ChatGPT 火热的情况,感觉好像强 AI 近在眼前。但实际上,ChatGPT 代表的 LLM 重点只是在文本生成。还有大量的其他场景,其实也有算法在飞速进步。比如 stable-diffusion 实现的 text2img,比如 text2song,还有 openai 新出的 Point·E 做 text to 3D 等等。
不过这些也还都是单个任务。有没有想过把这些原子能力,串联起来,会是什么形态?
今天有群友突然问到一个场景,就体现了串联能力的需求:
“有个 PPT 制作的问题,特别想截图问问怎么办,因为纯靠语言没法描述。比如:这个地方和这个地方怎么对不齐啊?”
这其实就是一个多模态的内容理解和生成。我们把过程拆解一下:
- 要从截图中识别出来这是一个 PPT,并且其中有若干个挂件
- 要从问题文本中理解出来问的是两个挂件和对齐
- 要把两个模态的信息关联起来:问的是截图里 PPT 的哪两个挂件的对齐
- 从 PPT 知识中推理出最终回答
这里第一步是 CV,第二步是 NLP,第四步是 LLM,只要第三步能合理的生成 LLM 的 prompt,就可以构建出完整的多模态能力。
正好,就在最近,salesforce 公司发布了 BLIP2,在这方面做了尝试。不是算法研究员,这里就不做论文解读了。直接上 huggingface demo 体验:https://huggingface.co/spaces/Salesforce/BLIP2
我先复现一下群友的场景,让他判断 PPT 里两个表格是否对齐,怎么对齐:
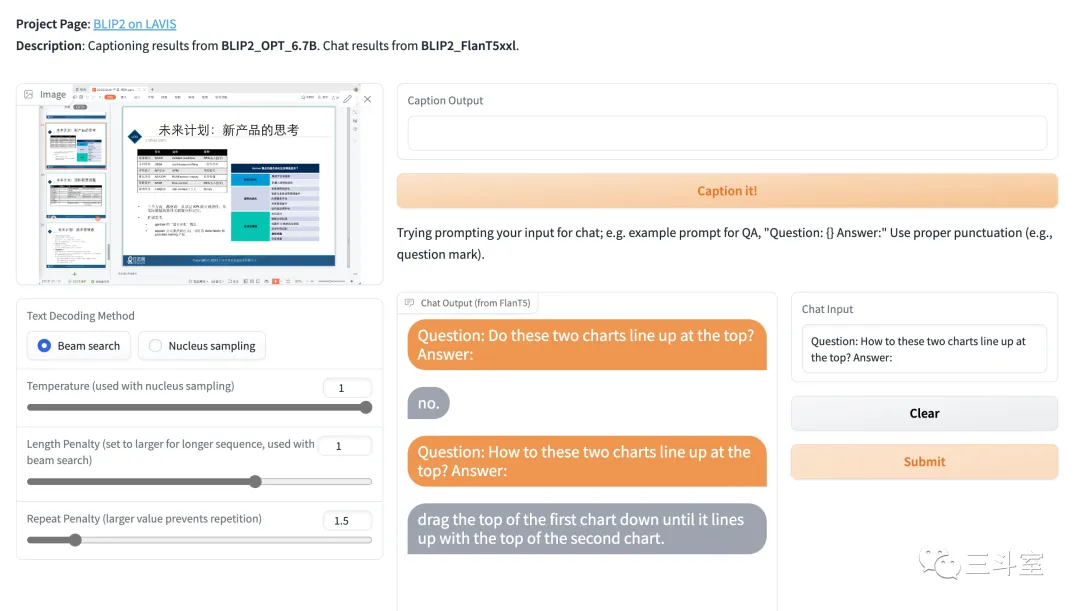
判断无误,并建议我把左边第一个表格往下移。
然后再实验一个更难的场景。一张著名的视觉欺骗的静态图片,问问他上面到底有多少个圆点:
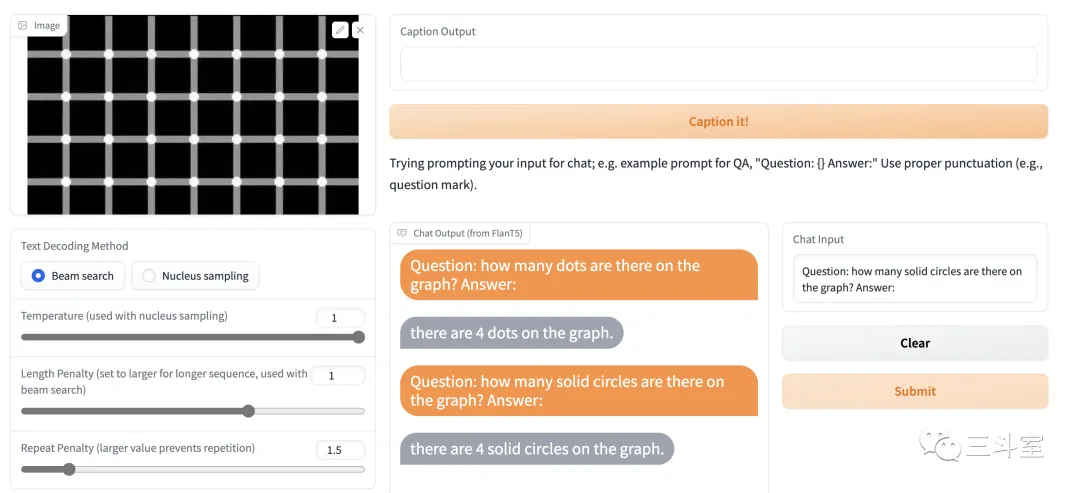
两次都回答说:4 个。
可以看出,PPT 截图问答已经基本能理解问题并给出合理回答了,至于是不是最佳回答,见仁见智——没准未来还能第四步的 LLM 改为生成新的 prompt,通过第五步 text2img 直接生成演示图,大家你来我往,斗图交流~
视觉欺骗的圆点数量,给出的回答还不是很满意。不过至少这个斩钉截铁的自信样子,还是很像 ChatGPT 的。[大笑~]
隔几天就有新突破的 AIGC 新时代~真是让人眼界大开。



