标题说是 PHP 的慢日志,其实所有函数堆栈的调试日志都可以做,比如 Java 的调试日志等等。要用 Kibana ,首先得把日志数据解析并输入到 Elasticsearch 里。所以,本文分为几个部分:多行合并,堆栈解析,Nested Aggs 处理,Kibana4 的可视化效果。
多行合并
堆栈日志显然都是多行的。所以首先需要把多行数据整合成单个事件。之前已经多次写过如何用 Logstash 实现这个需求了。不过,Logstash 这里有个限制,就是必须是在 shipper 段配置才能有用。如果在 index 端,不同 shipper 来的数据顺序已经打乱了,这个合并就没有意义了。
所以,如果日志收集的时候没有用 Logstash 的,这时候就得自己处理了。下面是我写的一个示例:
#!/usr/bin/env pypy
#coding:utf-8
import re
import sys
import time
import socket
import urllib2
import optparse
try: import simplejson as json
except ImportError: import json
from common import grokFpmSlow
defaultLogTag='fpmSlow'
hostname = socket.gethostname()
timeout = 120
def getOptions():
usage = "usage: %prog [options]"
OptionParser = optparse.OptionParser
parser = OptionParser(usage)
parser.add_option("-t","--logTag",action="store",type="string",dest="logTag",default=defaultLogTag,help="default log tag.")
options,args = parser.parse_args()
return options,args
def send_es(data, logtag):
url = 'http://esdomain:9200/logstash-mweibo-' + data['@timestamp'].split('T')[0].replace('-','.') + '/' + logtag
req = urllib2.Request(url, json.dumps(data), {'Content-Type':'application/json'})
try:
res = urllib2.urlopen(req)
print "Return content:",res.read()
except urllib2.URLError, e:
if hasattr(e,"reason"):
if e.reason == 'Bad Request' and data.has_key('jsoncontent'):
data['message'] = json.dumps(data.pop('jsoncontent'))
send_es(data, logtag)
else:
print "The reason:",e.reason
elif hasattr(e,"code"):
print "Error code:",e.code
print "Return content:",e.read()
def flush(log_buffer, grokObj):
data = "".join(log_buffer)
match = re.match(grokObj.msg_regexp, data)
if match:
ret = grokObj.grokData(match)
ret["host"] = hostname
else:
ret = {
"host":hostname,
"message":data,
"@timestamp":time.strftime('%FT%T')+'+0800'
}
send_es(ret, grokObj.logtag)
def get_log(grokObj):
start_time = time.time()
log_buffer = []
while True:
try:
line = sys.stdin.readline()
except:
break
if not line:
flush(log_buffer, grokObj)
break
if line:
match = re.match(grokObj.start_regexp, line)
if match and len(log_buffer) > 0:
flush(log_buffer, grokObj)
start_time = time.time()
log_buffer = []
log_buffer.append(line.rstrip())
else:
if (time.time() - startime > timeout ):
flush(log_buffer, grokObj)
start_time = time.time()
log_buffer = []
time.sleep(1)
if __name__ == '__main__':
options,args = getOptions()
if options.logTag == '':
get_log(grokFpmSlow.fpmSlow(options.logTag))
python 水平很烂,大家看看就好,大概流程其实跟 Logstash 差不多。
堆栈解析
上面的 python 脚本,只是做到根据正则表达式合并多行数据,以及收到处理结果后发送给 ES 集群。具体的处理,则在 common/grokFpmSlow.py 中完成:
#/usr/bin/pypy
#coding:utf-8
import re
import datetime
class fpmSlow():
def __init__(self, _logtag):
self.logtag = _logtag
self.start_regexp = re.compile('^\[\d{2}-\w{3}-\d{4}')
self.msg_regexp = re.compile('(?m)\[(?P<timestamp>\d{2}-\w{3}-\d{4} \d{2}:\d{2}:\d{2})\] \[pool (?P<pool>\S+)\] pid (?P<pid>\d+)script_filename = (?P<slow_script>\S+)(?P<message>\[\w{18}\] (?P<slow_func>[^\[]*?:\d+).*\[\w{18}\](?P<begin_func>[^\[]*?:\d+))$')
def grokData(self,match):
ret = match.groupdict()
ret['slow'] = {k: v for k, v in enumerate(re.split(r'\[\w{18}\] ', ret.pop('message'))) if k > 0 }
ret["@timestamp"] = datetime.datetime.strptime(ret.pop("timestamp"), "%d-%b-%Y %H:%M:%S").strftime("%FT%T+0800")
return ret
类属性中的 start_regexp 对应 Logstash/Codecs/MultiLine 中的 pattern,msg_regexp 对应 Logstash/Filters/Grok 中的 match。这些都是标准的正则,根据日志的实际情况写就好了。
grokData() 方法里,把 message 里存的整个堆栈,首先切割成数组,然后转换成对应行号为键的字典,存入 slow 字段。
也就是说,原本一段这样的 PHP-FPM 慢日志:
[13-May-2013 05:17:12] [pool www] pid 13557
script_filename = /opt/www/inkebook/index.php
[0x000000000292e0f0] commit() /opt/www/inkebook/includes/database/mysql/database.inc:166
[0x000000000292de88] popCommittableTransactions() /opt/www/inkebook/includes/database/database.inc:1128
[0x000000000292dcf0] popTransaction() /opt/www/inkebook/includes/database/database.inc:1905
[0x00007fffe78cc460] __destruct() unknown:0
[0x000000000292c690] execute() /opt/www/inkebook/modules/statistics/statistics.module:73
[0x00007fffe78cc900] statistics_exit() unknown:0
[0x000000000292c208] call_user_func_array() /opt/www/inkebook/includes/module.inc:857
[0x000000000292bf10] module_invoke_all() /opt/www/inkebook/includes/common.inc:2688
[0x000000000292ade0] drupal_page_footer() /opt/www/inkebook/includes/common.inc:2676
[0x000000000292aa28] drupal_deliver_html_page() /opt/www/inkebook/includes/common.inc:2560
[0x000000000292a378] drupal_deliver_page() /opt/www/inkebook/includes/menu.inc:532
[0x000000000292a198] menu_execute_active_handler() /opt/www/inkebook/index.php:21
会转换成下面这样的字典:
{
"pool": "www",
"pid": "13557",
"slow_script": "/opt/www/inkebook/index.php",
"slow_func": "commit() /opt/www/inkebook/includes/database/mysql/database.inc:166",
"begin_func": "menu_execute_active_handler() /opt/www/inkebook/index.php:21",
"@timestamp": "2013-05-13T05:17:12+0800",
"slow": {
"1": "commit() /opt/www/inkebook/includes/database/mysql/database.inc:166",
"2": "popCommittableTransactions() /opt/www/inkebook/includes/database/database.inc:1128",
"3": "popTransaction() /opt/www/inkebook/includes/database/database.inc:1905",
"4": "__destruct() unknown:0",
"5": "execute() /opt/www/inkebook/modules/statistics/statistics.module:73",
"6": "statistics_exit() unknown:0",
"7": "call_user_func_array() /opt/www/inkebook/includes/module.inc:857",
"8": "module_invoke_all() /opt/www/inkebook/includes/common.inc:2688",
"9": "drupal_page_footer() /opt/www/inkebook/includes/common.inc:2676",
"10": "drupal_deliver_html_page() /opt/www/inkebook/includes/common.inc:2560",
"11": "drupal_deliver_page() /opt/www/inkebook/includes/menu.inc:532",
"12": "menu_execute_active_handler() /opt/www/inkebook/index.php:21"
}
}
现在,数据就算处理完毕,可以写入 ES 了。
Nested Aggs
Elasticsearch 从 1.0 版本开始,改用 Agg 替换了 Facet 接口。其中最重要的特性,就是 Agg 可以叠加。还是以本文为例。因为我们只需要对函数做 Terms Agg 计数,所以 Nested Aggs 都是“桶(bucket)”类型的聚合。Elasticsearch 先按照第一级聚合的要求划分数据到桶内,也就是按照 slow.1 的 TopN 划成 10 个桶;然后在这 10 个桶内,按照第二级聚合的要求再划分数据到第二级桶,也就是在前面 10 个桶里按照 slow.2 的 TopN 各自又划分成 10 个桶,以此类推。
Elasticsearch 除了 bucket 类型的聚合还有 metric 类型的聚合。其实,如果一个 Terms Agg 叠加一个 metric 类型聚合的效果,就跟 Kibana 3 里的 TopN query 效果类似。但是 Nested Aggs 即可以叠加 metric 也可以叠加 bucket 类型的聚合,而且还可以叠加不止一次,功能更加强大。另外,Nested Aggs 是一次请求,Elasticsearch 全部计算完成统一返回。而 Kibana 3 里的效果其实是单独请求一次 TopN,然后循环发起 N 次带有 terms filter 的 facet 请求。
关于 Nested Agg 在叠加时候次序的影响,可以参见前不久我翻译的官网博客《kibana 的聚合执行次序》一文,颠倒 terms 和 date_histogram 的叠加次序,需求和结果是不一样的。
效果图
好了,铺垫完成了。终于说到 Kibana 4 里的操作了。
这次用的是 Kibana 4 正式版。也就是改用了 nodejs 的版本。所以,运行是很简单了。如果是下的压缩包,解压开,修改好 config.yml 运行 bin/kibana 即可。如果是用的 git 仓库源码,运行 npm install && npm start 即可。
正式版要求 ES 版本是 1.4.4,如果你是 1.4.0 ~ 1.4.3 的,这几个版本之间没有功能区别,只是那个脚本沙箱的漏洞。可以直接修改 src/public/index.js(源码则是 src/kibana/index.js) 里版本判断那行代码。
Kibana 4 里还会检查 ES 集群的分片状态,如果有 INIT 状态的分片,直接连 server 都不会启动,一定要等待集群完全 green 了才行。这是个很没道理的做法。我只要每个号有一个分片能用,就不影响数据读取啊!碰巧也有这个问题的,可以修改 src/server/lib/waitForEs.js 里的 waitForShards() 函数,直接强制 return 即可。实测完全没影响。
运行起来以后,访问主机的 5601 端口,就可以打开 Kibana4 的页面了。配置索引模式等步骤,这里不详说,可以参见我刚翻译完的《Kibana 4 用户指南》。
总之,在 Discover 页添加一个 query 或者 filter,目的是过滤出来 php-fpm 的 slow 日志数据,完成后保存,命名。
然后进 Visualize 页,添加一个 pie chart。选择 aggregation 类型为 terms。选择字段为 slow.1(如果采用了类 logstash 的template,这里应该用 slow.1.raw 确保函数不会被分词)。然后点击 split slices,继续添加 aggregation,这次字段为 slow.2。以此类推,假设我们一直添加到了 slow.4。
好了,页面右侧出现了最终的效果:
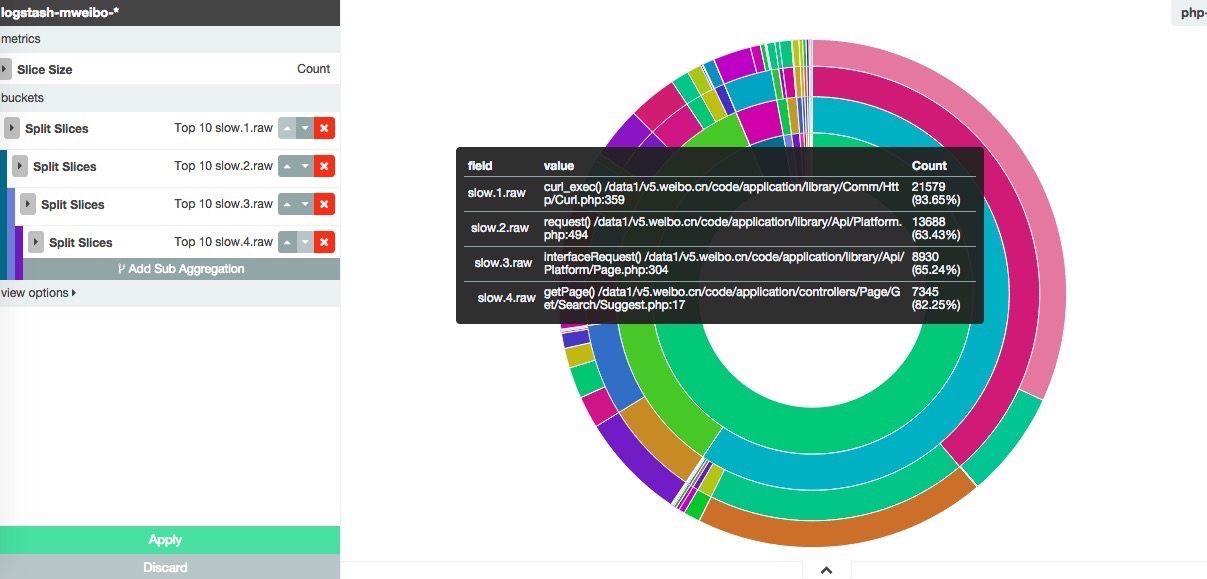
点击保存,输入命名。之后,可以在 Dashboard 页加入这个图片,也可以直接在其他页面里嵌入这个图片。点击 share 图标就可以看到 URL 了。如下:
http://sla.weibo.cn:5601/#/visualize/edit/php-slow-stack-pie?embed&_g=(time:(from:now-24h,mode:quick,to:now))&_a=(filters:!(),linked:!t,query:(query_string:(query:’*’)),vis:(aggs:!((id:’1’,params:(),schema:metric,type:count),(id:’2’,params:(field:slow.1.raw,order:desc,orderBy:’1’,size:10),schema:segment,type:terms),(id:’3’,params:(field:slow.2.raw,order:desc,orderBy:’1’,size:10),schema:segment,type:terms),(id:’4’,params:(field:slow.3.raw,order:desc,orderBy:’1’,size:10),schema:segment,type:terms),(id:’5’,params:(field:slow.4.raw,order:desc,orderBy:’1’,size:10),schema:segment,type:terms)),listeners:(),params:(addLegend:!t,addTooltip:!t,defaultYExtents:!f,isDonut:!t,shareYAxis:!t,spyPerPage:10),type:pie))
这个 URL 设计也是 Kibana 4 的一个重大改进之一。可以看到,基本上大多数设置都在这个 urlparams 里了。这也就意味着,我们其实可以直接修改 URL 来达到快速变换效果的目的。比如,我们现在想看到 slow.5 的效果,只需要在 URL 里加上一段 (id:'6',params:(field:slow.5.raw,order:desc,orderBy:'1',size:10), 就完工了。要改看两天的分析数据,只需要修改 URL 里的 (time:(from:now-2d,mode:quick,to:now)) 就可以了。想恢复编辑页面而不是内嵌图片形式,把 URL 里的 embed& 去掉就可以了。
事实上,掌握 URL 方式非常有用!因为 Kibana 4 中,Visualize 页的字段都是下拉菜单选择的方式,不像 Kibana 3 里是文本框任意输入。菜单选择方式,可以根据聚合的要求过滤不符合要求的类型的字段,一般来说是更方便的。但是:如果你的数据量很大,结构很复杂,可能这个下拉菜单你滚轴滚上几十秒都找不到想要的字段(因为需要提前准备好字段的细节,Kibana 4 在初次访问的时候会从 ES 下载当前索引模式下整个的字段映射数据/_mapping/fields/*,字段一多,这个数据就很大,又要保存在浏览器内存里,可以想象浏览器会多卡)!我的实际环境中,有 22000+ 个字段,映射请求的响应体大小高达 70MB,最后只好放弃在菜单里寻找需要的字段,随意选了一个,然后在 URL 里改成自己要的……
btw: 以上在 safari 上正常完成,在 chrome 40 上有 “Maximum call stack size exceeded” 报错,尚不知道根源。



