kibana 图表类型中有个 stats 类型,返回对应请求的某指定数值字段的数学统计值,包括最大值、最小值、平均值、方差和标准差(当前通过 logstash-1.4.1 分发的 kibana 版本还只支持单列显示,前天,即 5 月 15 日刚更新了 Kibana 3.1 版,支持多列同时显示)。这个 stats 图表是利用 Elasticsearch 的 facets 功能来实现的。而在 Elasticsearch 1.0 版本以后,新出现了一个更细致的功能叫 aggregation,按照官方文档所说,会慢慢的彻底替代掉 facets。具体到 1.1 版本的时候, aggregation 里多了一项 percentile,可以具体返回某指定数值字段的区间分布情况。这对日志分析可是大有帮助。对这项功能,Elasticsearch 官方也很得意的专门在博客上写了一篇报道:Averages can be misleading: try a percentile。
周五晚上下班前,我突然决定试试给 Kibana 加上 percentile 图表类型。因为群里正好携程的同学说到他们仿造 trend 类型做了 stat_trend 图表,我想 percentile 从数据结构到展示方法跟 stats 都很像,应该难度不大,正好作为学习 angularjs 的入手点好了。
花了半天多的时间,基本搞定这件事情,中间几度碰到难题,这里记录一下:
kibana 3.1 中的 elasticjs 版本
这是一个非常非常坑爹的地方,kibana/src/vendor/elasticjs/elastic.js 文件开头写着版本号是 v1.1.1,但是其实它是大半年前(2013-08-14)的。而实际它加上 aggregation 支持的时间是今年的 3 月 16 号,最近版本是 3 月 21 号发布的 ——但是版本号依然是 v1.1.1!!
我在昨天晚上花了一个多小时慢慢看完了 elasticjs 官网上 v1.1.1 的接口说明,结果其实在 kibana3.1 自带的 elasticjs 上完全不可用。
elasticjs 新版用法
随后我替换成了最新的 elasticjs 文件,结果依然不可用,仔细看过文档后发现,新的 elasticjs 只专心处理请求的 DSL,把客户端初始化、配置、收发等事情都交给了 Elasticsearch 官方发布的 elasticsearch.js 来完成。原先版本自带的 elastic-angular-client.js 压根就没用了。
变动大成这样了,居然还不改版本号!?!?
elasticsearch.js 的多层目录
下载了 elasticsearch.js 源码后,发现目录里有一个 elasticsearch.angular.client.js 文件,于是我很开心的想,官方考虑的还是很周全的嘛!然后花了一阵功夫在 kibana/src/app/app.js、kibana/src/app/components/require.config.js 等各处添加上了这个 elasticsearch 模块。结果依然不可用。
原来整个 elasticsearch.js 把功能模块化拆分到了很多个不同的多层次的目录里,然后相互之间广泛采用类似 require('../lib/util/') 这样的语句进行加载。
但是:Kibana 采用的是 requirejs 和 angularjs 合作的模式,整个 js 库的加载过程完全在 kibana/src/app/components/require.config.js 一个文件里定义,你可以看到这个文件里就写了很多 jquery 的子项目文件,但是这些文件都是平铺在 kibana/src/vendor/jquery/ 这个目录里的。
所以,即便在 require.config.js 里写了 elasticsearh 也没用,文件里的 require 语句依然是报错的。而且再往下的压根没法继续添加到 require.config.js 里了,因为太复杂了,肯定得修改 elasticsearch.js 源码的各个文件。
总的来说,就是 elasticsearch.js 不适合跟 requirejs 一起工作。
至此,简单更新 js 库然后调用现成接口的计划完全破产。
感谢 Elasticsearch 本身就是一个 RESTful 接口,所以还剩下一个不太漂亮但是确实好用的办法,那就是自己组装请求数据,直接通过 angularjs 内置的 $http 收发。
aggregation_name 的限制
angularjs 的 $http.post 使用跟 jquery 的 $.post 非常类似,所以写起来难度不大,确定这个思路之后唯一碰到的问题却是 Elasticsearch 本身的新限制。
目前 Kibana 里都是以 alias 形式来区分每一个子请求的,具体内容是 var alias = q.alias || q.query;,即在页面上搜索框里写的查询语句或者是搜索框左侧色彩设置菜单里的 Legend value。
比如我的场景下,q.query 是 “xff:10.5.16.*“,q.alias 是”教育网访问”。那么最后发送的请求里这条过滤项的 facets_name 就叫 “stats_教育网访问”。
同样的写法迁移到 aggregation 上就完全不可解析了。服务器会返回一条报错说:aggregation_name 只能是字母、数字、_ 或者 - 四种。
(这里比较怪的是抓包看到 facets 其实也报错说请求内容解析失败,但是居然同时也返回了结果,只能猜测目前是处在一种兼容状态?)
于是这里稍微修改了一下逻辑,把 queries 数组的 _.each 改用 $.each 来做,这样回调函数里不单返回数组元素,还返回数组下标,下标是一定为数字的,就可以以数组下标作为 aggregation_name 了。后面处理结果的 queries.map 同样以下标来获取即可。
目前效果图如下:
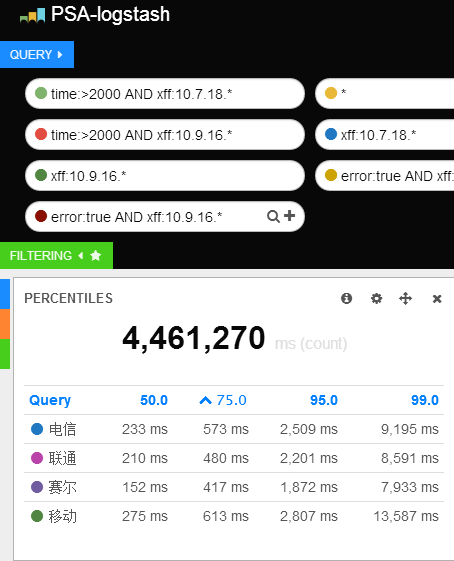
我的改动已经上传到 github 上,欢迎大家一起改进。
目前的问题有两个:图表里的列排序功能不可用,还没找到原因;percents 值还没在 editor.html 里提供自定义办法。
2014.05.26 更新: percents 值已经可以自定义
2014.06.06 更新: 排序功能可用。原因是 elasticsearch 不管你提交的 percents 带不带小数点,返回值里都会保留小数点后一位,而在 sortBy 里头,这个小数点就会被理解成 javascript 里获取数据结构键值的意思。所以收到响应后,用 parseInt 函数干掉小数点就可以了。



