Splunk Conf24 最近公开了分享内容,这是 Splunk 被 Cisco 收购后的第一次年度技术大会。我看了一遍,大概总结有这么几个要素:
- cisco 对 splunk 和 appdynamics 之间关系的定义是 splunk 为主。
- splunk 在疯狂追求降低存储大小。
- splunk 对 LLM 的应用依然比较谨慎,不像 datadog 那么大喇叭鼓吹。
下面分开说。
一、可观测性:应用->业务
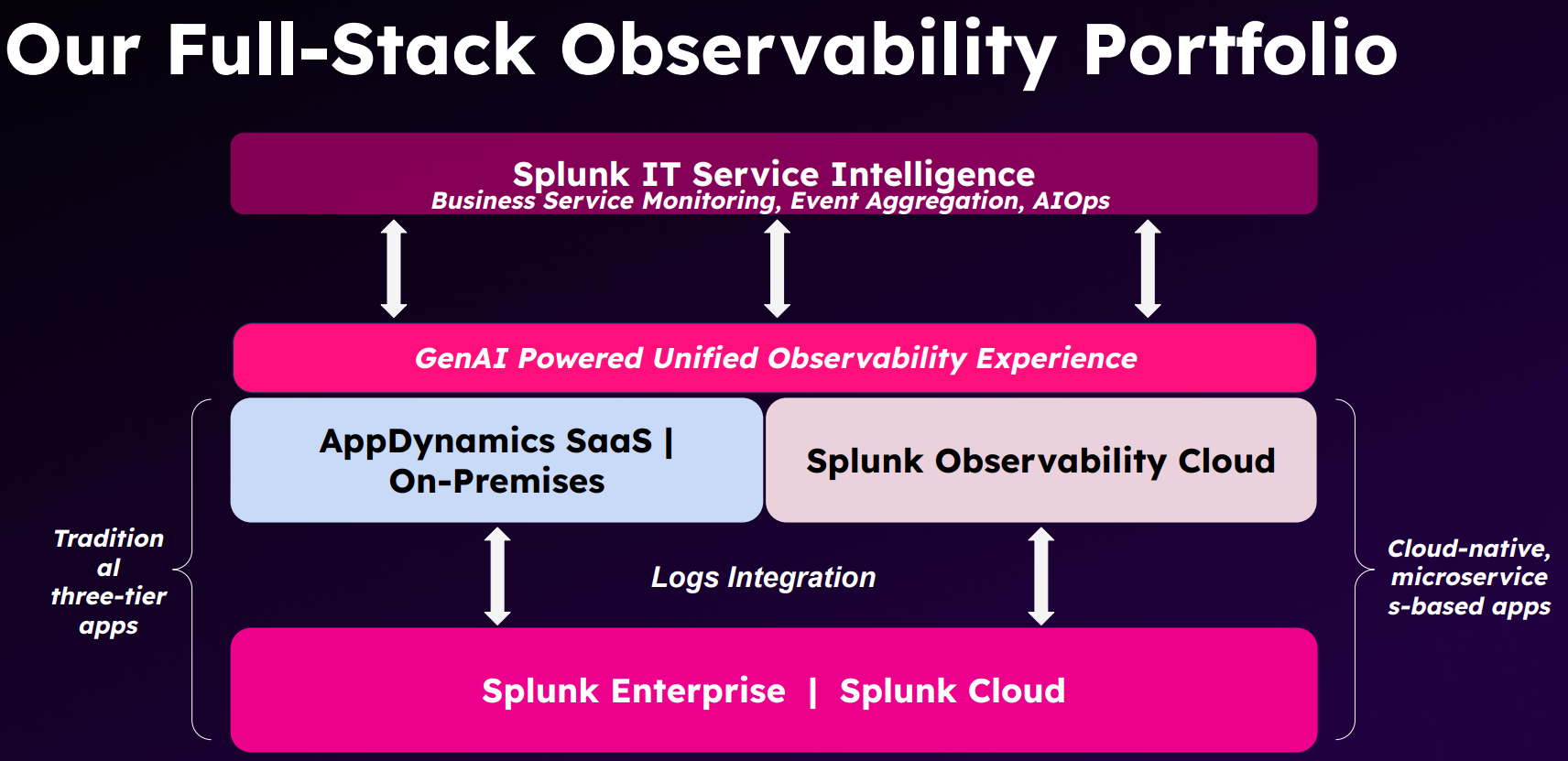
上图来自 Cisco CTO Advisor 的分享。也就是说,传统架构用 AppDynamics,云原生微服务架构用Splunk Observability Cloud,然后都集成到 Splunk ITSI 里,以 business 和 event 作为最终视角呈现给用户。
这个顶层设计非常舒适!相信这两年做可观测性的同仁都有类似的感受:折腾了很久,串联好链路,关联好指标,仪表盘看起来很亮眼,但 entity、service 和 transaction 层面的指标太多太细节了,业务团队压根不想看!
题外话:给大家分享一个香港中文大学和华为云的微服务研究MicroRes:https://dl.acm.org/doi/pdf/10.1145/3650212.3652131。在 chaosblade 注入的 27 个故障中,只有 3 个真正有影响,而有一半压根对业务没影响,其他的也或快或慢地自我恢复
所以还是要回到 splunk ITSI 的思路上来,人工维护一些核心的 business path,抓大放小。当然,依赖图的下半部分还是要来自 APM 和 ITIM 的自动化采集,所以集成工作很重要:
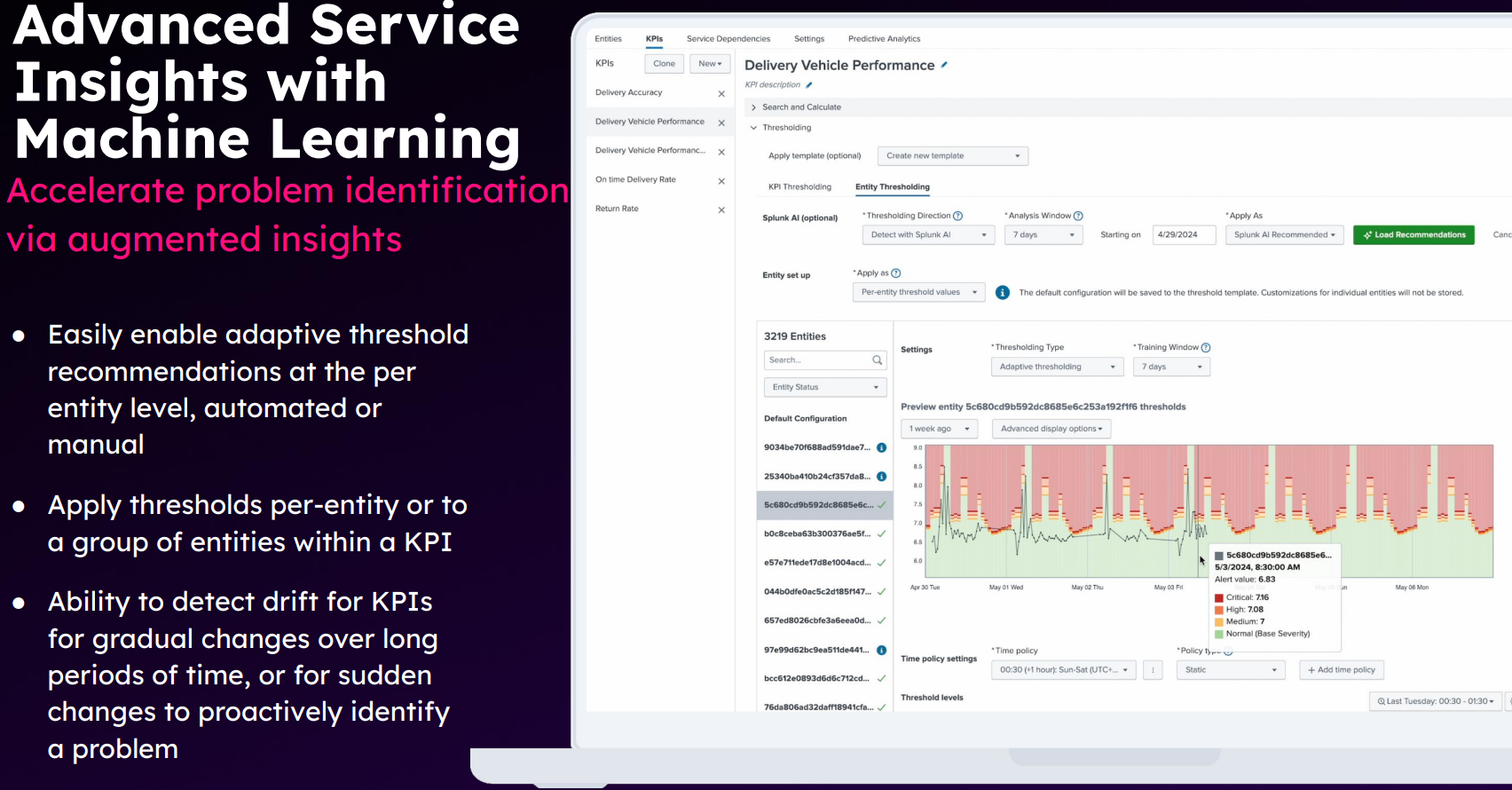
好的说完了,下面开始吐槽。 splunk ITSI 作为 AIOps 最火热的时候就开始打造的产品,在算法方面依然拉胯。这次 conf24 宣布可以针对每个 entity 独立调参来保证异常检测算法的效果。开什么玩笑??你截图上有 3219 个实例,谁干得过来?事实上大量调参人天正是国内 AIOps 项目半死不活的主因!
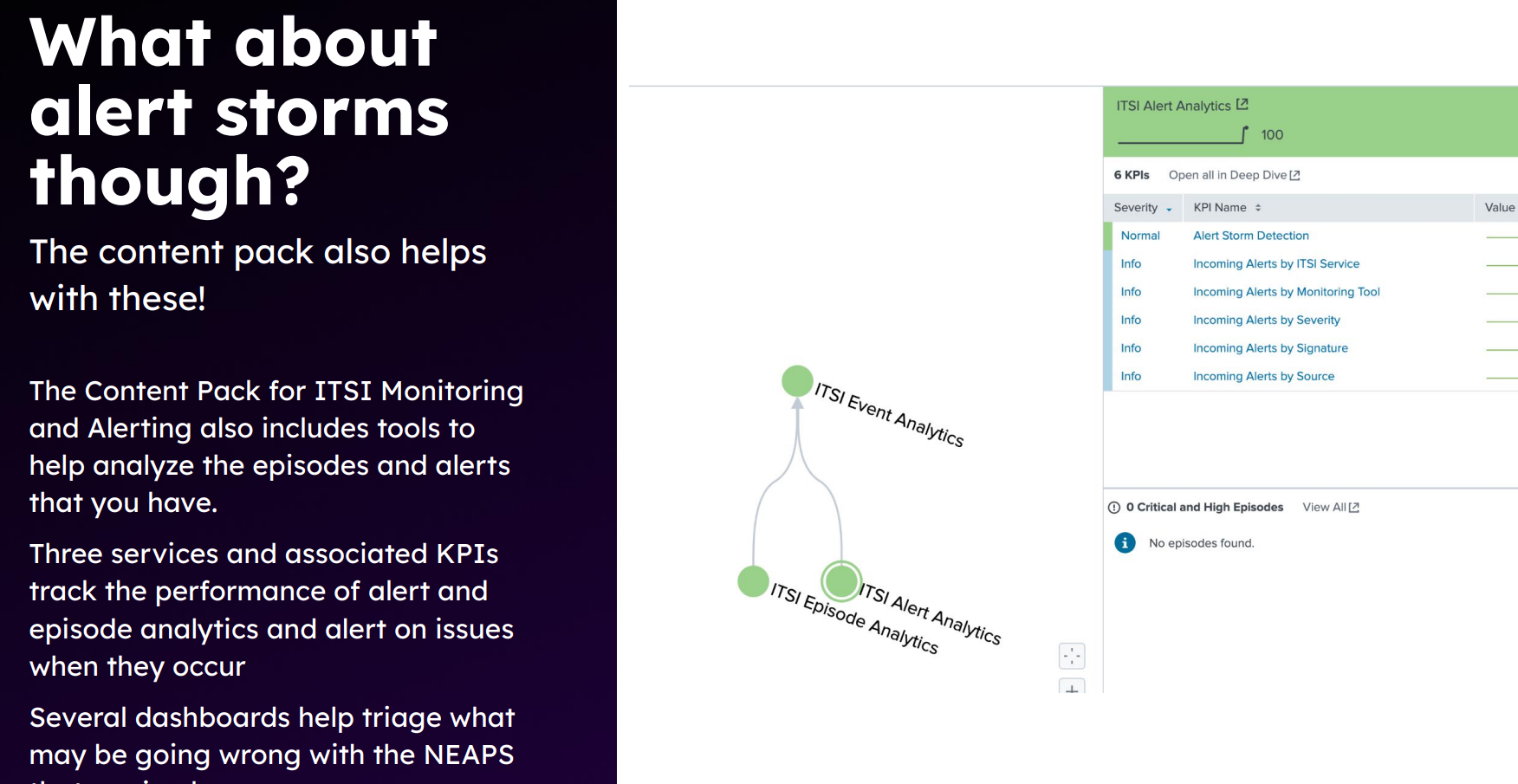
第二个是告警风暴的处理,这个也是 AIOps 常见的需求。splunk ITSI 的方案简单粗暴:我再定义一个监控就得了——国外友人真的好 nice 啊,这放在国内,能被甲方喷死。
二、可观测性 2.0 的最大难题:成本
这个话题其实不光是 splunk 在谈。grafana 在更前几周的大会上,一口气发布了全套的 adaptive log/adaptive metric/adaptive trace 功能做数据裁剪。
splunkconf24 上有几个客户分享,其中 Atlassian 公司(jira/confluence)明确分享了他们已经部署了 176k 个 otelcol,绝对是大规模了。另一个客户提到他们一天 60TB 的日志量,各种技术分析,去掉不必要的 DMA,优化 backfill 时间等等,来维持集群稳定。诸如此类。
所以 splunk 这次也是有巨多分享,从各个角度谈怎么压缩存储成本。
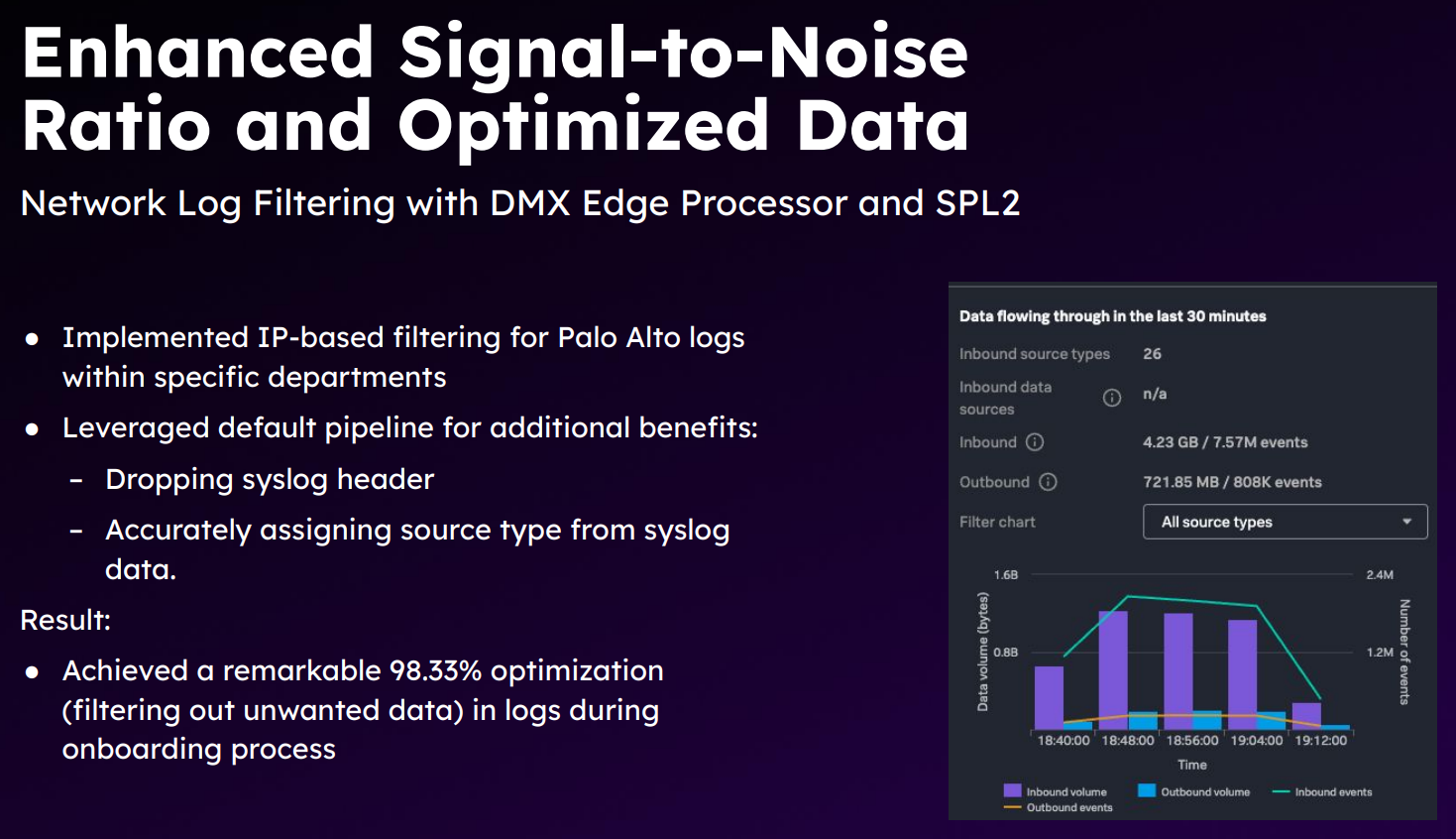
比如 splunk cloud DMX 产品分享中,提到 splunk cloud 上已经有 900+ 客户在使用事前提取,然后直接丢掉原文 text。并以 windows 安全事件日志为例,结构化并丢掉原文、一些不必要的 id、tag,换取 30% 的空间减少:
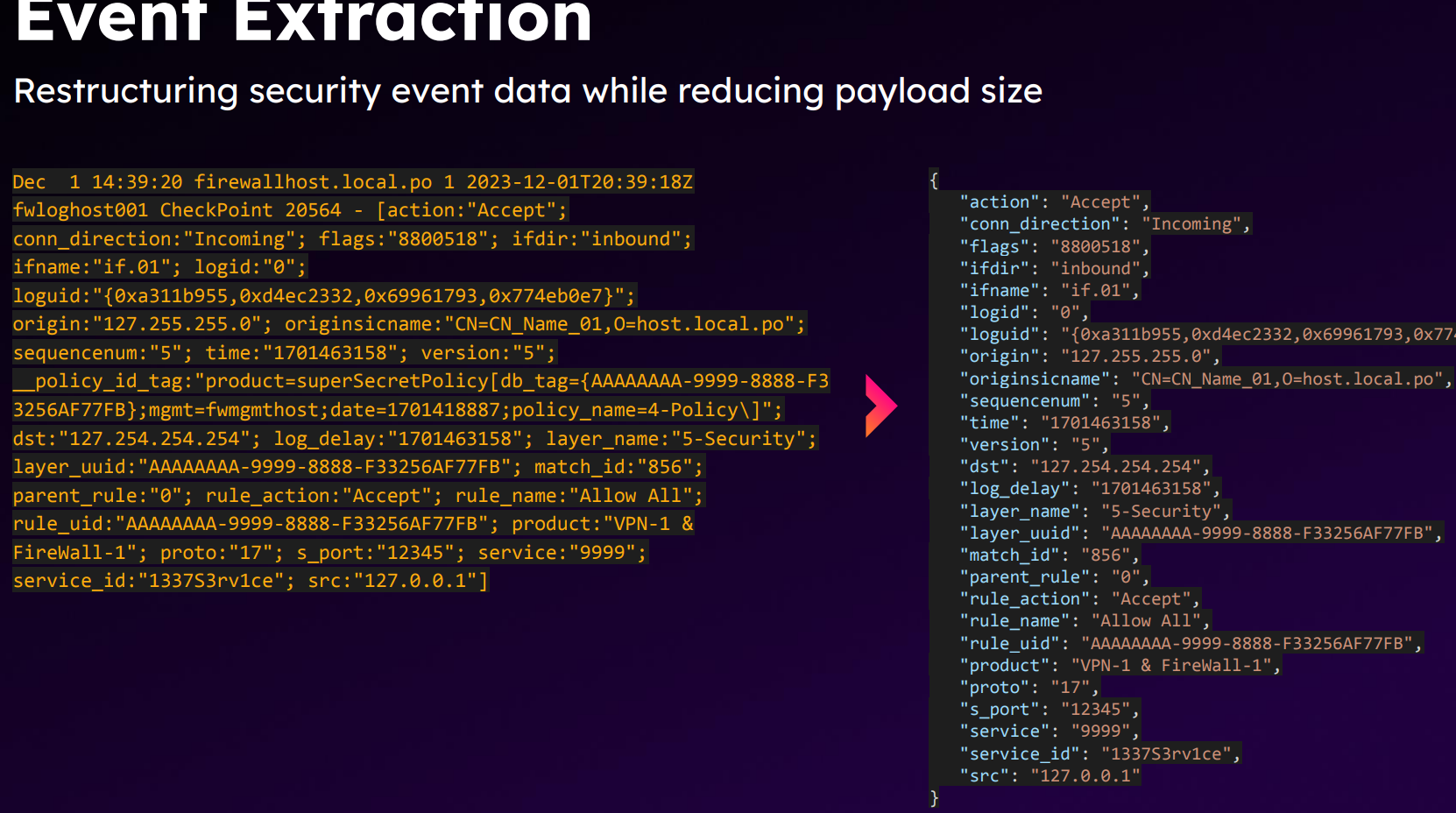
另一个 DMX 和 SPL2 的分享里也提到类似的话题,怎么在 edge 端减少来自 Palo Alto 的 syslog 日志大小:
又比如 splunk log metricization 功能分享中,直接把windows、k8s 和Azure 的审计日志说成:“Logs you should metricize NOW! ”

最后还有一个合作伙伴的分享,来自http://observo.ai/。提到他们有一套算法来实现对 trace 和 flowlog 的存储降本。
flowlog 其实好说,因为格式固定,过去我们也看到有初创公司做类似的事情,比如cwolves和 nimbus。
trace 就比较有趣了。而且 grafana 的套件里,也只有 adaptive trace 没有公布细节。而 splunkconf24 上这个分享就有一些设计了:
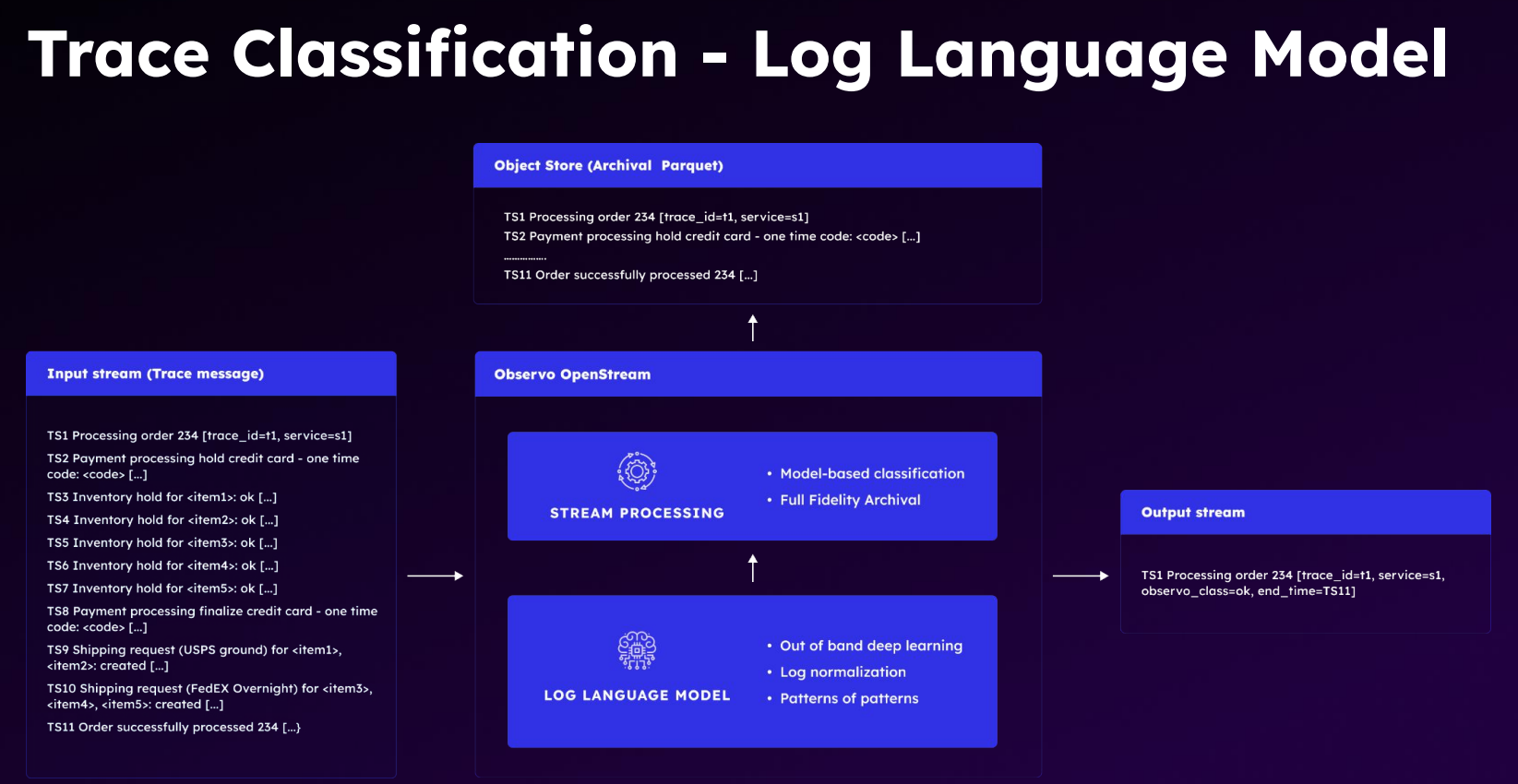
核心就是这个图。说 trace 数据进去以后,他会把原始数据直接存对象存储,然后用他的日志语言模型,做个判断,直接聚合成右边那种概述结果,发给 splunk,这样 splunk 上的 license 就可以降本。
关于 trace 存储压缩,确实是近期的热点,有空我还会单独写一篇介绍学界的一些研究。
三、大模型真的很难
最后,splunkconf24 上发布了 Splunk AI Assist。
splunk 其实在这方面做的很早,在 ChatGPT 还没发布的时候他们就自己尝试过基于 T5 训练 SPL 生成模型。2023 年,又发布了基于 starcoder 微调的 SPL 生成模型。
但是在 2024 年,datadog、newrelic 纷纷宣传自己的大模型应用,甚至出现了 flip.ai 这种创业公司的时候,splunk 反而冷下来了。哪怕这次发布,其实 demo 也不如 datadog 和 flip 吹得那么亮眼。大家可以先看 demo 视频:https://conf.splunk.com/files/2024/recordings/OBS1396B.mp4
在 SPL 生成方面,跟去年的变化不大。预告的未来功能里,会有“使用实际数据里的字段名”——我们日志易 ChatSPL 都已经支持了。
从 demo 演示的根因定位过程来看,基本都是单个功能点的调用。
- 第一个提问,故障定位过程特别简单,就一步,打开 tag spotlight,然后解读返回的数据。
- 第二个提问,列出相关的 3 个 trace,然后追问了 trace1。也就稍微要一点 chat history 处理,获取 1 对应的 traceid 到底是啥,然后还是一步调用获取 trace 数据来解读。
- 第三个提问,列内存最高的 top3 的 k8s node,然后把对应的 metric 查询语句给出来——如果是 datadog,这块应该就是直接要求用这个语句创建趋势图或者告警了。splunk 这里没有,手动复制去 create chart 了。
到底是 splunk 坚持私有化部署大模型,限制了模型能力?还是其他公司普遍性吹牛?我这里就不下结论了~笑



