大模型火起来已经一年多,大家应该已经见过很多prompt提示工程和SFT微调训练的文章,但讲预训练的少之又少。原因也简单:没这么多显卡和数据。
作为 AI 信徒,不亲自跑一把体验一次,总觉得自己信仰不纯。也一度想试一试 NanoGPT 项目,直到我突然发现:百度智能云千帆平台上,提供了全套的 post-pretrain、sft 和 rlhf 功能可供使用——其他云厂只有 prompt api 或者最多有 sft 功能——这太让人惊喜了!接下来几个月,我算扎扎实实把增量预训练和微调训练跑了一遍,花了 3000 元。期间给百度提了两位数的工单,今天记录一下,供大家参考。
一、数据集管理
首先,训练模型肯定要有数据集。甚至可以说数据集才是大模型训练过程中最重要的工作。
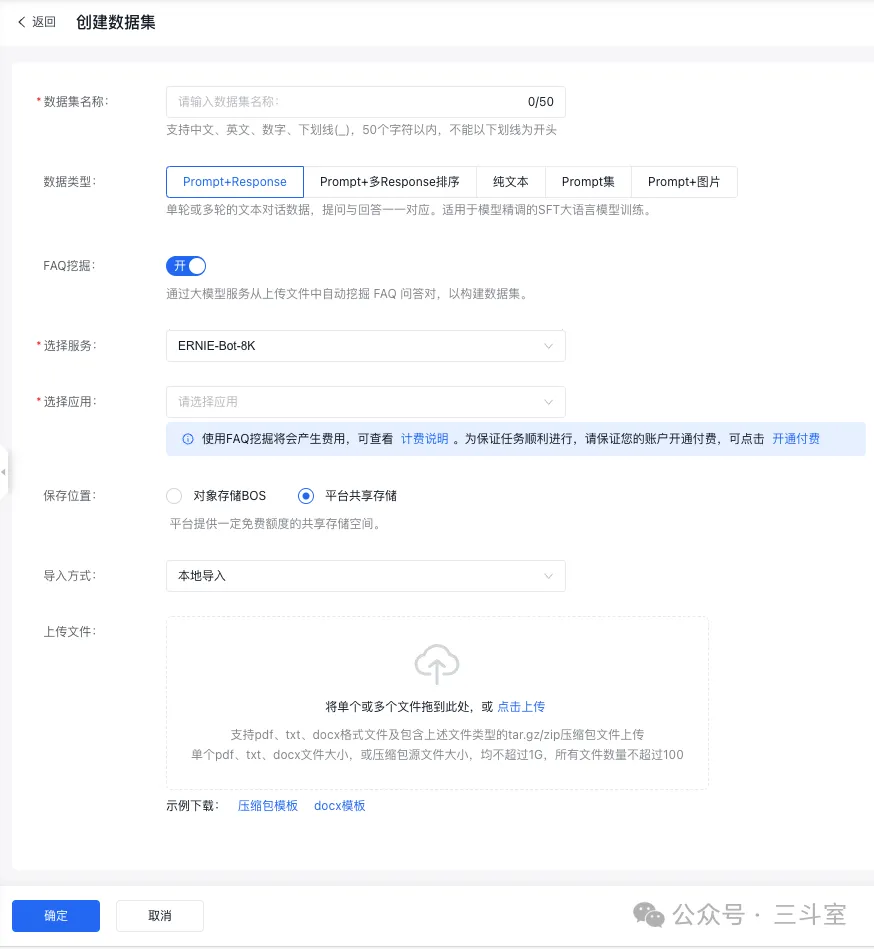
平台在创建数据集的时候,对不同的训练阶段,有不同的数据类型要求。
- 如果是 SFT 微调,数据是prompt+response。按百度要求整理成 jsonl 格式即可。
- 这里百度有个特别贴心的功能,叫 FAQ 挖掘。你可以直接上传不超过 60MB 大的 txt、pdf(注意:PDF 是需要能直接转成文字的,不能是影印图片)、docx 文档,平台会自动调用文心一言大模型,从文档中生成一问一答,每 2000 个字,生成 10 个问答对。生成以后,自己再肉眼过一遍,删掉特别不靠谱的部分。按照我用公司产品文档测试的经验,大概得删掉 10% 左右。注意这个功能要按模型 api 实际调用量收费,我司产品文档大概百万字,花了¥20 左右。
- FAQ 挖掘的缺点是:回答全都非常简短。不知道是不是百度为了节约资源,内置的 prompt 限定了输出字数。
- 另一个功能是自动标注。你可以上传 response 内容为空的数据集,然后让平台自己生成一个,你再修改或直接点确定。不过这些都是界面操作,真要几千上万条问题,够你花几天的。
- 最新推出的功能是推理数据集。其实就是自动标注的升级版。平台一口气把所有问题推理完成,然后你导出到本地再修改。目前是限时免费中,有需要的抓紧体(bai)验(piao)!
- 如果是 post-pretrain 预训练,数据是纯文本。这里百度要求是 txt 或 jsonl 格式。多个文件可以打包成 tar.gz 上传。要求是单个文件不要大于 1G,单个 tar.gz 里文件不要多于 1000。但是根据我个人经验,大于400MB就有概率导入失败。
- 百度预训练期望的 jsonl 结构比较特殊。比如开源的 SecGPT 数据,把一本书存成一条 content。100 本书就是 100 行的 parquet/jsonl 数据。但导入百度后,列表直接显示数据量为 1。它或许认为应该是一本书一个文件,一段话一行。但我工单咨询,百度工程师表示不影响预训练……
- 平台的数据清洗配置中也有一个可选项是过滤掉大于 10000 个 token 的数据,所以这种前后要求不一致就很难评。
数据导入时,你可能会碰上各种各样的局部数据导入失败。最常见的包括:
- jsonl 格式非法。大家一定要看示例文件格式,百度的格式非常非主流。
- tar.gz 里有空文件。这里的空包括:空格、换行。总之就是没正经文字。说实话这么简易的失败我不明白平台为什么不自己处理得了。
- 非 UTF-8 编码。这个在SFT 数据里应该很少见,毕竟 JSON 肯定是utf8的。但是 post-pretrain 因为是纯文本,你可能直接从 github 上下载一些内容,没准就是 GBK 的。所以一定要提前转换。
此外,你还会很郁闷的看到数据量和本地都对上了,但就说有非utf8编码的导入失败,其实可能是因为内容是全英文代码程序,被认为是 ascii 编码了。导入其实成功了,就是平台 bug 而已。
二、数据处理
导入数据以后,可以进行数据清洗、数据分析、数据增强。
数据增强就是著名的 self_instruct。在一年前大家基本都通过这个方案来调 openai 接口生成大量微调数据。但现在很多结论证明微调其实不带来多少新知识,只是对齐和规范输出格式。那么少量微调数据就足够了。我这次也没尝试做数据增强。
数据分析会自动给你的数据分类,你可以根据结果来判断自己准备的语料是不是偏了要不要补充一些针对性的内容。但我个人体会:分类太细了,基本无意义,执行还特别慢。这步大家跳过算了。
数据清洗按说应该是很重要的一步,开源大模型的技术报告中,都会专门讲解数据清洗步骤。百度云在这块也提供了很多功能,包括:
- 移除不可见字符、移除 emoji 表情替换、规范化空格、去除网页标识符。
- “移除不可见字符”建议不要用!百度对“不可见字符”的定义居然连
\s空格和\n换行这种都算。开启以后你的数据看起来就跟文言文一样 - “去除网页标识符”是个不错的功能。有些 docx/pdf 转换成 markdown 时,里面的图片、视频,可能会以 base64 直接存在文本里。实践中我转换了一批极客时间的 pdf,出来的纯文本数据大几百 MB,去除网页标识符以后其实不到 80MB。
- “移除不可见字符”建议不要用!百度对“不可见字符”的定义居然连
- 删除 token 过长的文档、删除困惑度过高的文档、删除特殊字符过多的文档、删除 token 重复率过高的文档。
- “token 过长”这个在前面已经讲了,如果你没有按分段处理,这块肯定不能开启,不然你的数据直接被删干净了。
- “困惑度”这个也很奇特,平台提供的示例,复制下来本地用 GPT2 计算得到的困惑度,和平台示例值__相差两个数量级。还是建议不要开启了__。
- 文档 simhash 去重。
- 这也是清洗的重要功能,但我试验中碰到 bug,也被平台确认了待修复,据说要几周,所以只好跳过。
- 注意:去重也是以文档为单位的,如果你没有按分段处理,这块也__不要开启__。
总结一下:百度云平台提供的流程很全,但是用起来很难,建议大家这部分还是本地写 python 跑吧。这类数据清洗工作逻辑简单,AI 都能帮你写好,我全程是让智谱 4.0 帮我生成的。
把长文档拆分成短文档时,有一个需要额外注意的地方:尽量保证段落完整。这块我采用的方案是,原始的adoc/docx/pdf/html文档尽量转换为 markdown 格式(pandoc 命令和 pdfplumber 库, tabulate 库),然后配合使用 markdown 库切分 section 和 tiktoken 库计算 token 数,尽量接近 4096 上限的划分 sections 到不同文件里。
百度 ernie 的 token 计算和 tiktoken 有些差异,百度云平台有计算器可以手工验证,但这个无伤大雅,不用太在意。
三、预训练数据源获取
大模型预训练需要较多的语料。平台上明确提示说最好 10 亿 token,至少要 1000 万 token。平台之前会大概按照你的数据量字节数估算一下,不到 1GB 的明显不够,直接就不让提交预训练任务——但是刚才我打开发现提示文案还在,但约束被取消了??
所以重点就是怎么获取本领域足够的语料,尤其是高质量语料。依然以开源的 SecGPT 为例,数据很大一部分是论文、书籍、CVE 漏洞库。不过我和作者沟通,作者表示实际训练时按比例缩减了论文的部分:
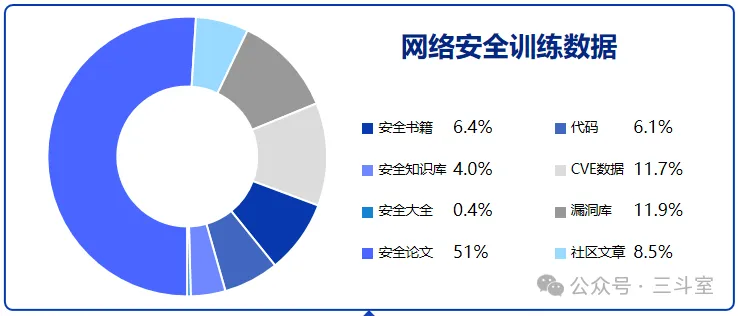
类似的,我们如果要训练一个运维领域大模型,论文、书籍,也会是一个重点来源。
很可惜,这部分目前没有看到比较公开的语料库,从科研角度,比较现实的办法可能是下载一些影印图片的 PDF,然后通过 OCR 方式转换成 txt 纯文本——好在 OCR 已经是一个很成熟的领域,我个人经验,百度飞桨的 PaddleOCR 在中文识别上的效果非常 OK,比传统的pytesseract库高不知道多少~强力推荐!
至于 ocr 程序,照样还是让智谱 4.0 来生成。国产 LLM 生成国产库的代码,基本靠谱……反而让 GPT/claude/Bard 生成 paddleocr 的代码效果都不太行。
一般来说,PDF 文件经过 OCR 变成 txt 以后,大小会缩水 20-100 倍,取决于图片是否高清。大家可以根据这个来估算自己要下载多少 PDF~
四、大模型预训练
到这步,终于可以开始大模型预训练了。
最终的数据集版本点击“发布”后,进入 post-pretrain 页面创建预训练任务:
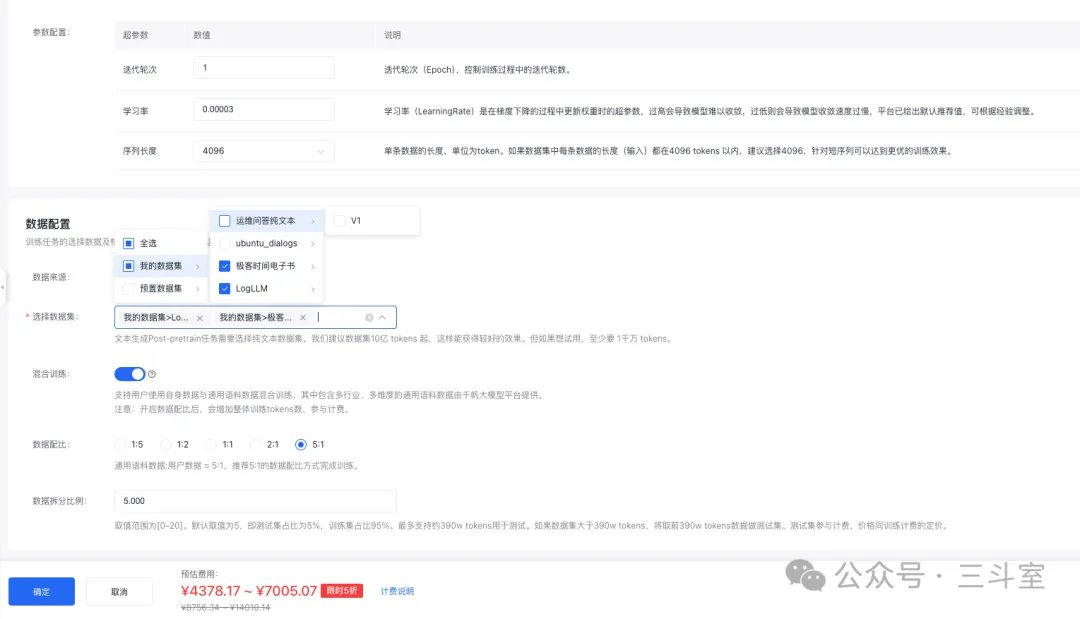
选择你发布的纯文本数据集,然后开启混合训练,按照推荐的选择 5:1。千万注意,这里又是百度云的一个坑。因为通常大家都说领域数据和通用数据混合比例1:5,但百度的页面上偏偏是反过来说通用数据和领域数据5:1——事实上他们连自己产研都坑了,页面上的提示文案之前也推荐用户选1:5,是我报 bug 后刚改的。
表单底部可以看到估算的费用。必须预先充值到大于这个估算范围的最大值,否则无法继续。甚至即使这样,我依然在第三天收到一条短信,告诉我要超额,任务要停。但最后又正常运行结束了。我也不知道这个计费系统到底颗粒度是怎么回事……
总之,训练完成后,你可以看到预训练过程的困惑度和训练损失曲线:
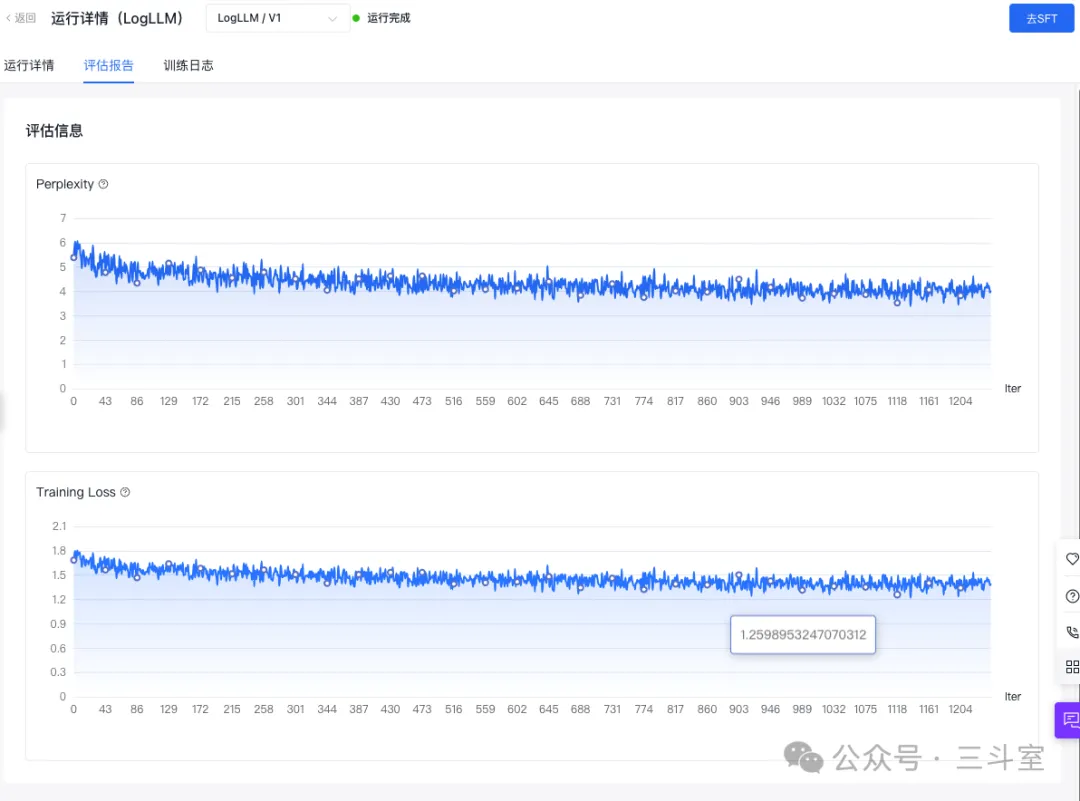
可以看到,loss%一开始就挺低的,后续也没下降多少。某种程度上说明,我准备的运维领域语料,其实大多在 ernie 的原始语料中,已经覆盖到了——事实上在 openaiops 社区的运维大模型评测中,我司贡献的日志运维题库,ERNIE-Bot 4.0 的得分就高达 79 分,遥遥领先。
五、大模型微调训练
拿到一个经过 post-pretrain 的基座大模型,下一步就是“去 SFT”。
创建 SFT 任务的表单多数内容差不多,需要注意调整是“迭代轮次”超参。表单默认是 1,但是要根据实际数据情况来增加。另外,增加迭代轮次,其实就是重复训练,所以花的钱也是等比例变多的。
有趣的是:百度平台上对 post-pretrain 后“去 SFT”的任务,建议不仅仅是混合数据训练,而是先用平台预置的通用数据做一次 SFT,获取通用对话能力,然后再用自己的领域问答数据,做第二次 SFT,加强领域问答能力(https://cloud.baidu.com/doc/WENXINWORKSHOP/s/5lptj85pi)。但同时,SFT 任务的增量训练,又有一个要求,就是上一次的 SFT 必须是全量更新,不能是 Lora——所以大家开通计费时,同一个基座模型的三种训练方式的计费都得开通。
SFT 训练同样有 loss%曲线可看,还有 BLEU 等评估指标。评估指标应该是越高越好。显然下图显示效果非常烂,本次 SFT 的钱就是买个教训了:
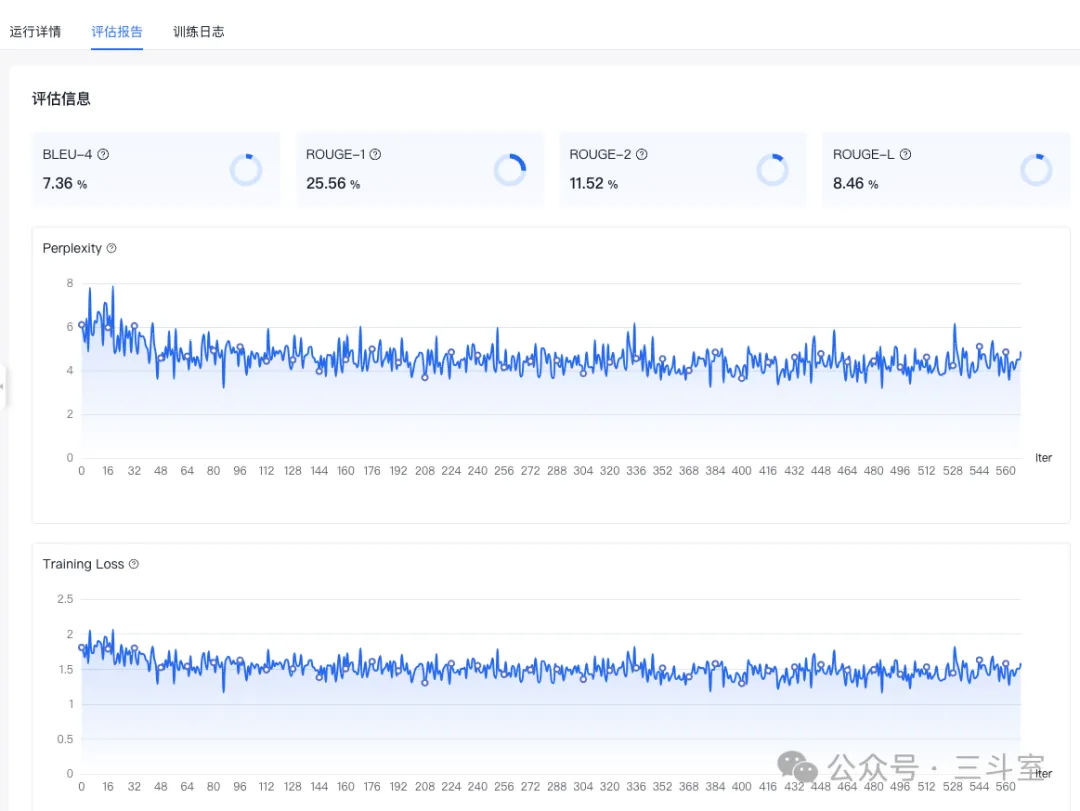
和百度工程师的沟通,对方认为:我的微调数据集构成有较大问题。其中一些选择题,prompt 一大段文本,response 就一个字母。而这些评估都是基于 response 内容来计算。所以,要获取更好的结果,还是应该多构建一些工程化的 prompt 和 response。
这也让我想到从 GPT4 以来,大模型的输出普遍更加“啰嗦”的现状——看来大模型训练数据,就是要多解释逻辑细节。然后使用时有需要了再通过 prompt 去限定简短格式。如果训练数据就简短,就训练不到逻辑了。
基于百度智能云千帆大模型平台的大模型训练经验/教训分享就到这里了。边写文章边发现百度云今天半价了!我这文章也不是软文,SFT 效果又不理想,亏了亏了。口口口,口口!



