从上一篇提到的《软件学报》上的综述文章开始,这段时间顺着引用又陆续看了一些日志管理方面的论文。这里摘录一些论文的数据和结论,还都挺有意思的。
Examining the stability of logging statements
分析了activemq、cloudstack等4个著名的apache开源项目。发现:
- 20%-45%的打日志代码,后续变更过;且初次变更的时间点一般在代码添加以后的17天内;
- 在选取的14个特征值中,对打日志代码是否会变更,影响较大的特征值主要是:开发人员的经验、源文件长度、日志语句占源文件的比例。
- top3的开发人员,负责了全部打日志代码的50%以上。而且这3个人写的打日志代码,70%以上后续不用再修改。
- 如果一个源文件里75%以上内容是同一个开发人员写的,那他写的打日志代码后续基本不会再改了。
不过,这篇论文的出发点,是建立一个分类预测模型,哪些日志代码后续不会改的,让日志分析工具只关注这些日志的解析处理,减轻运维人员频繁变更提取规则的工作量——这个设想是否成立,我个人持怀疑态度。
Studying the characteristics of logging practices in mobile apps: a case study on F-Droid
分析了F-Droid平台上的1444个开源安卓应用代码,发现:
- 平均每479行代码里有一行是打日志,这个比例远低于服务端程序的情况。
- 34%的日志是Debug级别,27%是Error级别。这个比例远高于服务端程序的情况。
- 35.4%的日志,其输出级别和原理含义并不相符——这段似乎是采用调研而非源码分析的情况。
Studying and detecting log-related issues
分析了HDFS、YARN等大型开源软件的jira情况,发现:
- 78%的情况下,修复打日志代码的人不是原先写这行代码或这段函数方法的人;
- 平均一个错误的打日志代码被报bug需要320天,但是修复只需要5天。
此外,论文还利用日志文本的香农熵等做了一个log checker,给出是否level合适、log合适等建议。
Characterizing logging practices in Java-based open source software projects – a replication study in Apache Software Foundation
分析了21个java开源程序,也都来自apache基金会。发现和过去针对C/C++开源程序的论文相比,有一些不同:
- 出于意料的,报bug时带了原始日志的平均花17天修复,报bug时没带原始日志的反而平均只花14天修复。——如果按类型区分,服务端程序情况更明显,客户端程序还是带日志的更快点。
- 带有日志修改的变更,占代码变更的比例,服务端程序高达27.3%,客户端大概18.1%。
Log Clustering based Problem Identification for Online Service Systems
从微软PB级日志环境得到的几个特点总结:
- 大规模IT环境下,因为容错机制的存在,即使在正常运行状态下,也会有大量的kill和fail关键字日志输出。
- 相比传统环境,互联网设施上,相同错误会海量重复触发(restart优先、集群环境等)。
- 导致同一种故障的执行路径有很多种。中间会混杂很多正常时期也输出的日志。
利用日志聚类,在测试环境得到日志执行序列集合,然后和生产环境的做对比,只关注有变化的部分,能节省大概86%~97%的查阅量。2016年的本文,在原先的2013年的方法的基础上,再加上了Check Recurrence,对已经发生和标记过的故障路径,可以直接利用。
最后结果,微软的一个实例,1kw原始日志,通过关键字搜索命中20w条,通过聚类得到40个序列。
Characterizing and Detecting Anti-patterns in the Logging Code
分析activemq、hadoop、maven的源码,找出不合理的日志代码。并以此模型工具,向top10的开源项目提交了学习出来的问题,有72%被最终接受了(其中,jEdit作者否决了所有问题,表示别拿你们的工具结论来打扰我)。
之前多数分析日志代码优化的,都集中在在what、where to log,本文研究的是how to log。首先要基于how的目的,人工分析日志代码的变更分类,得到如下总结:
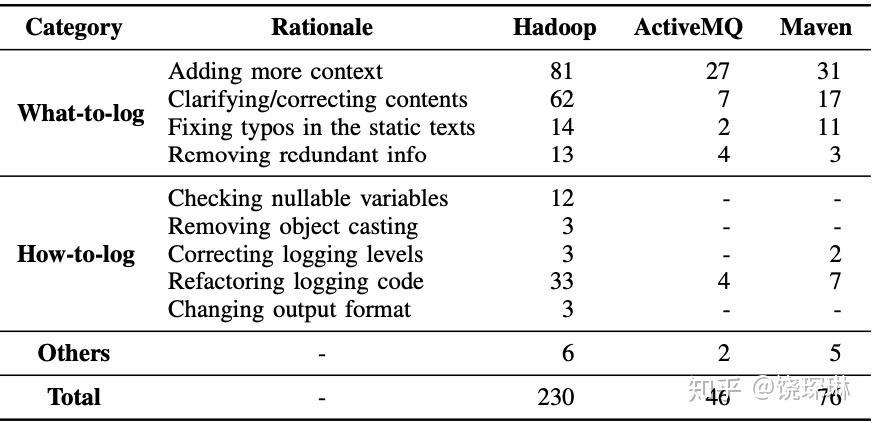
基于这个人工总结,设计了一个工具做自动分析,能分析源码中的5类日志代码bug:
- 引用了可能为null的参数
- 可能出错的类型显式转换
- 和内容文本不符合的日志等级,比如文案写debug,级别却是INFO。
- 日志代码坏味道,包括:相同目的用更长名字的方法、明明有本地变量了还再调用一次方法等
- 畸形输出,比如缺少tostring等。
Log2: A Cost-Aware Logging Mechanism for Performance Diagnosis
Log2是微软做的一个类似logger或者说log4j一样的库,解决whether to log问题。不过优化的方向只专注在一个场景,就是为了check某个函数的处理性能,大家经常在调用这个函数之前写一行begin日志,之后写一行end日志。
同样有性能监控目的,文中提及谷歌在2010的Dapper论文中一个数据:当打开全部日志输出时,谷歌搜索引擎服务的响应时间增加了16.3%,吞吐量下降了1.48%。
微软亚研为了这个项目,还提前做了一次内部的问卷,其实针对IT运维方向的问卷调查法还挺有意义的。运维关注的服务质量管理本身就有一部分管理学性质(虽然管理学领域的服务质量管理偏向纯服务业)。
log2的原理其实就是在库内部维护两层可以动态调整的filter。
第一层是针对每个函数的,根据历史数据评估这个函数的end-begin时间大致范围(主要就是是平均值方差了,这块量大,要高效),如果新执行的情况属于正常的,其实就可以不记录日志了。
第二层是总的缓冲队列,根据队列状况(预定义阈值,比如1s钟最多刷1KB),决定flush哪些日志到磁盘(使用增强学习算法做打分,判断队列里哪些日志对函数性能影响大,优先打哪些),以及给第一层过滤器发信号开启过滤。
其实在有eventid/functionname和duration的前提下,即使不用库,而是ETL方式,应该也可以运用这套原理。
Characterizing the Natural Language Descriptions in Software Logging Statements
本文采用自然语言处理技术研究日志代码的固定描述文案部分。发现:
- 相比于普通的英文文章,日志文案更容易被预测;
- 但是不同项目之间的N-gram模型是不通用的;
- 甚至相同项目中,不同源代码文件之间的N-gram模型大多也是不同的。
DLFinder: Characterizing and Detecting Duplicate Logging Code Smells
本文分析了Hadoop、CloudStack、ElasticSearch 和 Cassandra 源码。专门针对重复日志现象。

话说,ES的日志代码比例还真是偏少啊。
重复日志现象分为5类:
- 同一个try里不同catch打了一模一样的日志文案
- 相同函数背景和相同文案,用了不同变量
- 内容和函数不统一
- 相似场景下,用了不同级别
- 相同方法的不同实现,用了重复日志。
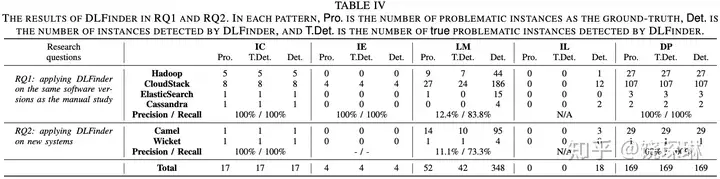
可以看到,主要就是第3和第5种bug比较多。说白了,就是研发写代码的时候,从别处复制过来,忘了对应改细节的情况……



