事先声明:标题是吓唬人的,本文主要内容是解读和RCA根因分析有关的五篇大模型论文,并泼泼冷水。
关注大模型的大家都知道,微软和 openai 在过去这一年里合作得有多密切。事实上这种合作不光是科研和产品的,微软 Azure 云运维部门,用 GP3.5/GPT4 也做了一个又一个实验,发了一篇又一篇论文,急切程度,让我怀疑他们背 KPI 了——今天就带大家看一看,在微软,大模型到底能给运维人员做什么?
第一篇《Automated Root Causing of Cloud Incidents using In-Context Learning with GPT-4》
这篇论文其实比较简单,所有人都可以上手试试。主要内容是对比两种 RAG方案,在codegen/opt/bloom和GPT3/3.5/4上的效果:
- 一种是直接把历史 incident 按每 300 个token 切成一个 chunk 存 faiss 向量数据;
- 一种是分别对 incident 的告警描述、标注根因,用大模型做 summary,然后 all-mpnet-bse-v2 向量化以后存 faiss 里。
结论:
- 直接 chunk 召回给 GPT 的效果和用上一代 bloom 大模型水平相当(chunk 在拖后腿)
- 10-shots 效果最好(用不着32k 长度)
- 同样 10-shots vs 0-shots,GPT4 的提升幅度也最大(基础模型还是越聪明越好)
最后,作者还进行了一轮专家打分,包括可读性和正确性两个角度。结果:可读性拉满,GPT4 已经到了平均 4.72 分;正确性嘛,GPT4也只有 2.47 分。
于是作者又人工分析了一遍错误的 incident,发现:有一类情况,是 incident 描述里带有其他关联 incident 的标题,summary 时有负面影响。如果去掉这类数据,就可以到2.95 分,“接近 3 分啦,快及格啦!”
最后,作者还讨论了一下 incident 老化的问题,做了一些相关性分析,认为历史上没出现过的故障,靠 10-shots 也没用。但是微软作为云厂商,还是有一些 incident 会频繁复现的:
- 一类是硬件故障和维护;
- 一类是客户反馈问题但是修复版本要几周后才发布上线。
第二篇《Automatic Root Cause Analysis via Large Language Models for Cloud Incidents》
这篇又叫 RCACopilot,作者在 AIOps 挑战赛上有分享。可以看到比上一篇思路上有拓展:
- 首先,summary 的时候,不光是 incident 内容,还拉取了diagnostic info,也就是和这次告警相关的日志、指标、堆栈等数据。
- 第二,基于 fasttext 和故障数据,训练了一个 embedding 模型,替代了开源模型做向量相似度计算,计算结果还加上了时序系数,综合召回。
- 第三,并不要求 GPT 给定位和修复建议,全都自己准备好各种 handler,GPT 只需要做个分类判断调哪个 handler 就得了。
为了验证这几个改进的有效性,也分别做了实验,我这里直接上结论:
- 没有历史 incident 做参照的时候,GPT4 的得分跟直接搞个 xgboost 分类器差不多烂(不要指望大模型内置知识)
- 用原始的监控指标/日志,加监控策略分类等等,效果反而下降(做 summary 很重要)
- 用 GPT4 embedding向量的方法,遥遥领先其他方法,但还是遥遥落后自训练embedding模型方法(私域 embedding很重要)
论文里作者还提供了一些有趣的数据。RCACopilot的试用团队里,最多的一个团队,配置了 213 个 handler,handler 的平均执行时间是841 秒。接近 15 分钟啊,我太好奇这到底是什么团队了……
第三篇《Exploring LLM-based Agents for Root Cause Analysis》
这回的方案,就是最近很火的“多 AI 智能体”。
首先,作者直接用 langchain 的 ReAct 通用框架做了基线实验。目的是对比 ReAct 和 RAG 召回、LLM 自己 CoT 的效果差别。
ReAct 里使用了两个 Tool,一个用来在ReAct 觉得 incident summary 不够好的时候,回答 incident detail;一个用来召回历史 incident。召回这块又分了两种不同实现,一个是根据 incident 的标题和描述搜索,一个是让 ReAct 生成查询文本后混合搜索(BM25+Bert)。
看起来这个设计有理有据,但最后结果很尴尬:ReAct 效果别说比不上直接用 RAG,连让大模型自己 CoT 都不如!
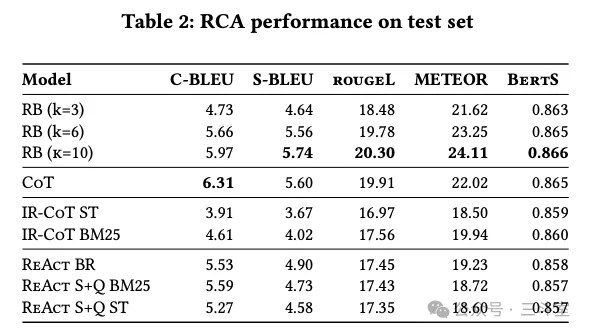
唯一的差异大概就是:把很多瞎编的错误,变成了证据不足的错误……
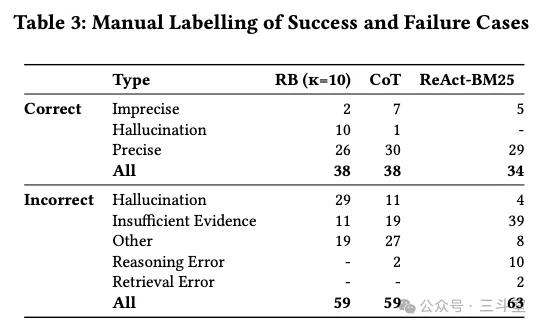
证据不足??于是作者把 incident 的 comment 内容也加入,结果依然没用。
有了这个结论,作者接下来花了一个月跟 on-call 团队反复交流工作流程,开发了几个针对性的私域 Tool:
- Database Query Tool。这个 agent 负责SQL 生成,查询结果做 Numpy 转换,最后给出自然语言回答。
- KBA Q/A Tool。将知识库 chunk 后存入向量存储,然后做RAG问答。主要场景是:上一个工具生成 SQL 时可能有一些具体的实体信息,需要从知识库里召回。
- KBA Plan Tool。上一个工具的变体。主要场景是:ReAct 框架会带来多智能体之间疯狂聊天的偏好,有些场景已经有固化的分析逻辑了,不用LLM 们自己瞎琢磨,所以从知识库里召回一些可靠的高层次的分析计划来遏制一下 LLM 跑偏。
- Human Interaction Tool。这个不是大模型代理,是真的人介入。因为有些实体信息可能确实从 KBA 里都搜不到,那么就等待人类提供信息,完善以后再继续执行。
不过这个新ReAct方案,并没有给出和通用 ReAct 方案一样的评估指标。而是直接上现场,做案例访谈了。包括简单和复杂两种案例:
- 简单的监控系统告警的排查。过程要先去查一下告警对象是否在线服务,不在线就忽略,在线就得额外查数据库看是否需要修复。
- 结果是:有时候能成,工程师也很惊喜;有时候参数提取一直失败,最后还是工程师介入了。
- 复杂的排查过程需要从多个不同的知识库里总结行动计划。工程师团队表示即使是人,也要 1.5 年以上的经验才能比较好地处理。
- 结果是:KBA Plan Tool 能构建一个看似挺合理的计划,但最终只有前一两轮能成功执行,后面就一直失败直到设定的 20 轮上限。
第四篇《Nissist: An Incident Mitigation Copilot based on Troubleshooting Guides》
这篇论文写的很烂,实际内容还不如在 youtube 上原型演示视频说的清楚……系统本身是一个人机交互过程,也没啥好讲的。
大概改进点就是对故障知识库的 summary 操作,要求结构化思考和输出:从logical、bridging、actionable、simplicity、process integrity几个角度来分析文档,然后按照固定的 terminology、background、faq、flow、appendix 分类做总结整理。
第五篇《Knowledge-aware Alert Aggregation in Large-scale Cloud Systems: a Hybrid Approach》
这篇是华为云的,又叫 COLA,但是场景和微软 Azure 云一模一样,无非微软的 TSG,华为叫 SOP。论文相关研究里也直接提到了前面第二篇的 RCACopilot。所以一并谈谈。
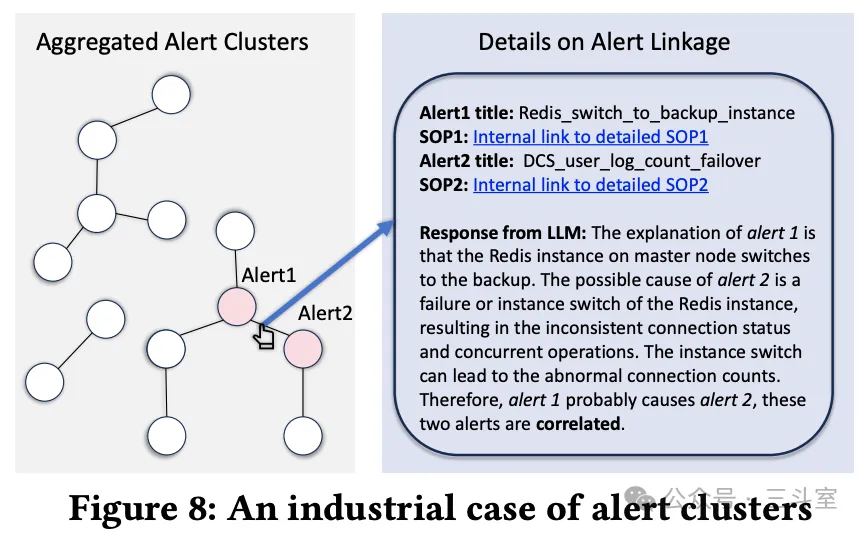
论文的特点是:先基于拓扑和时序相关性,对告警做一次收敛归并,然后把有直接连线关系的两条告警,和两条告警的相关知识库,都交给大模型来判定根因和推荐方案。
至于知识库本身怎么处理,也是 fasttext、summary、ICL 这套,不用重复介绍了。但论文附的 prompt 比较有意思,我贴图上来:

对,还有 negative samples!但论文没提这部分的构建,可能是写死的?
接着还提到他们用 PTv2 做了微调——开源社区唯一默认用这个方法的就是 ChatGLM-6B——但没有更多介绍了,作者非常吝啬!
最后是效果评估。数据集说是包括50 万个告警,对应 3k 个 SOP。这点不得不服云厂商们,很难想象普通公司有这么多积累可用的知识库。
结果也很有趣,没微调前的 COLA 效果其实和之前 sota 的 iPACK 效果差不多,但微调后效果大涨。用作者的话就是:“local parameter 优于 embedding”。而之前微软的结论都是 ICL 才最重要——我想来想去,唯一的解释就是 ChatGLM-6B 本身太烂,拖后腿了!
另外,还消融实验验证了一下告警归并两个环节的贡献,发现拓扑相关性的贡献率是5.5%,时序相关性是 31.8%——说来说去,还是同一时刻发生的告警高度相关这条直觉公理最有效。
最后也给了一个案例,无功无过,不甚出彩:
好了。和 OCE 故障定位相关的五篇论文就介绍到这里。
从微软/华为两家云厂商 OCE 部门的研究来看,有几个通用结论:
- 要有知识库,知识库,知识库!
- 尽量训练一个自己的 embedding 模型。
- 尽量用更大更好的模型。
- 只能应对一些简单重复故障。
- 不要迷信多智能体!
不知道大家是否认可呢?
btw:微软 OCE 更早还有两篇论文,一个是专讲如何 incident summary,一个是专讲根据 incident生成 Kusto Query Language,大家也可以一读。



