很多人都说,一切软件都应该用大模型重构一遍。这几个月,我也在探索类似的话题:运维软件,应该怎么用大模型来“重构”一遍呢?
昨天在公司内部做了一次分享,这里隐藏掉一些内部进展,把收集到的行业公开信息,以及我个人的评价,一一贴出来。供大家参考。
一、科普:大模型知识的必读必会
- 大模型,全称是大语言模型。因此它只有文本处理能力——不要想着让大模型做指标监控。
- 大模型的运行效率很低。一张 A100 显卡上运行 ChatGLM-6B 的推理速度是每秒钟大概二三十个字/词——不要想着让大模型直接清洗海量日志。
- 读一下之前这篇《能不能用ChatGPT的判断原则》,第三条“easily verified”对正则表达式来说,很难、很绝望——不要想着让大模型给你生成正则。
- 大模型的对话长度有限,多数开源模型都是 2k。外挂向量搜索的效果完全取决于你的搜索优化技巧——目前没多少人熟悉这个技巧,可能还不如直接用 elasticsearch。
- 大模型训练分为预训练和微调训练两种。业界普遍认为:“知识”只有预训练过程能增加,微调训练只是调整“知识”输出的形态。
- 预训练的格式就是一行一行纯文本,表格可以用 markdown 文本表达——不要想着收集一堆贴满图片的Word/PPT就可以训练了。
- 微调训练的格式是一问一答纯文本,问题不要太简略和雷同。
- 大模型训练有数据质量要求,但还没有明确的方法论,截止到目前:
- 预训练数据至少需要 2GB 以上纯文本。需要混合私域数据和通用数据,比例大概是1:5到1:10。也就是说单个领域内的纯文本数据量应该在 400MB,换算成文字,应得有五亿个字/词。
- 微调训练数据说法不一,大的 MOSS 上百万条,小的 LIMA 只要 1000 条。同样需要混合私域问答和通用问答,比例大概更高,可以到1:1。需要精心设计不同场景的覆盖和占比,手工编写类似CoT的问答和混编多轮问答。
二、裴丹教授的 OpsLLM 四阶段论

裴丹教授是 AIOps 学界领袖,指标异常检测方面非常有名的 Donut 开源项目就是裴教授团队出品。裴教授在 6 月一次会议上,提出了大模型在运维领域落地的四阶段观点。如上图所示,后面 L3、L4 其实不用看,毕竟 GPT4 给我们画饼的多模态至今都还没见着呢。我们重点来看 L1 和 L2。
L1 其实就是说:我们相信会有一个很牛的 OpsLLM 运维大模型,因此我们只需要会prompt engineering,把大模型用起来就行。具体场景包括:让大模型做告警总结,工单推荐等。
L2 其实就是说:通过类似 langchain 框架开发的形式,在大模型之上,做 RetrievalQAChain、APIChain、Agent 等高阶功能。具体场景包括:让大模型生成查询分析语句、调用 API 操作、自主推理操作步骤等。
这里裴教授有几个假设,可能需要大家思考:
- 这个很牛的 OpsLLM 怎么来——业内谁有五亿个字/词以上的高质量运维语料?
- 靠 langchain 能应对更换模型问题么——大家可以看我之前一个对比《text to query语法调教场景对比 5 家大语言模型》,这可能不是程序开发问题。
问题先放在这,下一节,我们先来看看国内外运维安全产品,都用大模型做成什么了。
三、阶段一的 4 个例子
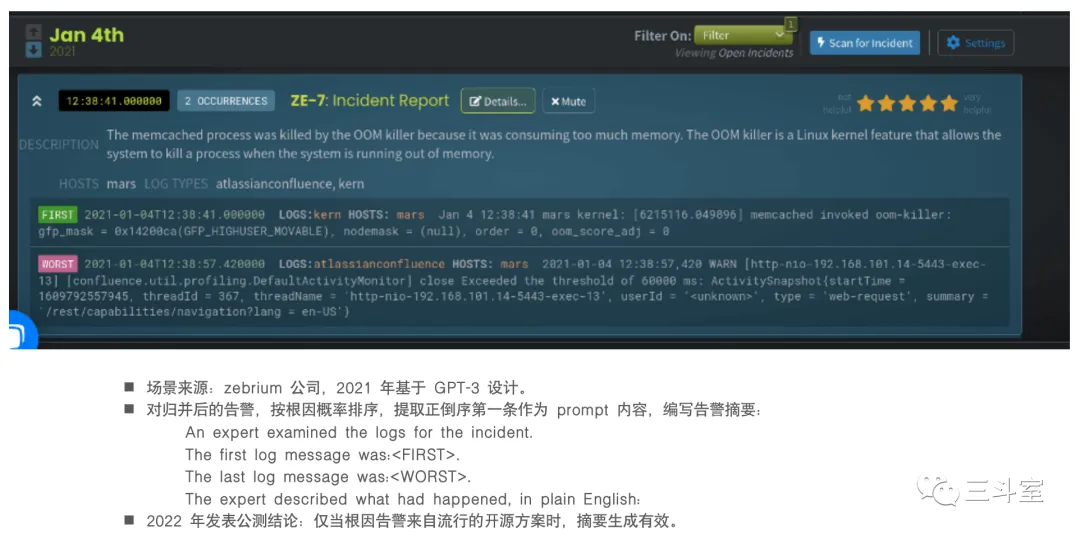
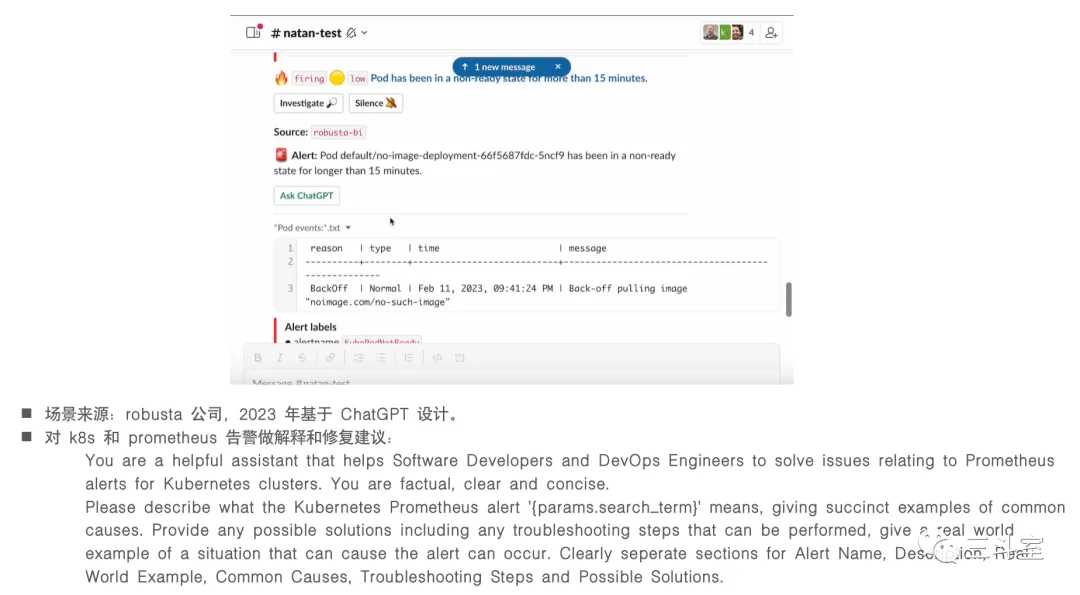
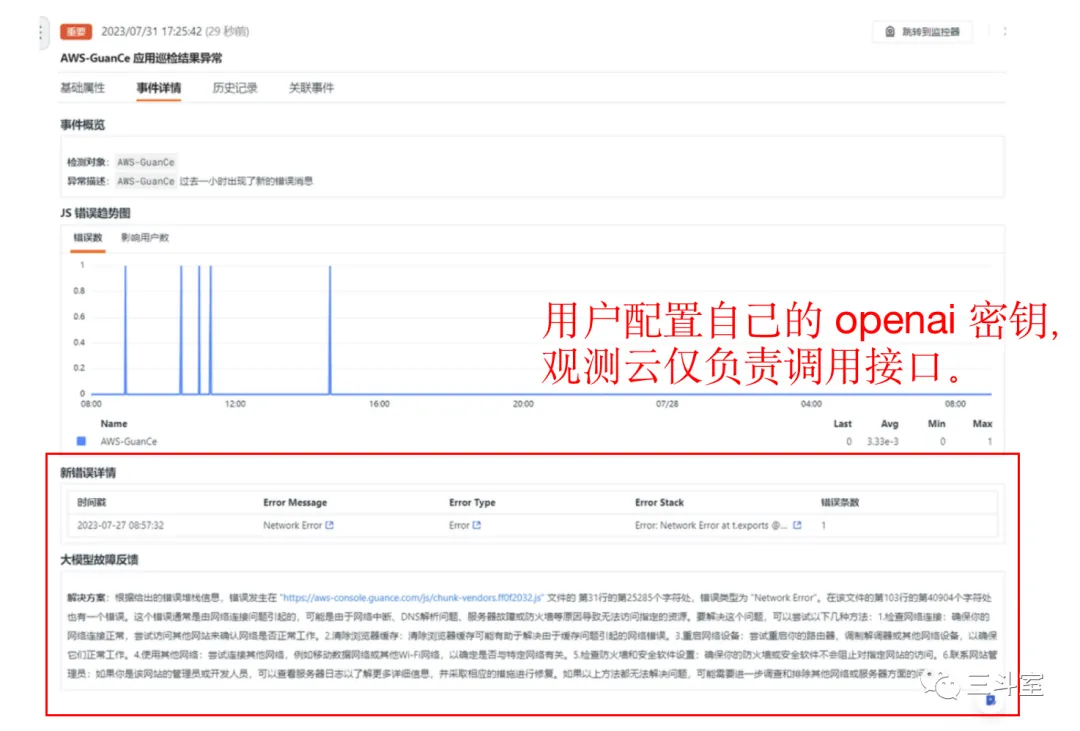
两个国外厂商,一个国内厂商,我个人都将其归入阶段一。特点也很明显:相信 ChatGPT 作为 OpsLLM 也很牛,“遇事不决,ask chatgpt”。
那么真的很牛么?这里有另一个例子,来自微软的研究报告:
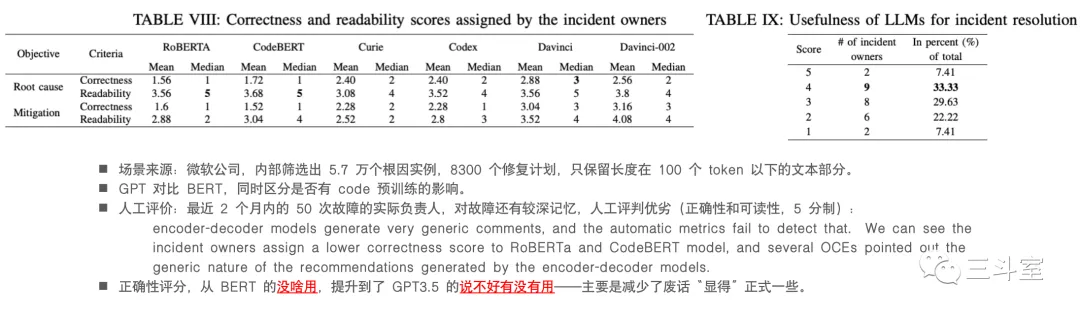
可以说,作为 OpsLLM,GPT 是比 Bert 牛不少了,但是还不够牛!
四、阶段二的 N 个例子
例子较多,我们按三个场景分别来讲。
4.1 查询语句生成
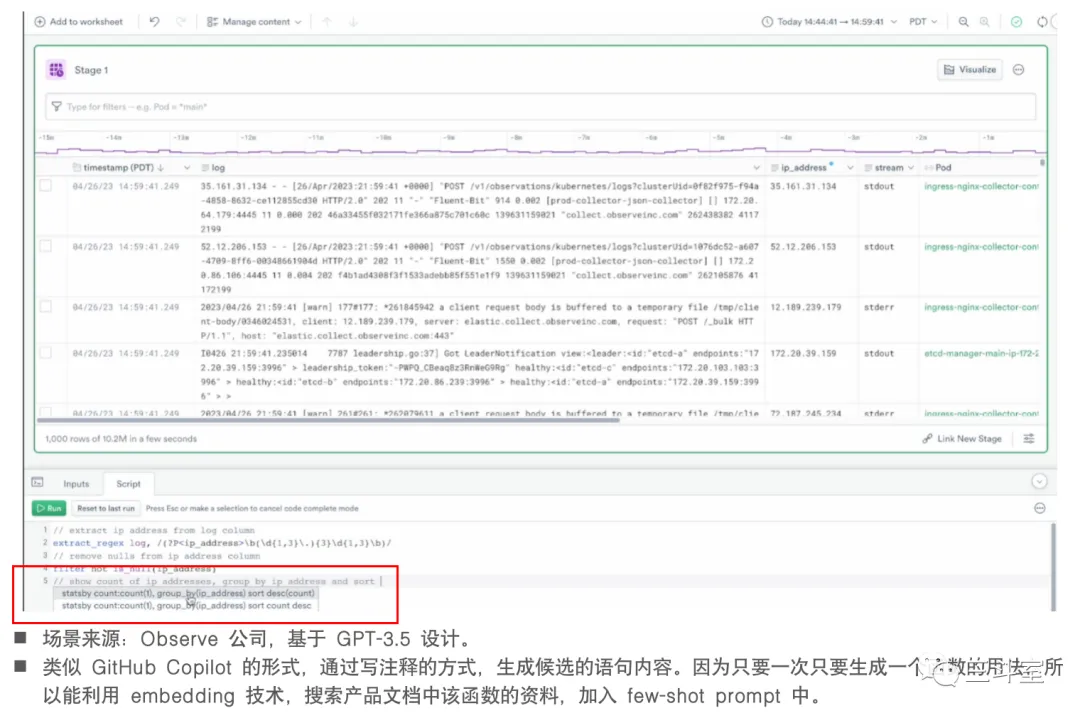
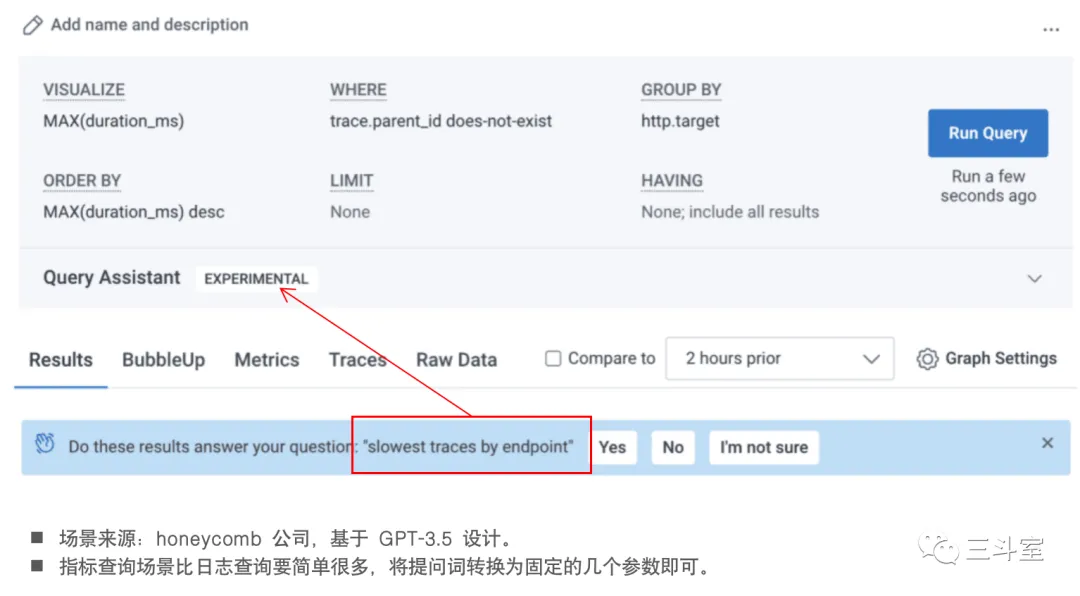
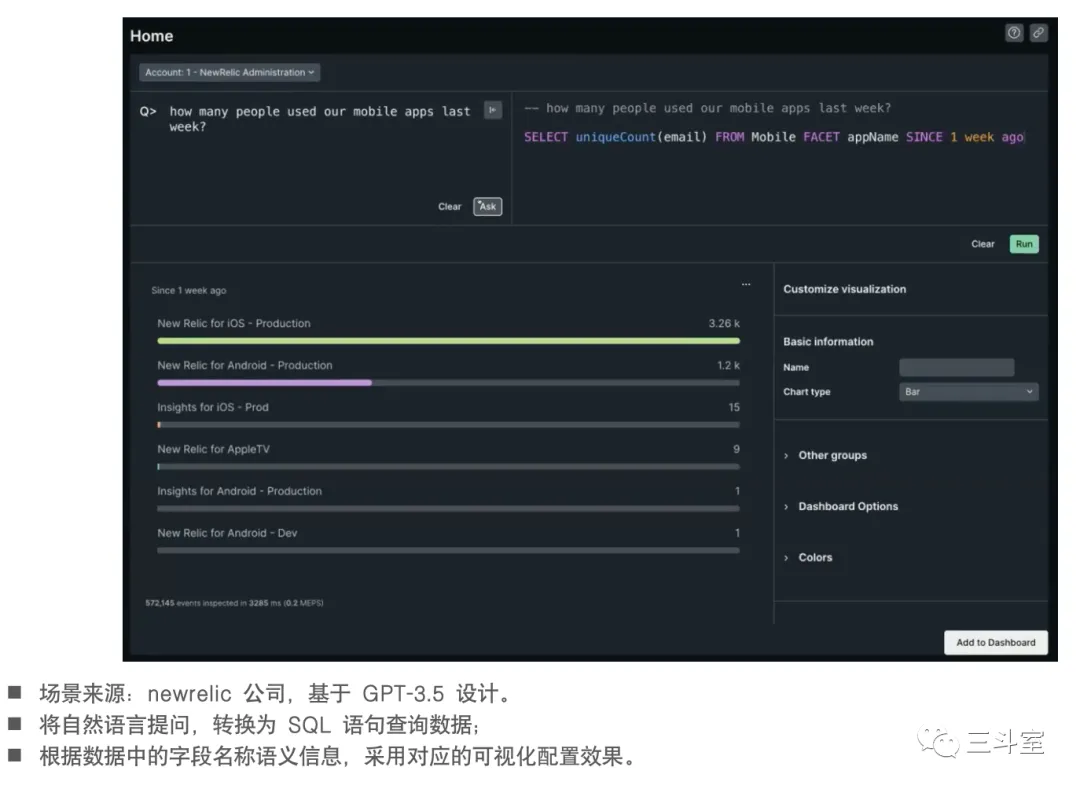
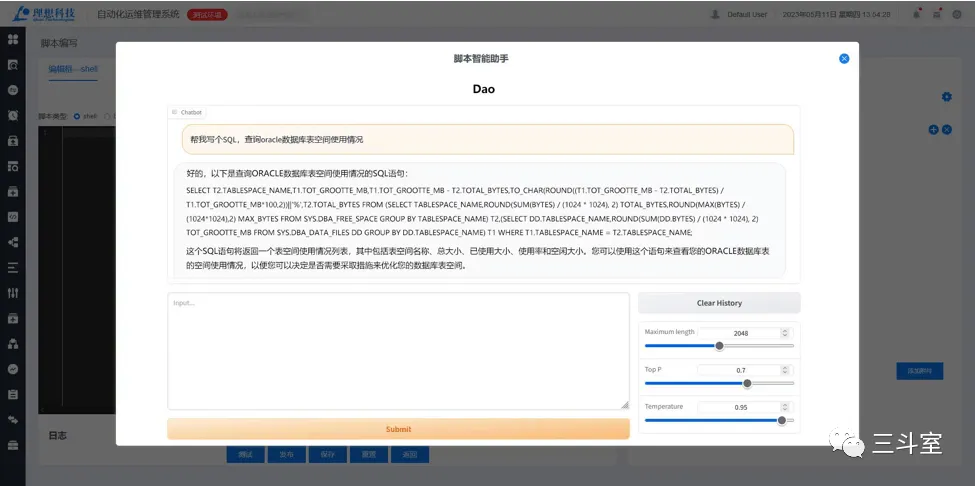
3 个国外厂商,1 个国内厂商的例子。可以看到各家实现的路径还是有挺大差异的。如果本身就是 SQL 查询,那直接 text to SQL 即可。如果是 metric 数据,查询逻辑非常简单,直接 text to Conf 填充菜单选项。如果是自定义语法,要生成完整且准确的语句就很难了,于是 observe 公司被迫引入 IDE 形式,每个函数都要单独提问,然后从产品文档中搜索对应函数的语法和示例小节,通过长达 4k 的 few-shot prompt 生成一个函数片段。
最后再提一下 splunk。日志分析领域的 SPL 查询语言,目前处于一个中间状态,它既不像 SQL 已经有很明确的标准规范,但又不至于像 observe 那样只有自己一家。ChatGPT 有一定的 text to SPL 能力。splunk 早年也自己独立尝试过基于 T5 模型训练。之前的介绍见《chatGPT初尝试(2): 自动生成 SPL 语句》。上个月,splunk 也发布了 beta 版本的 text to SPL:
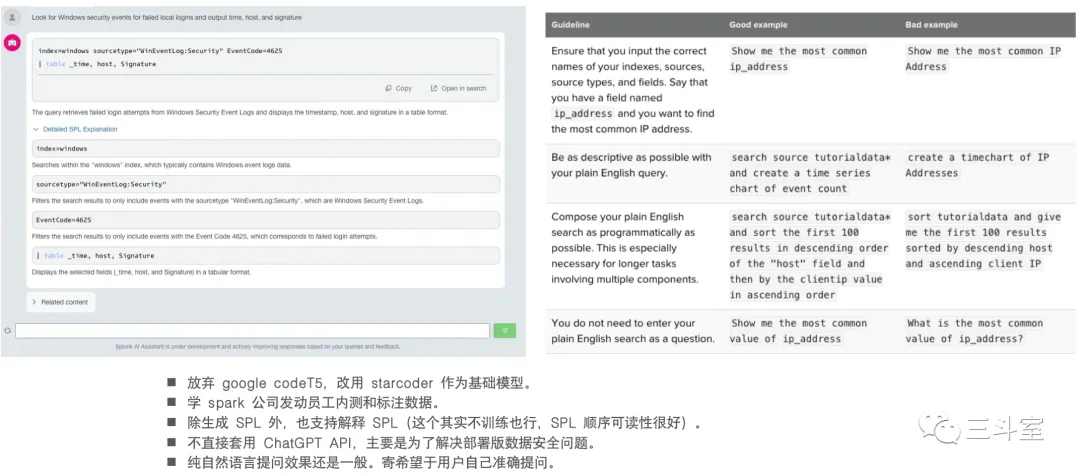
splunk 是目前国外的运维厂商中,唯一一个继续自研大模型,而不依赖 ChatGPT 服务的公司。大概因为 splunk 还有大量部署版客户吧~这点,也值得国内友商们参考。
上图右侧的表格,来自 splunk 使用文档。坦白说:所谓的 bad example,反而才是真实用户自然而然的提问——谁喜欢像 good example 那样按逻辑慢慢写大段引导词——因此,如何通过产品设计,避免、优化 bad example,让用户无感享受 LLM,值得 PM 琢磨。至少,splunk 目前这种独立 App 的方式,不是很好。
4.2 API 调用
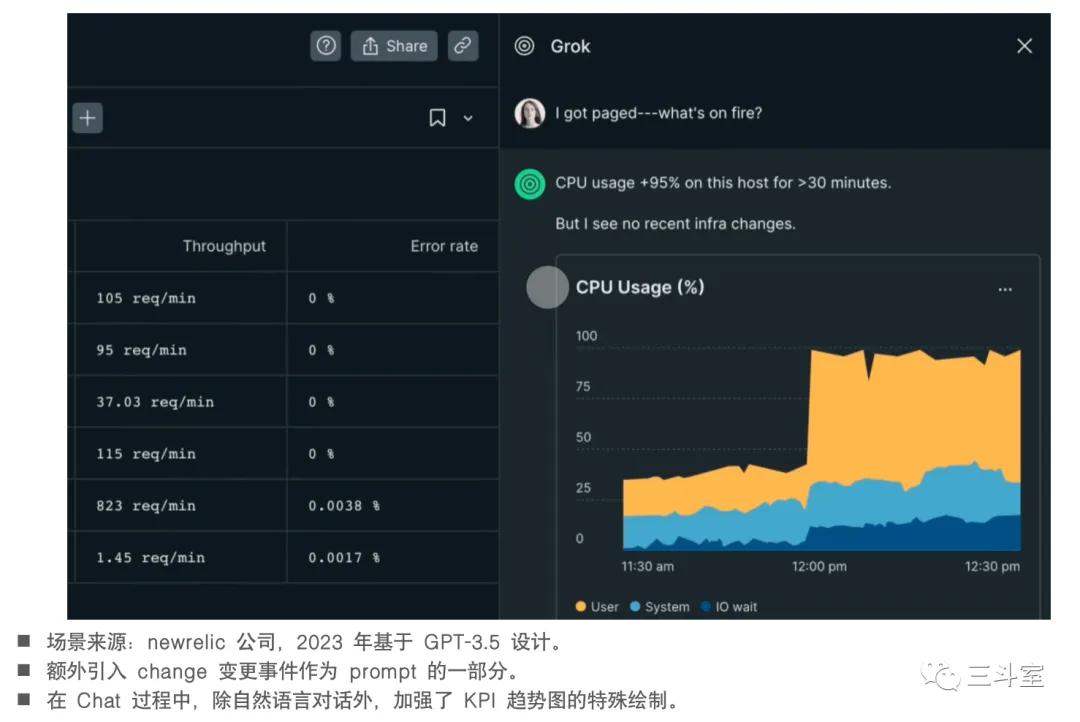
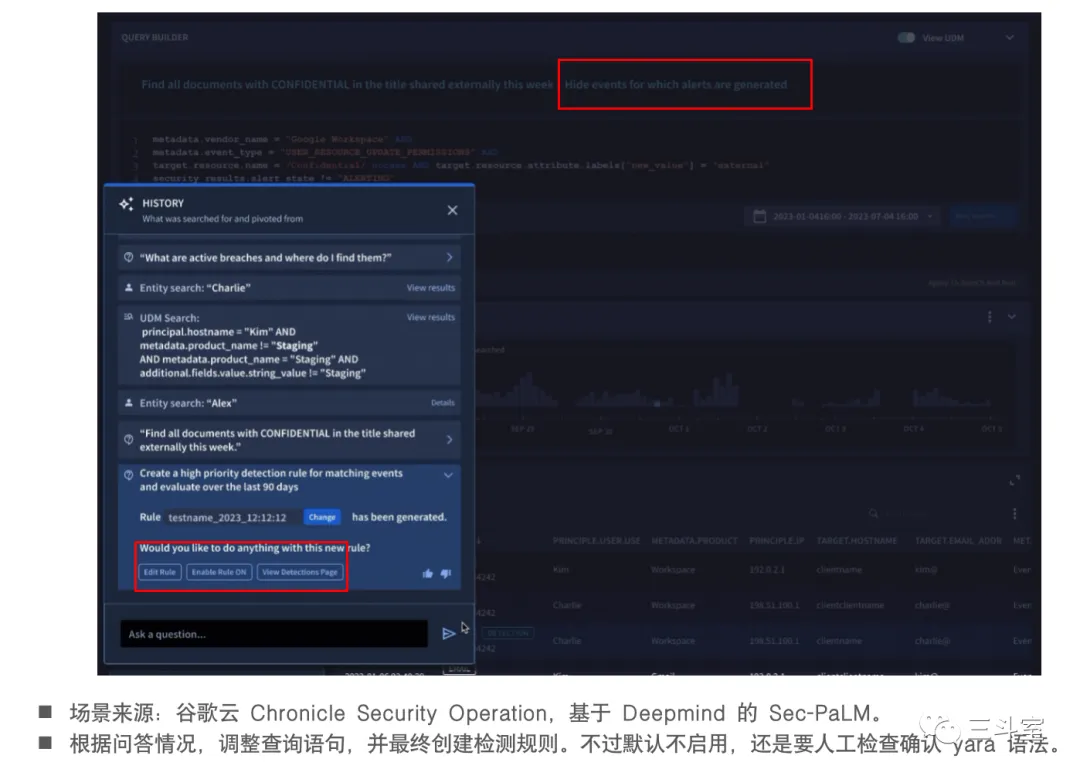
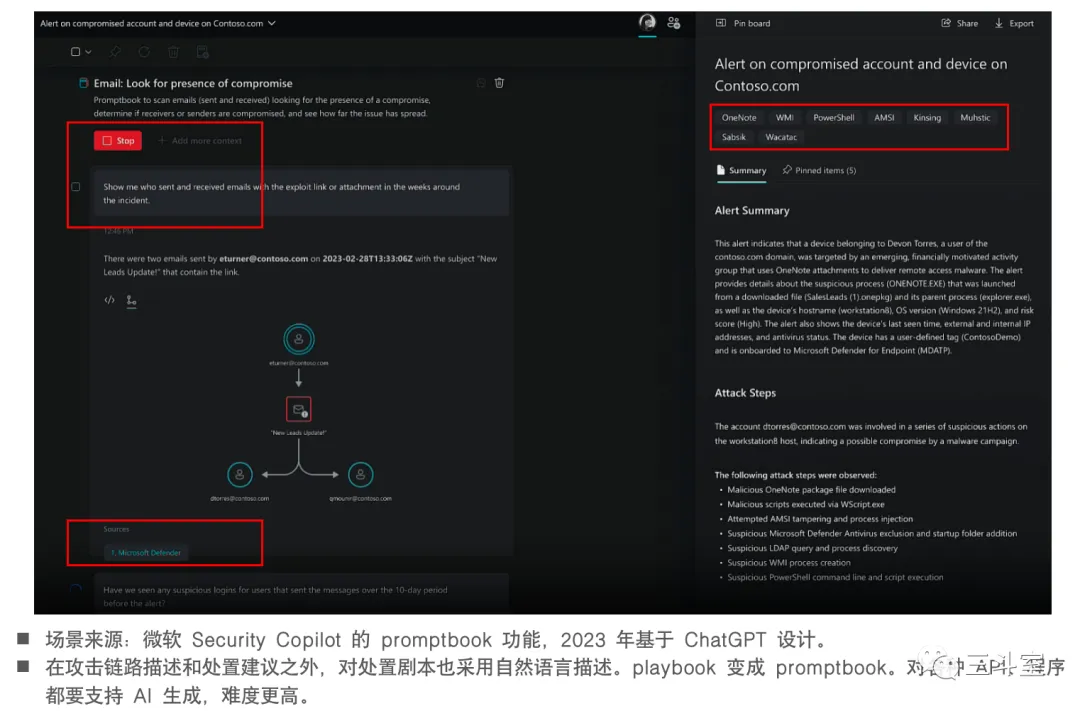
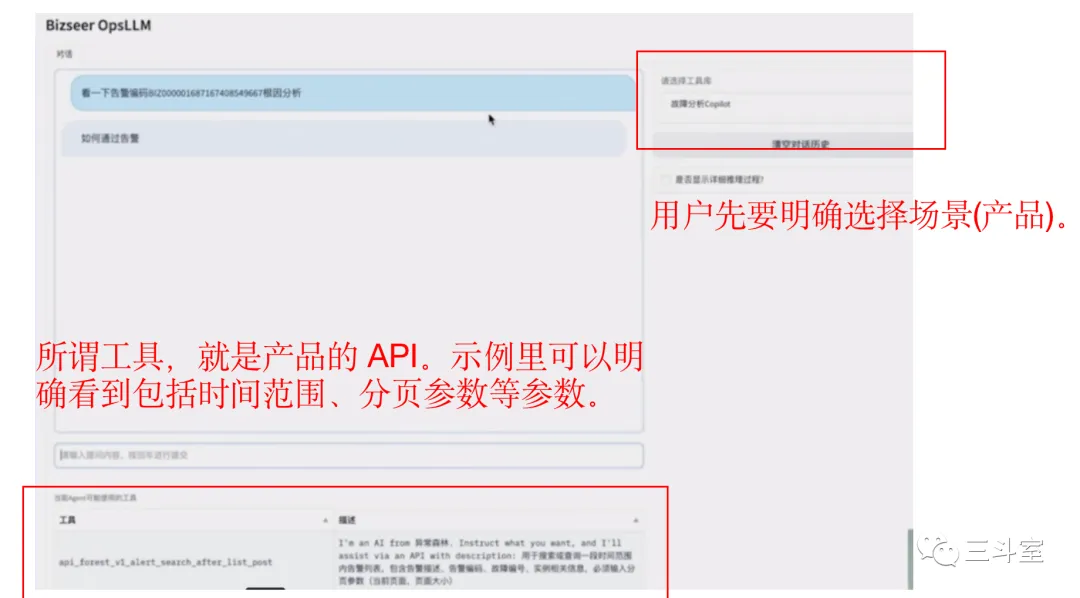
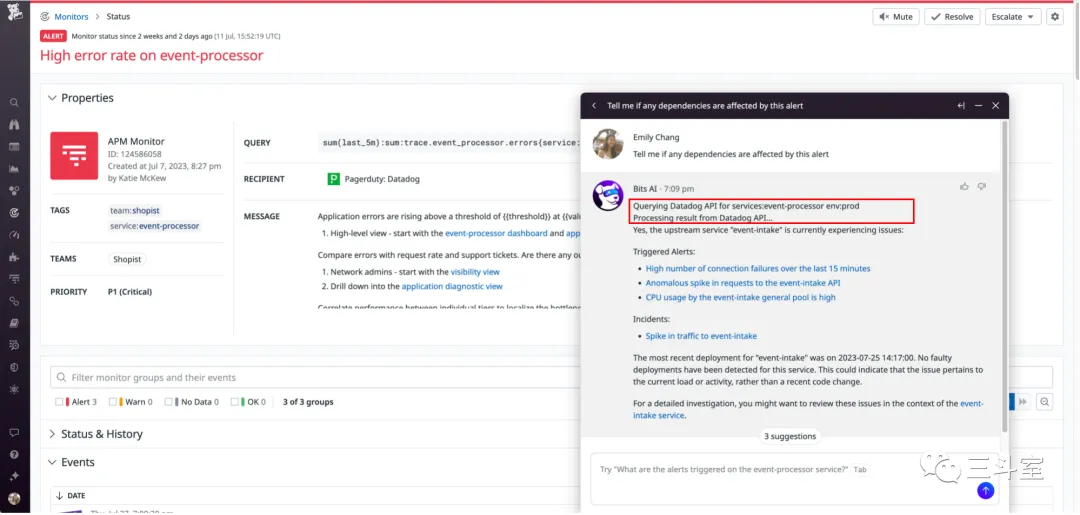
4 个国外厂商,1 个国内厂商的例子。APIChain 其实对任意软件都有效,不局限于运维安全或者数据分析。从上述截图里我们也可以看得出来,这个场景非常考验 PM 的设计能力。当然背后也依赖一定的语义分类技术。
- 必示目前还是 demo 阶段,因此对话前还要手动指定从哪个产品的手册里搜索 API 文档。
- datadog 直观告知用户,NER 从页面获取了哪些内容去调用 API,得到什么结果。
- newrelic 比较自然,把告警对应的指标、当前变更事件等信息,以图文多模态输出。
- google cloud 还直接创建监控规则了。默认 langchain 的 APIChain 可不敢支持 POST 方法,某种程度上应该是怕搞坏系统了。
- Microsoft 最狠,在 SOAR 的 playbook 外面封装了一层 promptbook 的新概念。这也确实是在实践他们自己的思路(我在《Schillace’s Law:好好使用 ChatGPT 的原则》中有所介绍)。
当然,APIChain 看似最容易落地,其实也还有很多细节门槛。后续有机会,我再介绍我们实践中碰到的一些细节。
4.3 自动推理
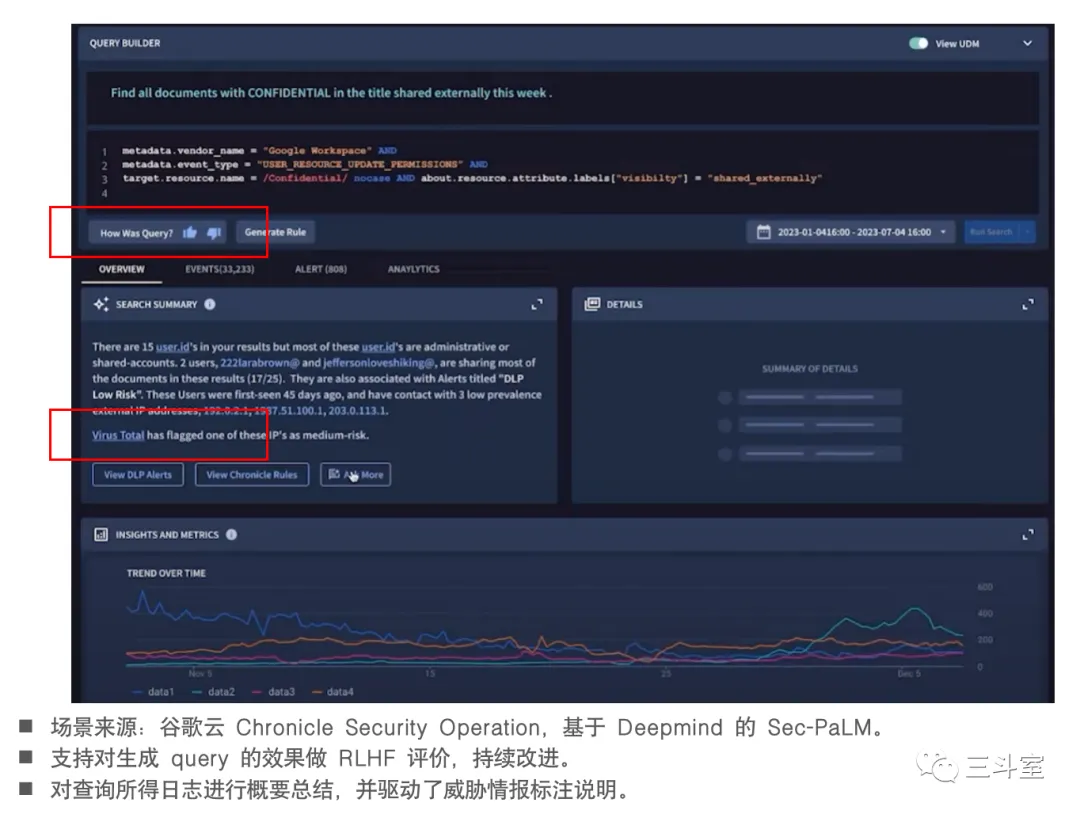
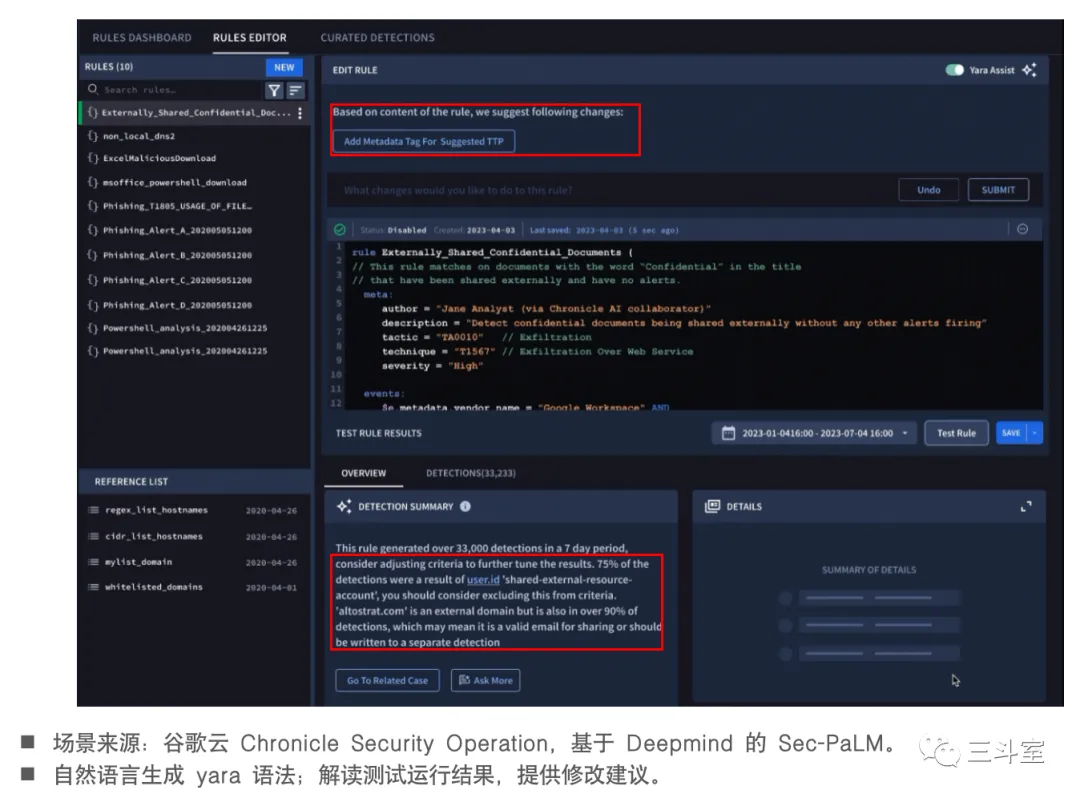
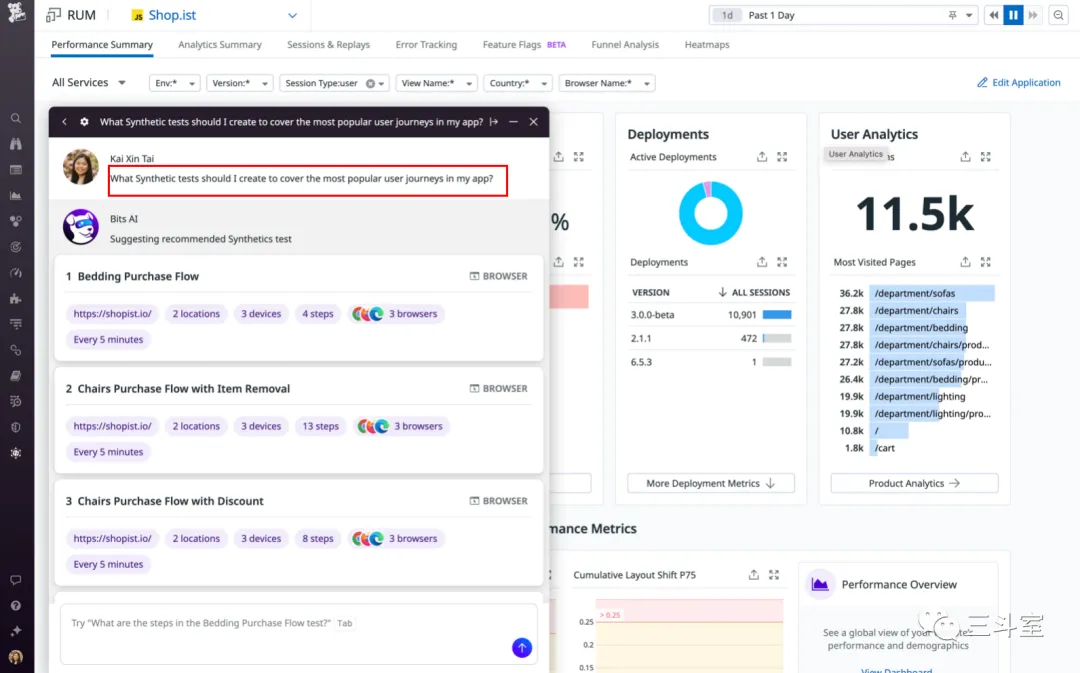
归类在这个场景下的厂家变少了很多,只有 google cloud 和 datadog。datadog 的用例,其实也还有点类似 Microsoft 的 promptbook 场景,可能通过一定的模板和规则匹配能实现类似效果。因此,我们重点介绍一下 google cloud 这个 search summary。
IT 工程师都知道,看日志其实是一个非常漫长和眼疼的事情。日志易、splunk、ELK 等产品就是为了解决这个问题,才引入了关键字搜索能力。但一个关键字敲下去,依然可能命中上万条甚至上亿条日志内容。还要通过阅读、翻页、缩小时间范围、添加新关键字等方式持续交互。
所以后续就又有了日志聚类(模板发现)功能,目前业内最主流的应该是香港中文大学 logpai 团队开源的 Drain 算法。聚类之后可能就只有几十到几百条模板,可以更快的掌握全貌。但因为模板里的参数值被丢弃了,用户看到关心的模板,还得钻取下去,逐次分析参数值的分布情况。
现在 google cloud 的 search summary 功能,可以直接把日志总结成一段简明概要,而且其中对关键行为的实体,包括人员账号、IP地址、时段、风险等级等的占比都能给出来。比日志聚类,又大大的缩减了排障时间。
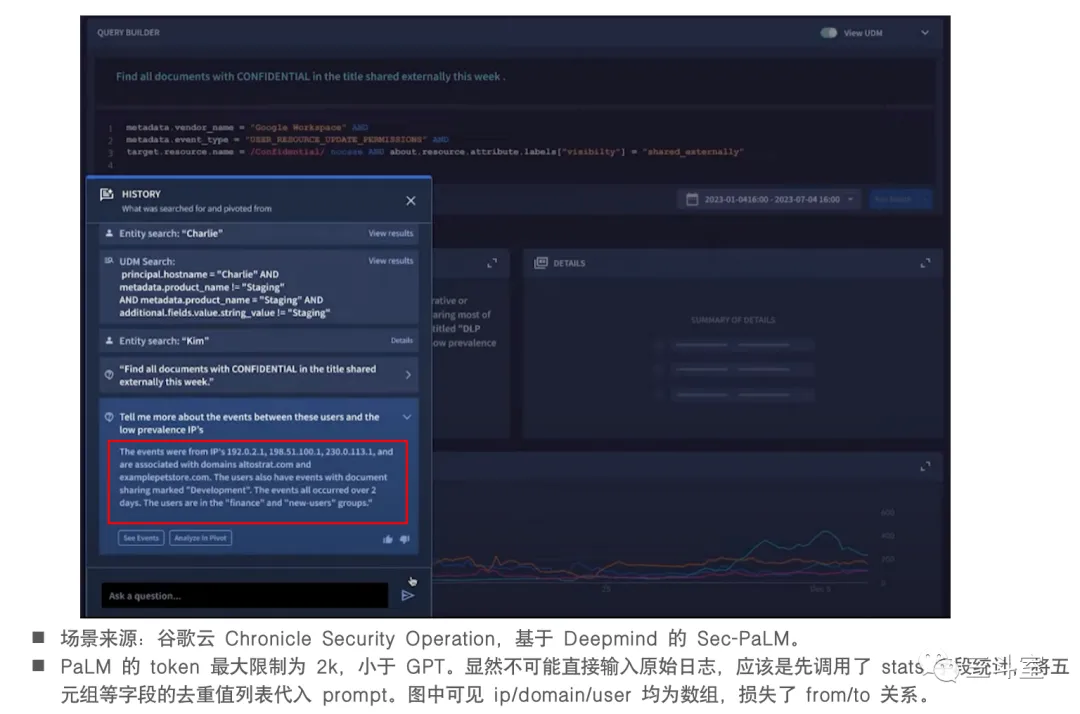
我们都知道,LLM 的 context windows 是有限制的,哪怕最大的 claude v2也不过 100k token,这对于平均至少 300byte 一行的日志来说,最多也就放个千八百行。所以,此处肯定需要有处理策略。
langchain 社区有一段教学视频发布在油管上,分 L1-L5 介绍如何做 text summary。到 L4 的时候,可以通过聚类方案来实现对整本书的总结:
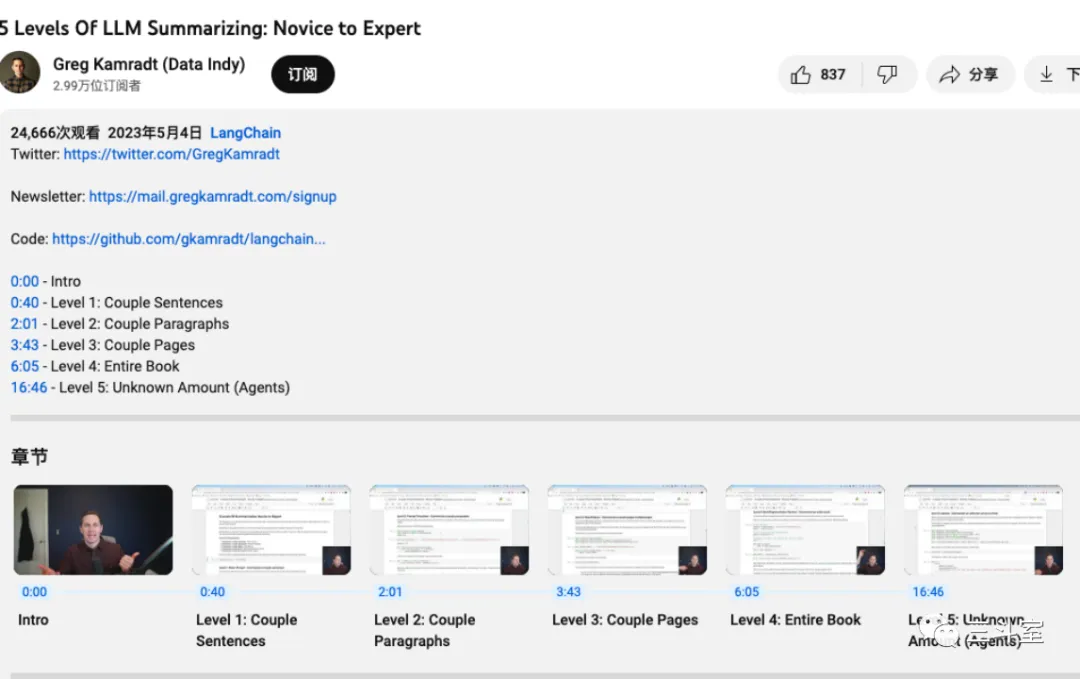
可惜经过验证,发现这个方法对日志总结场景效果一般。日志毕竟不是真的自然语言,在同一个聚类里,聚类中心点并不能代表本类数据的含义。

如果直接使用模板,参数信息丢失又太狠。

因此,search summary 必须采用 agent 智能代理方案实现。由 LLM 给出 thought 和 action。
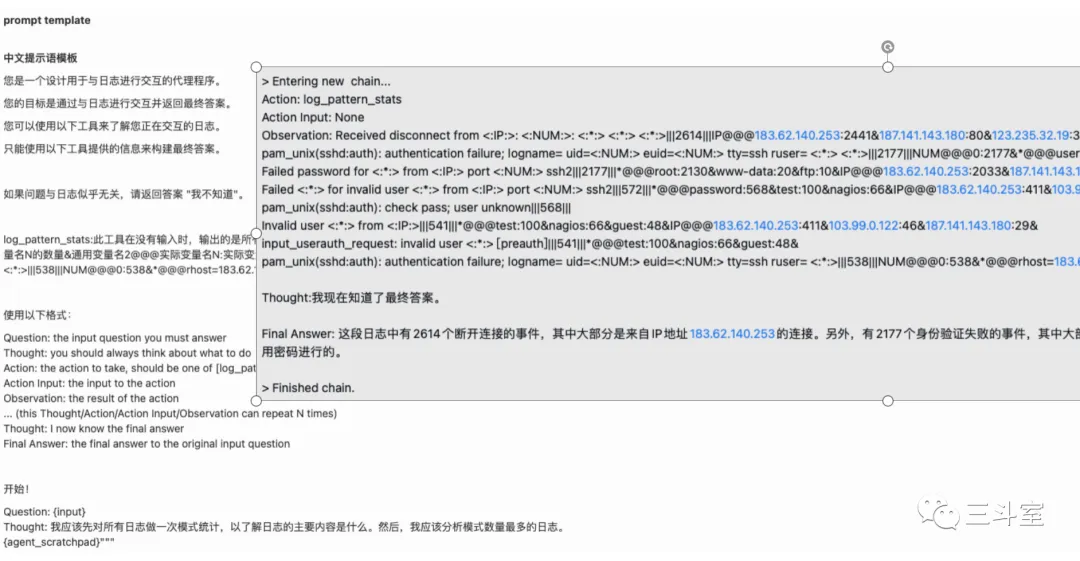
自动代理是目前所见,大模型在运维安全领域,最难落地,但收益也最明显的场景。我们也是在尝试之中,希望后续有所突破。
有趣的是,清华大学最近刚发布了 agentbench,专门用来评测不同大模型之间,自动代理能力的差别。目前看,差距非常大!有评测就有动力,让我们共同期待开源大模型,在这一领域的突破!
五、其他友商动态
除了上面有原型或产品截图的以外,还看到几家友商的公众号。这里也快速解读一下:
- 天旦 opsGPT,基于 vicuna-33b 做的 lora 微调训练,微调数据源是内部积累的 30 万条问答数据,本地 A6000 显卡上运行,评测方式是通过 CCNA 考试——评测方案是个亮点,锁定在较小领域,比较实际。
- 云智慧 cloudwiseGPT,也是 30 万条数据,分不同场景分别训练,通过 Mixture of LoRA 方式服务——真的不是蹭 Mixture of Expert 概念么?LoRA 是微调方法,不是推理方法啊(已发Owl论文,结论有误,致歉。)
- 金睛云华 cyberGPT,基于 ChatGLM 训练,本地 40 台 8 卡 GPU。扩展了 12861 个安全领域词表,进行了 34.2B+17.5B 预训练,19.2M+5.43M 微调训练。分为 PL 检测大模型和 NL 运营大模型——真有钱!扩展领域词表是个亮点。混合数据的比例和主流说法相比有点过拟合了。34.2B 相当于有 30GB 领域语料,不敢相信!19.2MB 也就相当于1-2 万条问答,为什么会有那么丰富的预训练语料但只有这么一点点微调语料?莫非是 github 上爬的一些代码库或者 CVE 报告?那又有其实 LLM已经懂了,重复训练的浪费感。最后,PL 检测大模型的样机上连 GPU 都没配,而且流量数据的规模显然不符合我们前面科普过的一个知识点:LLM推理性能跟不上大数据。所以,金睛云华的 PL 应该还是过去已有的传统模型,改个名而已。
- 众智维 RedGuard,基于 ChatGLM,配合向量存储,进行知识库问答。附加支持对话中贴图 OCR 识别。
六、总结
综上所述,大模型在运维安全领域,已经逐渐有了比较清晰的应用场景。大体分为三类五种:
- 所有软件都能做的:外挂知识库问答、 API 调用。
- 数据分析类:查询语句生成。
- 智能推理类:修复意见、日志总结。
基本也在裴丹教授的阶段图范畴内。不过对于无法轻松接入 ChatGPT 的国内运维软件,开源大模型目前还支持不起阶段一的“信任”,往阶段二努力,反而成了更实际的选择。



