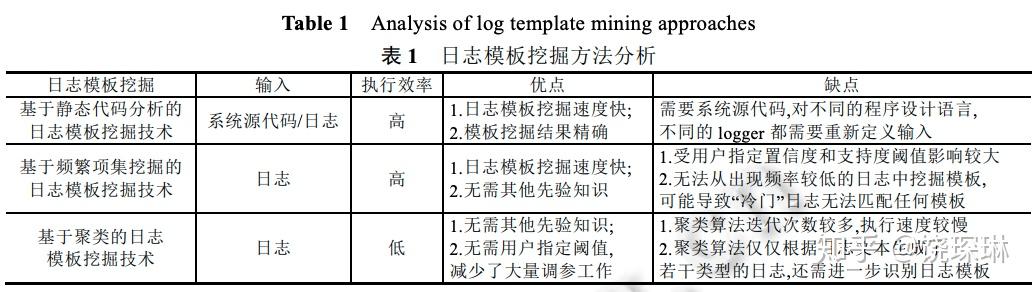
就国内而言,裴老师的 FT-tree 就属于基于频繁项集,日志易等属于基于聚类。
特征提取
主要是如何把日志转换成可检测的特征。分为:基于 NLP 的、基于 ETL 规则的(这个没啥 AI 可言)、基于指标的。
从综述统计来看,研究论文里大多数都是基于 NLP 的,可以说 word2vec+LSTM 遍地跑。
但是在行业实践来看,基本上都是基于指标的。毕竟单指标异常检测是 aiops 领域最成熟的部分,把日志特征通过模式事件数的方式转换成指标异常检测,可以说是非常容易的路径。
只有 loomsystems(今年初刚被 serviceNow 收购)和日志易,不光做了模式特征提取,还做了参数特征提取和基于参数的异常检测。
日志异常检测
分为:基于图模型的、基于概率分析的、基于机器学习的。
基于图的主要针对事务性日志。利用事务序列构建有向图是最常见的做法。
文中也提到比较新奇的,利用标识符(高频词、代码类名称等特定词)在不同节点不同时序下的entropy分布、或 pagerank 等,生成的图。
基于概率分析的主要其实就是上面一节说的日志模式特征转换成指标异常检测。
文中也提到另一种基于概率分析的对事务性日志的方法。就是一个序列模式内不同子序列的时序指标相关性,如果有变动,也可以认为是异常。国外有一家叫做 coralogix 的公司,按我个人理解就是走的这个思路。
基于机器学习的就是上面一节说的不光模式特征,还加上参数特征。当然这块研究方面比我们厂商走的更前沿一些。文中提到的方案是:因为日志模式参数可能比较多,对训练数据采用 PCA 降维识别关键参数,然后将模式的时序指标和这些关键参数的频数分布进行关联映射。从思路上来说,感觉是个不错的想法。因为模式挖掘,尤其是基于聚类的模式挖掘,确实不方便了解应该针对哪些参数进行提取和检测。
日志故障预测
这块我觉得还处于比较浅显的阶段,故障的定义就是狭义的日志中出现 Error、Fatal 关键字。然后根据这行 Error 日志之前一段时间的日志进行回归啊,NLP 啊之类的预测。我个人以为,在实际需求中,这种关键字故障大多不会是可重复发生的——因为每次故障之后都有修复措施啊。
日志故障诊断
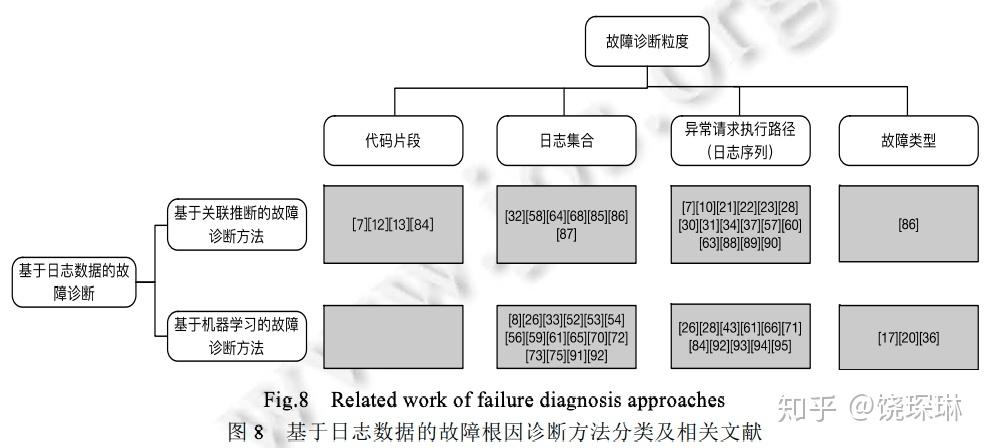
包括基于关联推断的和机器学习的两类。诊断粒度主要是:代码片段(厂商还是不用想这个)、日志集合、日志序列、预置类型——这可能跟目前主流的基于基础监控指标和调用链数据的故障诊断有很大区别,因为后者的诊断粒度基本都落实在主机实例上的性能指标上,比如最近刚结束的裴教授和浙江移动办的第三届 aiops 大赛。
已有的研究论文分布如下图所示:
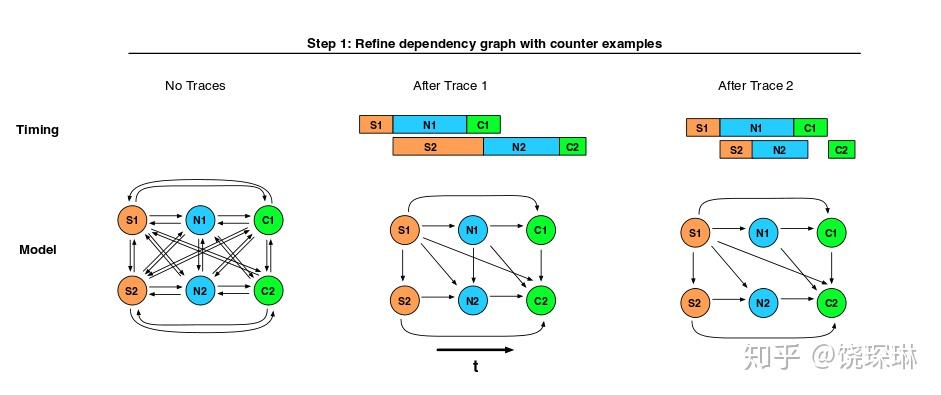
基于关联推断的日志序列诊断研究,最有名的应该就是 facebook 的 The Mystery Machine——和 google 的 dapper 不同,也就是说和目前主流的 zipkin/opentracing 不同,facebook 认为不是所有的公司都可以有统一的基础架构中间件框架可注入(我们都知道 facebook 前端是 php,哈哈),所以基于最小公共参数(只包括请求 id、主机 ip、主机本地 timestamp 和事件tags)的日志改造实现端到端的应用分析才更通用。当然纯基于本地日志的推断,就需要TMM进行时间戳补偿对齐,然后基于中心补偿的情况进行不同段之间的时间先后关系推断和剪枝(因为是剪枝法,所以 TMM 有个假设就是我的所有业务都肯定有大量请求,足以覆盖各种情况),得到关键路径,并用于异常检测和性能优化诊断。
这篇论文在著名的 morningpaper 博客也发过解析,这里我贴一个知乎上的解析:张明锋:The Mystery Machine:大规模互联网服务的端到端性能分析
另一个应该是北卡和 NEC 美国实验室的 CloudSeer,他们提出的额外问题是很多日志不是一定会准确记录请求 id、线程 id、进程 id,所以并发请求的日志是交叉打印的。解决办法其实也没啥特殊的,就是维持一个 id set(这里的 id 是广义的,各种模式参数全算),新日志的 id 集合和之前哪个 set 里的 id 集合最接近,就属于哪个——这属于没办法之下的举措,日志易的 transactionize 指令在华东某客户那块其实也是这个思路。
基于机器学习的日志序列诊断研究
最有名的就是 deeplog,网上也是有很多解析了,这里也贴一个知乎上的:SEU-AI蜗牛车:【异常检测第一篇】异常检测与诊断模型之DeepLog
总体来说呢,在日志的故障诊断方面,目前其实比较好的研究也就是这么几个。而且也都没流行开,主要问题还是数据不充分——而数据一旦充分了,我直接 opentracing 不香么~



