用Devel::NYTProf模块排查优化perl脚本性能
缓存服务器上有一个perl写的日志分析脚本,记录所有不重复的url。之后对squid进行目录刷新时,从记录下来的文件中查找匹配的url即可。
不过这些天服务器老是出现负载报警,用top观察,这个 url_parser.pl 脚本一旦执行时,就占用了高达90%的CPU和40%的MEM。wc看存储的url.list文件,有大概4,000,000行;url.$(date).list 当前有140,000行。
于是上CU去请教perl执行效率的查找思路。
回复有:1、正则精准度;2、文件读取效率;3、全局变量数;4、频繁打开句柄;5、流程优化
比如读取文件不要用 @line=FILE 用 while(<FILE>) ;正则^ 句首,带上 /oi ;注意哈希表与内存交换区等等;最后推荐给我 Devel::NYTProf ,进行测试。
perl -MCPAN -e shell
>install JSON::Any(不安这个东东,在nyt生成html的时候会报warning,不过不安也可以)
>install Devel::NYTProf
然后采用 perl -d:NYTProf /home/purge/url_parser.pl 运行脚本,会在当前路径下生成nytprof.out。
再用 nytprofhtml nytprof.out 生成web页面。
另开一个apache,将生成的nytprof目录发布出来。用ie打开即可看到了,如下:
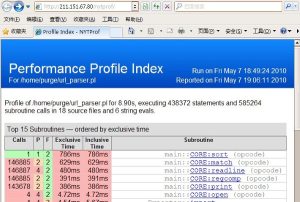
下面还有载入模块的时间。之前我用strace跟踪了一下脚本的运行,发现在载入pm的时候,perl会搜索好多乱七八糟的目录,最后才正确,还一度担心是因为这个原因浪费了时间和资源呢。不过根据测试结果来看,载入模块总共花了不到30ms,不是什么可怕的事情。
然后点击 /home/purge/url_parser.pl 的 reports(line·block·sub),可以看到具体每个语句的执行情况:
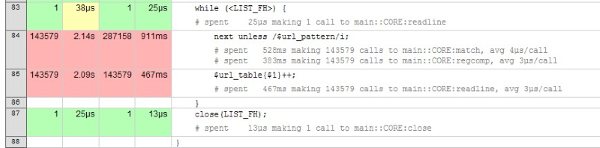
打开十四万行的url文件花了2.14s,然后再用2.09s将它们载入哈希表中;

打开正在运行的access.log(5分钟截取一次,squidclient mgr:5min里rps为17.65,即大概该有5000行以下;结果显示是3306 calls)并截取其中的url,花了141ms,然后再用42.6ms载入哈希表中;

最后,用919ms对哈希表排序,用1.58s重记录整个url文件。
(143677-143579=98,即3306条日志中有98条是新增url)
注意到第二张图中,对access.log分析时,match那步,每行花了30us!而在对urllist和tmplog分析时,每行只花3-4us的样子。看来是这一步的正则写的不好了,如下:
my $log_pattern = qr '^.*?d+s+w+s+(http://.+?)s+.+';
根据日志的格式和需求,改成这样 my $log_pattern = qr 's(http://.+?)s'; 其他不变,再次测试,该部分的测试结果如下:

__降低成7us每行__啦!效果明显呀~~



