上一篇《Splunk Conference 2024解读》里,我提到 grafana 和 splunk 都在探索怎么降低 trace 的存储空间。今天展开聊聊。
其实在可观测性概念火起来之前,APM 厂商存 trace 并没有什么空间担忧,一个关系型数据库都足以支撑。因为大家默认 trace 肯定是采样的、不用存几天的。百分之一、千分之一都是很常见的采样比例。
可观测性出现以后,大力提倡全量 trace,一开始写 elasticsearch 固然很爽,存上一段时间后,硬盘成本就成了难题。终于在 2024 年,引发了可观测性的成本讨论(https://www.honeycomb.io/blog/cost-crisis-observability-tooling)。于是,大家又回到这个老方案:trace 采样。
常见的采样策略,有在头部做随机采样、做指定接口采样,在尾部根据报错、根据超时采样。但这些简单采样确实有丢失信息的问题,所以也就有人研究更好更创新的采样方法。
一、阿里和中大的 Mint
论文见:https://arxiv.org/pdf/2411.04605
先介绍了一下阿里内部关于 trace 的一些现状统计:
- 每天有 20PB 的 trace 数据要存储。
- trace 从端侧向中心汇报,占用的带宽,快跟业务流量都差不多了。
- 如果采样,传统的采样方法,最后存不存就是 0 或 1,最后排障搜索,很多 id 最后就是搜不到(月平均 miss% 是 27.17%)。
所以 Mint 的目标是:既要降低存储成本,又要降低传输成本,还要保留所有 traceid 可查!
Mint 的办法是:提出一个“近似 trace”的概念。类似日志模式一样,提取 trace 的模式,然后保留 traceid、spanname、duration、starttime 四个参数的原值,其他参数的原值如果未被采样到,就在 trace 模式里用数值分桶、文本最长子串等替代。查询这些未被采样到的 traceid 时,页面就局部还原成下面这样:
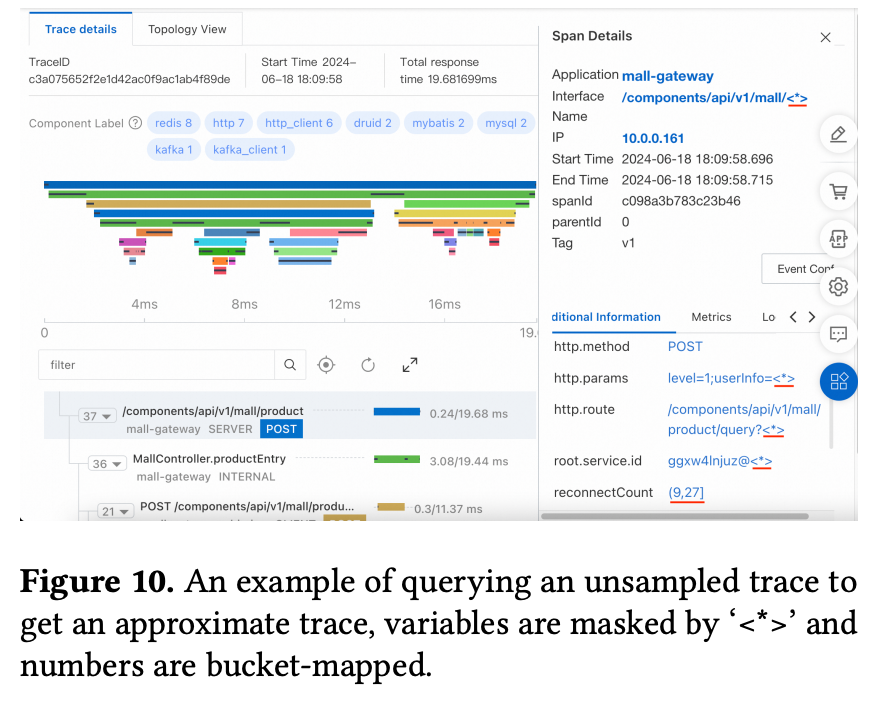
论文里还有很多设计细节,比如 agent 端侧怎么生成 traceid 的 bloomfilter 然后定时上报合并,根据 pattern 频次调整采样率等等。这里就不细说了。
此外,Mint 的“近似 trace”理念,还给 RCA 带来了额外收益。原因其实很简单,目前的微服务 RCA 算法,基础思路都是对比故障前后的正常和异常数据。而“近似 trace”意味着保留了原始比例正常数据,在计算耗时的时候更贴近实际。
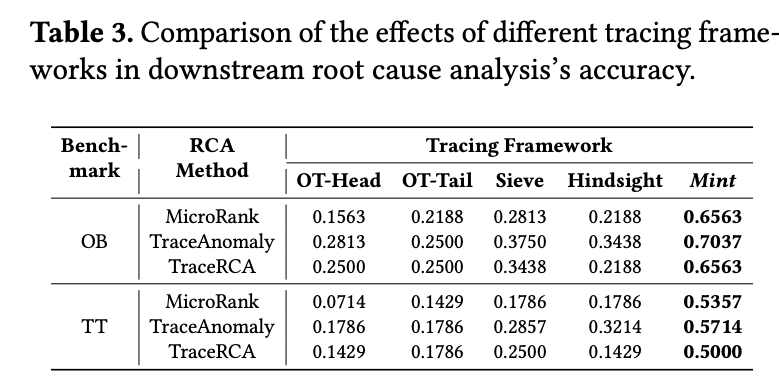
总之,Mint 的思路我个人感觉非常惊艳!不过还有有两点美中不足。一个是在压缩比评估时,没跟袁丁教授最新的 CLP-JSON 做对比。第二是阿里云一些线上服务运行后,实际总结的 trace 模式很少(10 个上下),可能会导致效果偏理想。
二、IBM 的 Astraea
论文见:https://arxiv.org/pdf/2405.15645
IBM 最近一年在可观测性方面其实有不少研究发表。而这篇的思路尤其有趣:保留全部 trace 不代表需要保留全部 span 啊!完全可以实现 span 级采样。
论文引用了阿里云更早的一个研究,trace 里只有 10% 的 span,在故障分析时是有用的。所以只要保留关键路径,就够了。那接下来就是怎么判断一个 span 是不是关键路径。
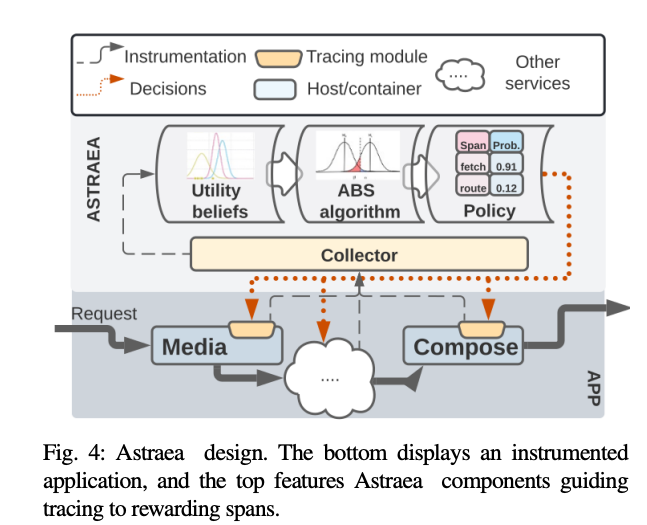
大致方法是:
- 给每个 span 的自身耗时预设一个 beta(1,1) 分布,然后根据实际运行中的 self-duration 耗时,来更新这个分布 的 alpha 和 beta 参数。
- 得到分布以后,再设定一个自适应阈值,假定这个 span 耗时超过多少更值得关注,比如默认认为超过 P90 就算。
- 接着用蒙特卡洛方法来筛选,根据实际的 beta 分布,采样这个 span 在自己的 beta 分布上的1e+6个数据点,超过上面 P90 阈值的概率。这个概率就是这个 span 的采样率。
- 当然还有一点托底的最小值,保证不会永远遗漏掉一些小 span。
不管是近似 trace 还是 span 采样,都是非常简单的算法,核心思想一说就透,而且某种意义上这两个方法和传统采样方法之间还可以叠加复用。我也期待 grafana 后续公布他们 adaptive trace 更多的方案细节,还有没有更多创新思路呢?



