也谈运维智能体的“自进化”
最近腾讯林兆祥的一个分享《Cloud Mate:自进化的排障 Agent 平台》,在运维圈引起了较大的反响和讨论。设计思路从生物学借鉴了诸多概念,非常吸引听众。可惜 Cloud Mate 是腾讯的内部系统,分享里很多设计细节无法公开。
巧合的是,同样是在 2025 Q4 这个时间段,另几篇公开的论文,都不约而同地把目光集中到了运维大模型的知识库优化上,完全可以和 Cloud Mate 相互参照。下面介绍三篇论文。
一、南开/阿里:OScope
阿里研究发现,不同工程师在填写工单文档时,用词习惯差异很大,直接使用向量召回的 acc@1 只有 0.2。若从知识库 RAG 召回的 chunk 都是无关片段,LLM 只会被越带越歪。
OScope 从阿里实际环境选取 157 个历史故障,交给 3 个 OCE 专家进行人工改写、复核讨论,形成 157 个「原始记录 -> 统一语义的标准化描述」的问答对,再用大模型做数据增强,扩大到 1000 对。基于此微调了一个 qwen-8B 的模型,专门做文档语义改写,acc@1 提升到 0.45。
此外,OScope还有另一个设计:当大模型根据标准化文档生成排障 SOP,智能体每一步执行完,OScope 都强制使用大模型验证一次执行内容是否符合 SOP 中对应步骤的描述;不符合则重做。这与 Cloud Mate 中“深度推理:识别当前阶段,提示注意事项”的目的一致。
二、清华/微软:StepFly
微软从 92 份 TSG 技术支持指南文档中,总结影响 LLM 生成排障方案的因素。
- 流程特点:普遍 5-15 步,最多 30 步,其中多含条件分支判断;LLM 容易乱序或遗漏。

- 很多步骤逻辑独立可并行,但现有生成的 DAG 多为串行。
- 文档中约 36% 是 KQL 查询模板,让 LLM 根据模板生成实际查询既慢又不准。
- 文档质量问题(5 类):
- 描述不清晰(37.4%):步骤模糊、判断条件不量化,如“出现少量错误”,少量是多少;
- KQL 模板不准(27.2%):未标清楚哪些是参数,动态参数写死,模型不敢改;
- 数据流不明(20.4%):未说明数据来源或参数不全;
- 控制流不完善(5.1%):未说明结果对应的分支路径;
- 格式结构错乱(9.9%):排版差、章节混乱、不明确终止条件等。
Stepfly 解决方案:
- 查询生成:采用 NL2DSL2SQL 的通用手段,微软抽象了 Query Prepare Plugin;
- 记忆模块:为防步骤过多导致遗忘,设计简单的 agent memory。工具调用把内容存入 MongoDB,仅返回 _id 到上下文;其他工具需数据时再用 _id 取;
-
文档 mentor:针对最核心的文档质量 5 类问题,制定文档规范,手动编写示例注入 prompt,让 LLM 改写 TSG 文档。
- 参考:https://github.com/microsoft/StepFly
三、港中大/华为:iKnow
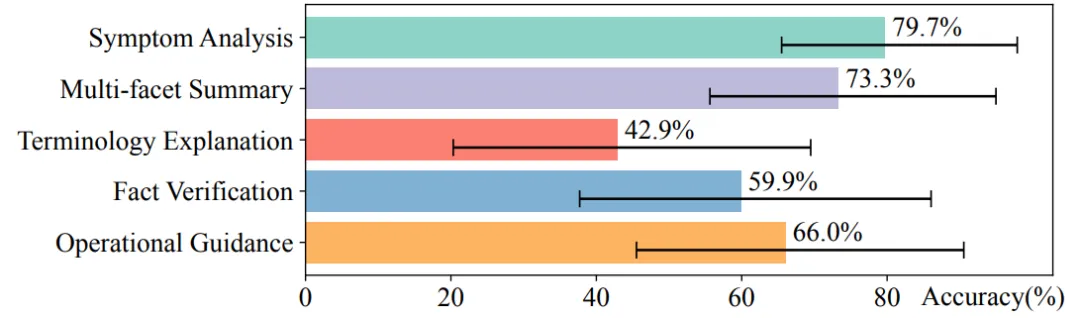
iKnow 研究问题针对华为云产品的问答助手,范围不局限于排障。研究团队基于华为云的2000个问答的会话历史,采用案例研究开放式编码的手段,最终归类为5种问答意图:
- 故障分析(占比最大,40%):如“GPU 报错 Xid 74 错误是咋回事?”
- 多维度总结:如“给我一份 S 产品故障处理的完整指南”
- 术语解释(正确率最低,43%):如“ESN 是啥意思?”
- 事实验证:如“ServiceA 能统计容量吗?”
-
操作指导:如“怎么把 MySQL 加入访问白名单?”
 然后又把683个错误问答,归类为6种核心原因:
然后又把683个错误问答,归类为6种核心原因: - 提问不完整(32%):仅输入关键词(如只写“ESN”),AI 不知道解释还是用法;
- 知识缺失(27%):文档里没有相关内容(如问刚上线的功能),AI 只能瞎编;
- 非运维问题:如“客户 A 的财务情况?”
- 输入乱码/拼写错
- 搜不到相关文档
- 大模型理解错了正确文档
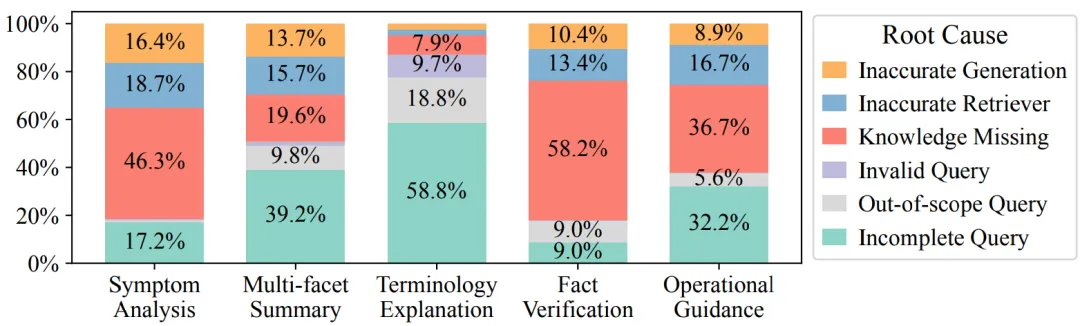 从上图可以看出,术语解释出错最大原因是用户提问太简略;故障分析出错最大原因是文档缺失。
从上图可以看出,术语解释出错最大原因是用户提问太简略;故障分析出错最大原因是文档缺失。
不过华为本文只通过加强query rewrite的手段,解决了前者,并没有解决后者(只是让LLM做个判断,RAG chunk是否和问题无关)。
总结
通过上述三家的进展可以看到,阻碍运维大模型落地的最大障碍,不是新技术门槛,而是运维团队缺乏一个规范、持续更新的知识库。补课路径大致是:
- 制定文档术语规范;
- 用大模型重写历史文档,统一语义;
- 用大模型从群聊记录主动提取新文档,保持新鲜度。
Cloud Mate 中还有诸多创新:如一次故障如何衍生和探索更多 trajectory;一份 SOP 回测的总体影响如何判断是否值得采纳等,期待后续更多细节公开。



