过年前后,deepseek 大火特火的时候,安全圈突然爆出 deepseek 的数据库泄露了!研究团队的原始内容参见:https://www.wiz.io/blog/wiz-research-uncovers-exposed-deepseek-database-leak。
研究团队比较厚道,等 deepseek 修复数据库认证问题以后,才发的新闻,所以网上没多大动静。不过作为日志分析从业人员,我们还是可以尽量从这篇技术报告里,推算出来一些东西。
数据提取

第一张图,安全团队眼里这是 prompt 泄露。在我们日志分析团队眼里,这是一段 OpenTelemetry 导出到 Jaeger 后端的 Trace 日志。otel.libarry.name 为 usage-checker,显然不是一个开源基础组件,应该做不到自动插码,所以 deepseek 研发团队应该是自己插码了。
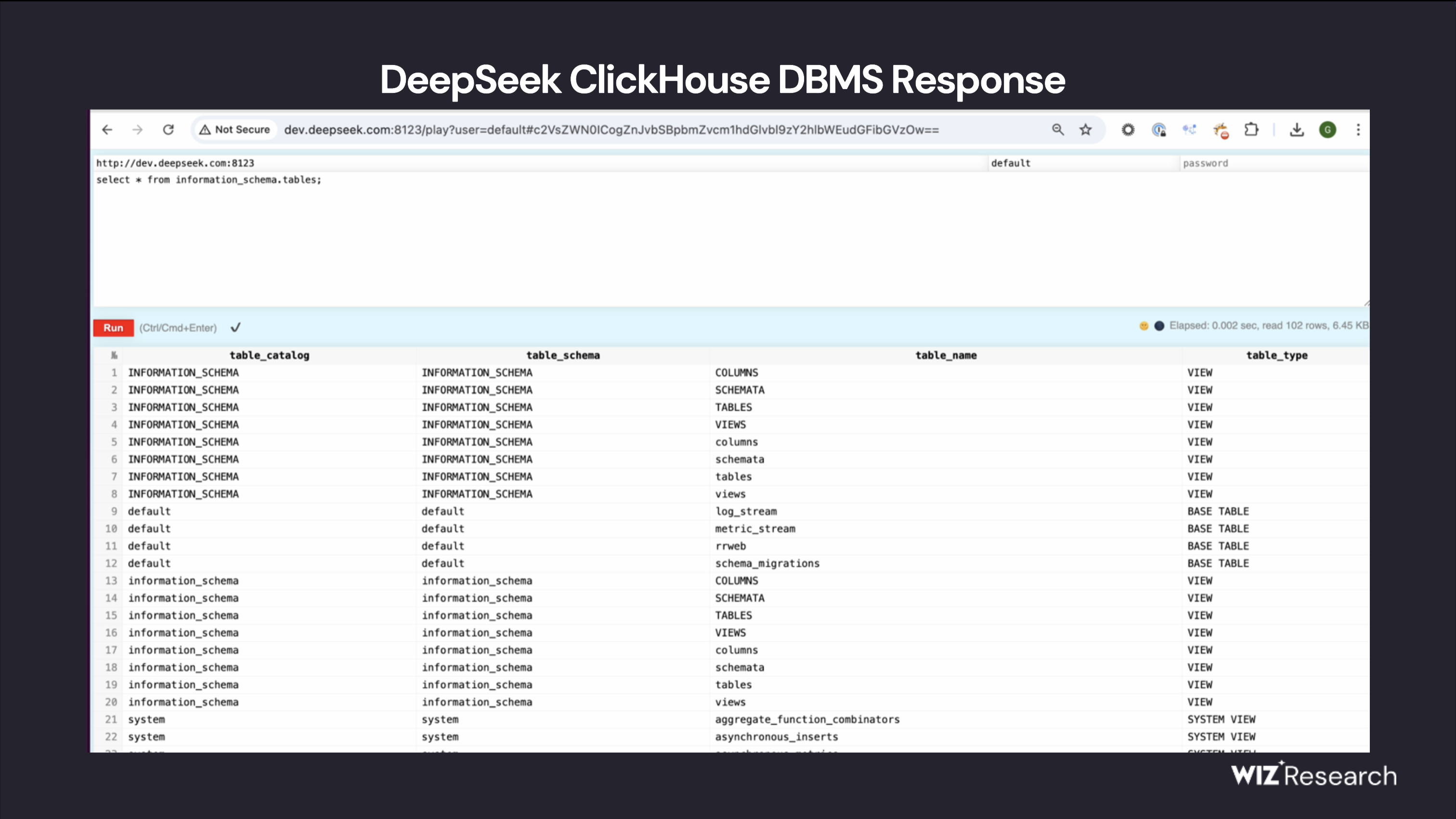
第二张图,安全团队眼里这是 clickhouse 查询页面。在我们日志分析团队眼里,log_stream 存了 jaeger 日志数据、metric_stream 存了 Prometheus 监控指标数据、rrweb 存了session replay 录屏回放数据。——deepseek 的可观测性工作做得挺全面的啊!怎么做的我们继续往后看。

第三张图,这是从运维日志角度看泄露信息量最大的一句话:“976.28K rows, 2.25GB in a couple of minutes”。但是具体怎么推算,我们还要结合下面第四张图一起看:
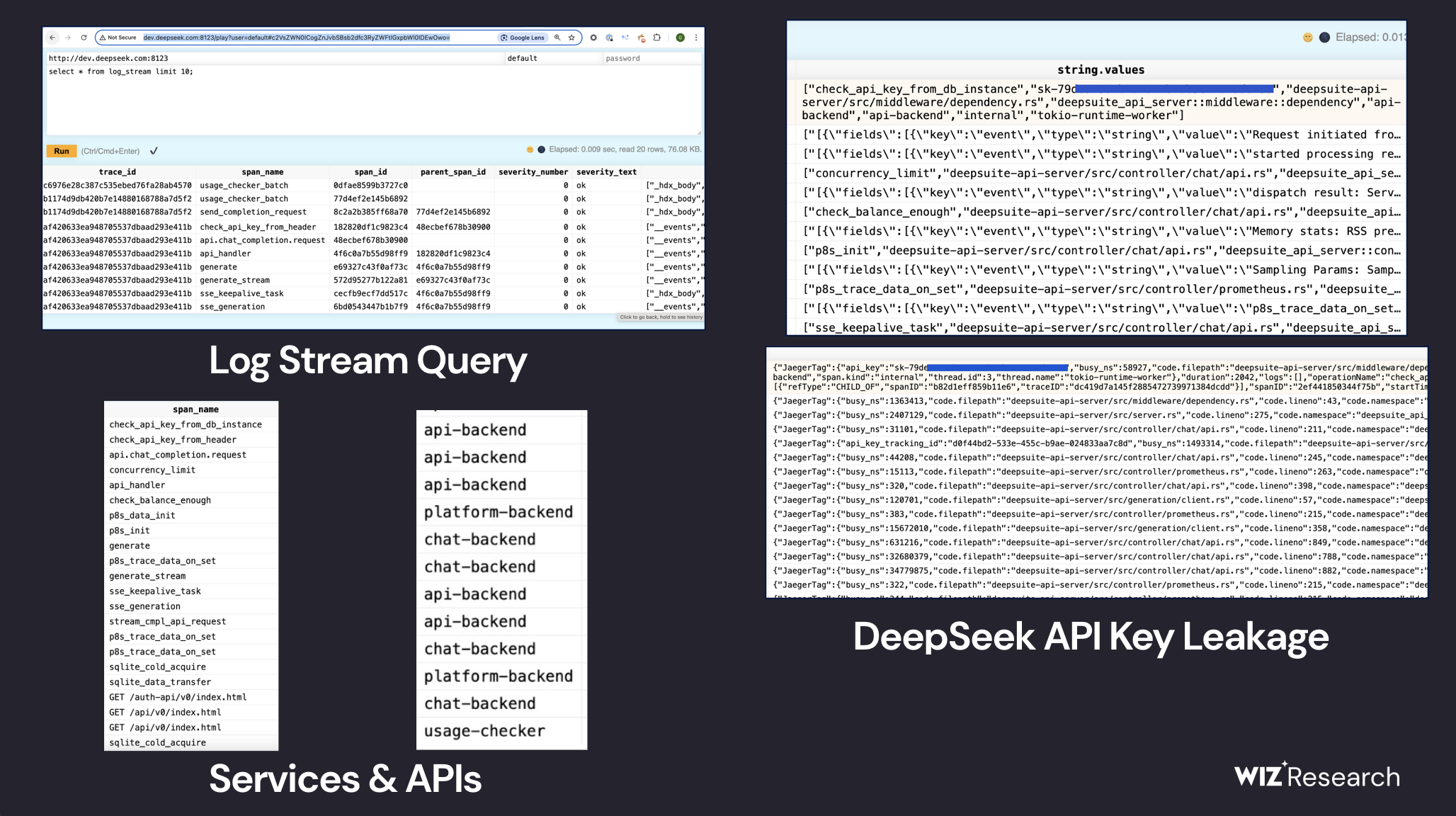
安全团队眼里主要是看 API key 泄露,但是我们日志分析团队看到的是:
- deepseek 后端使用了 Rust 的异步框架 tokio 开发。
- tokio 除了 opentelemetry 插码,还启用了 tokio-metric 组件发送 Prometheus 监控指标,这个和metric_stream 库对应上了。我们甚至在 span name 里看到了 p8s_init/p8s_data_init/p8s_trace_data_on_set 等好几个相关的 span。deepseek 的插码有点过度细节了,
controller/prometheus.rs可以跳过啊。 - span name 和 services 其实不算很多,左下角部分一共就列出了 18 个接口和 4 个服务。不过从右上角看,因为是研发自己插码,除了服务间调用,也有一些 span.kind 为 internal。
- jaeger 开源社区有多种 clickhouse 存储方案,但表结构设计都不是 deepseek 泄露的这样子(应该叫otel_traces或者jaeger_spans/jaeger_index)。但可观测领域确实有一个小众产品是这么设计表名的,叫 HyperDX。所以 deepseek 应该是选中了这个来做可观测性:

注:实际上 HyperDX 社区也有人提 issue 说这事儿了:https://github.com/hyperdxio/hyperdx/issues/590
不过没关系,我们可以借用 jaeger 社区的 clickhouse 单表存储的压缩率经验(https://medium.com/jaegertracing/making-design-decisions-for-clickhouse-as-a-core-storage-backend-in-jaeger-62bf90a979d),2.25GB 对应的 Trace 原始大小应该在 10G 左右。
分析推测
好了,数据都摆出来了,最后,让我们来推算一下,deepseek 在被泄露的 1 月 6 号,大概有多少活跃用户?
- 2-3 分钟内,产生了 10GB 左右,976280 条 span。2-3 分钟内,产生了 10GB 左右,976280 条 span。
- A. 如果插码较少,按照 service 数量计算,那么平均 5 条 span 一个 trace 计算,就是 20 万次 trace。如果插码较少,按照 service 数量计算,那么平均 5 条 span 一个 trace 计算,就是 20 万次 trace。
- B. 如果插码较多,尤其是 Chat 流式输出的情况,我们看到接口里确实也有 sse_keep_alive 和 sse_generation,那可能就会多达成百上千个 span 了。按照 600 个 span 计算(此处来自 Claude 3.5 sonnet 拍脑袋),就只有 1600 个 trace。
- 根据日志量推算,一条 span 长度大概有 10KB。而这个大小远超默认的 otel 或者 jaeger 经验数据(一般1-3K),所以我倾向于选b。
- 1 月 6 日,deepseek 尚未发布 App,海外用户还没引爆,只有国内的网页版用户,活跃时间应该集中在白天上班时间。那么全天应该有1 月 6 日,deepseek 尚未发布 App,海外用户还没引爆,只有国内的网页版用户,活跃时间应该集中在码农 996 的白天上班时间。 那么全天应该有 57600 个 trace。
- 2023 年 8 月 ChatGPT 的数据,用户平均每天的会话次数大概是 6 次,每日独立用户数为 3157 万,每天有 6 千万次查询(https://aimojo.io/chatgpt-statistics-facts/,不要问我为啥 3 千万登录只有 1 千万发起会话)。那么类比一下,当时 deepseek 的每日活跃独立用户应该在 3 万左右。
- 2023 年 4 月,openai 另外还有推理成本的财务估算,换算一下,是当月 18 亿访问,每天 2 亿次查询,按照 AWS p4d.24xlarge 实例计价,相当于 7120 块 A100 显卡(https://nerdynav.com/chatgpt-statistics/ 和 https://www.namepepper.com/chatgpt-users):“In April 2023, estimates indicated that running ChatGPT cost OpenAI approximately $700,000 per day, with the cost per query being around $0.36 cents. In 2024, 4o mini was released to cut down costs by 60%”。而微软泄密论文说了 GPT3.5-turbo 是 20B 模型,GPT4o-mini 是 8B 模型。
- 去年 Kimi 的访谈记录,200B 模型,预期用 1 万块 A100,支撑400 万用户的访问,并可以开始考虑商业化赚钱的问题(https://baijiahao.baidu.com/s?id=1794105501307081465)。同时,QuestMobile 汇报的 Kimi 日活数据,已经到了 300 万(https://xueqiu.com/3708475800/314628967)。
- deepseek 的 V3/R1 是 671B 的 MoE 模型,激活参数是 37B。折算一下,如果 deepseek 的 1 万卡 A100 都用于推理服务,应该能支撑 1500 万日活用户——这比 3 万显然多太多了。所以 deepseek 公司才会觉得推理服务毫无压力,因此没有设计任何限速、计费策略。我猜测可能 deepseek 一开始按 30 万用户的十倍波峰容量准备一个 200 块GPU 的小 k8s 集群而已(我把这个问题提交给 claude 和 deepseek,他们的建议都是先准备个 70~80 块就得了)。
- 在 deepseek 的 V3 技术报告中,曾经提到他们的最小部署单元,是 32 卡 Prefill 集群+320 卡 Decode 集群。官网 V2.5(V3 比 V2 大了两倍) API 计费公告中,曾经提到集群设计容量是 1 万亿——QuestMobile 汇报的 2024 年 12 月数据,智谱清言日活 440 万时,token 消耗正好也是 1 万亿——所以最终结论就出来了:deepseek 公司应该就是预备了一个 352 卡的集群,想着能支撑百万用户(假定 R1 的 reasoning/content = 5:1),已经比实际用户高一个半数量级,绝对够用了。
- 2025-03-01 更新:deepseek open-source week 最后一天公布了[正确答案](https://github.com/deepseek-ai/open-infra-index),他们在 02-27 的峰值是占用了 278 个 H800 节点。根据 token 消耗和缓存命中率推算,应该服务了 4620 万用户、人均 3 轮对话。
好了,今天的分析就到这里。各位看官,是不是比 openai deep research 能输出的报告还是深入一些?哈哈~



