之前写日志异常检测的文章比较多,今天稍微有空,写写指标异常检测吧。
指标(又叫metric、timeseries、KPI)异常检测,其实是AIOps目前最成熟的领域——当然这个成熟也是相对的。有大把的算法和研究可以看。最常见的几个选择,应该就是holt-winters、KS test、iForest了。
当然,在经典算法的基础上,加强预处理,加强迭代投票等等步骤,衍生出来一系列扩展算法,这部分就是大家各显神通的地方。比如雅虎的egads上adboost、百度的opperentice上randomforest、阿里的donut上VAE、腾讯的metis上xgboost……
只是各显神通的另一个说法,就叫:谁都不是万能的。
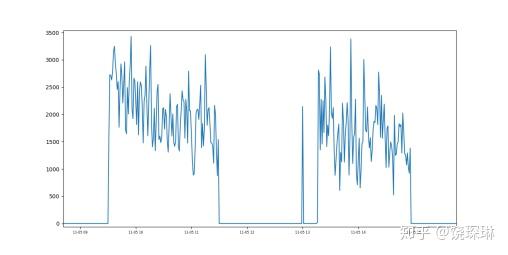
比如上面这种指标,对VAE算法就非常的不友好。我司的算法小伙伴们,在处理这种边界状态时,突然想到可以引入KDE算法,一顿捣鼓下来,效果居然还不错哦。于是再普及到一般指标上,发现结果也不会太离谱。
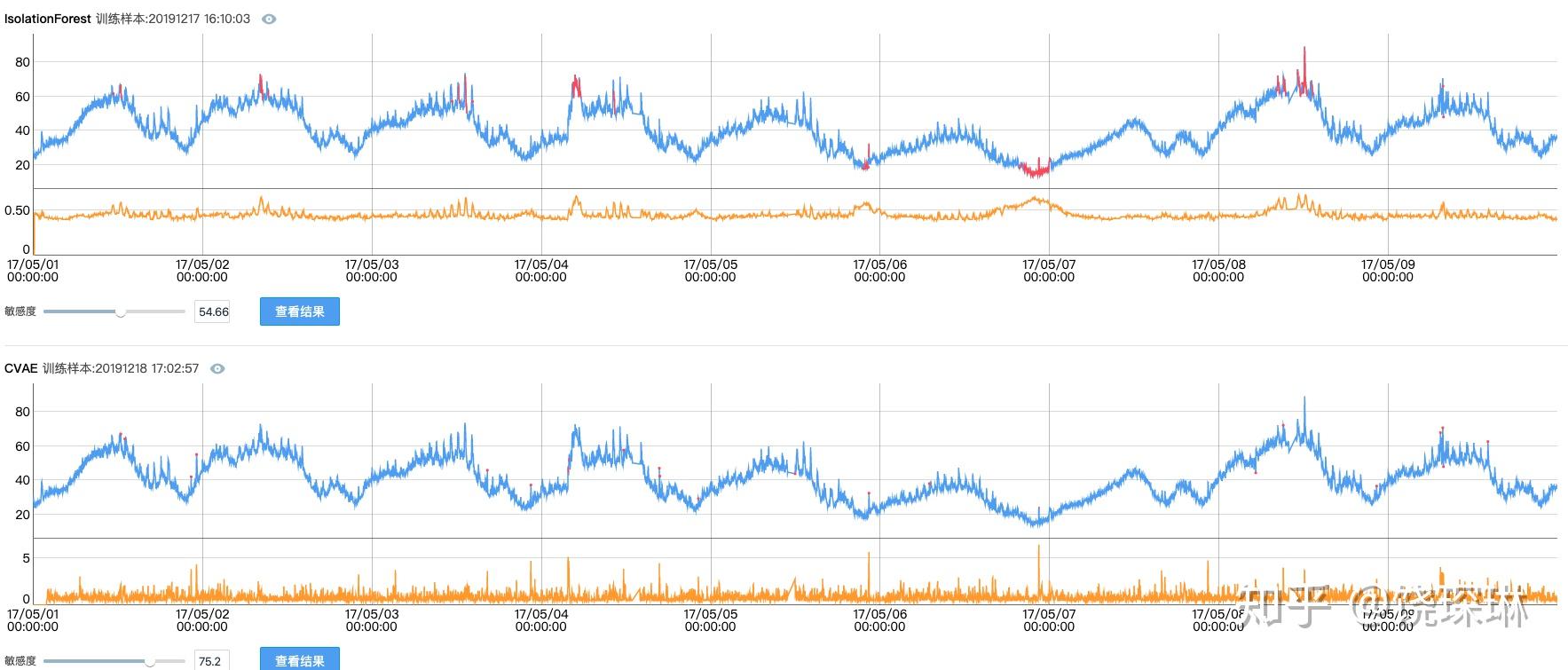
下面用iops.ai去年大赛的某个训练数据做一下演示(当然我司线上产品还有一系列优化,这个敏感度也是自动识别得到的):
本来这事儿也就过去了。毕竟在一些业务指标上,VAE依然是更优选择。
不过在刚刚过去的 splunk conf19 大会上,来自不同国家客户的 ITSI 分享中,居然不约而同的纷纷提到,他们使用 splunk Machine Learning Toolkit 自带的 DensityFunction 算法来进行指标异常检测。我心想,英雄所见略同啊?
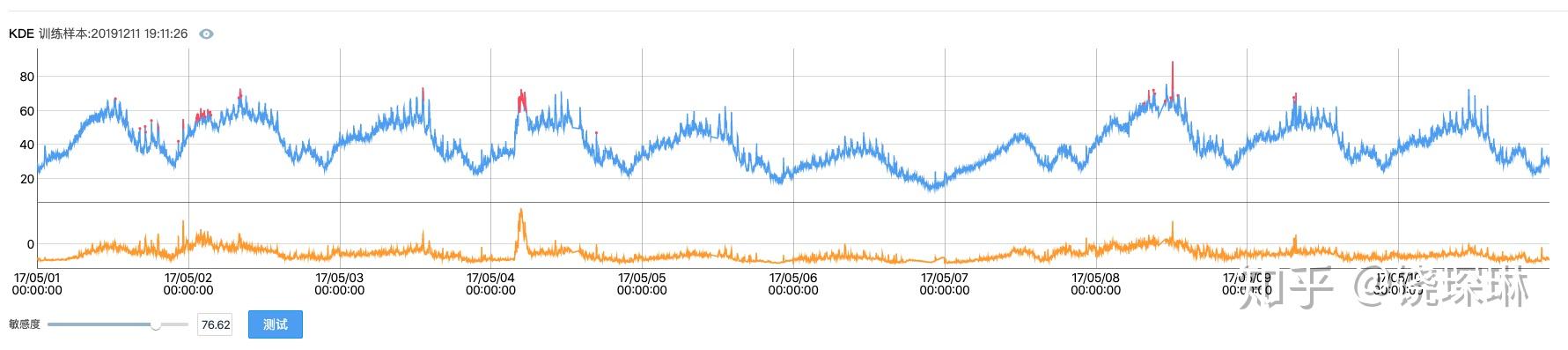
于是今天有空,在本机环境上,使用 MLTK 标准算法库和 SPL 指令,来实现以下我司 KDE 检测的效果。如下图所示:
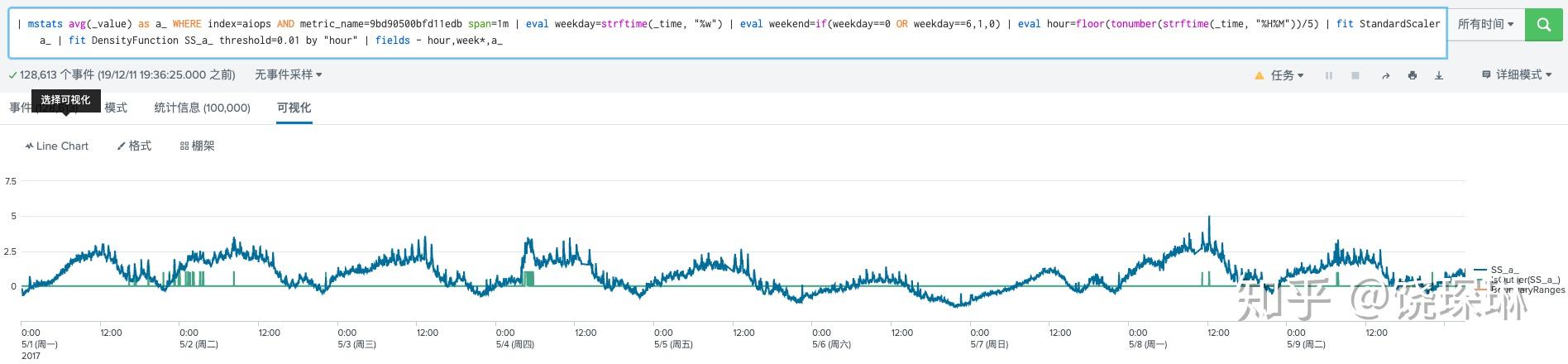
这里直接使用 SPL 来进行数据的预处理和时间特征的提取工作:
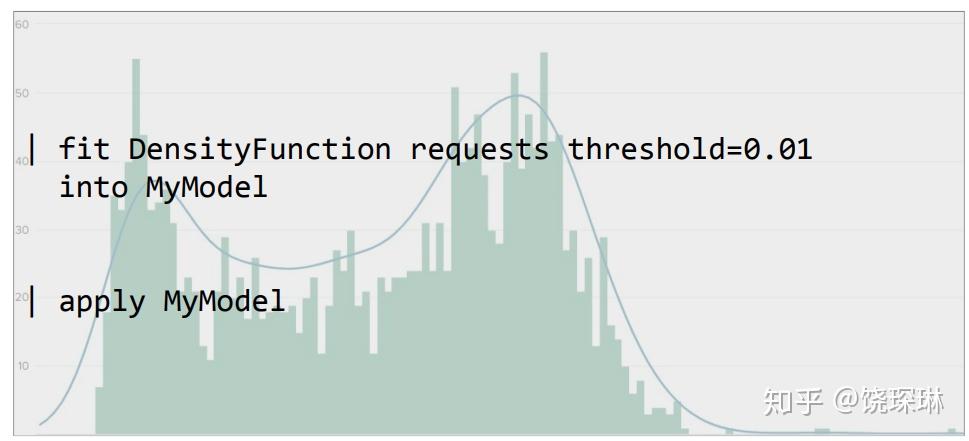
eval ti=floor(tonumber(strftime(_time, "%H%M"))/5),即将时间按每小时的5分钟间隔做一个分组——splunk conf分享里都是用的hour特征,但是这也太粗暴了,以互联网业务来说,早晚高峰的时候,一个小时已经千差万别了——所以我们的想法是要缩短这个集合,每天的时间按5分钟分组,假如7天的训练集,每个小组就是35个数据点,差不多刚好达到统计学意义上估算数据分布的数据量要求。eval weekday=strftime(_time, "%w") | eval weekend=if(weekday==0 OR weekday==6,1,0),为了体现工作日和周末休息日的区别,再提取一下是否工作日的特征。fit StandardScaler a_对原始数据做一个标准化。- 最后以ti和weekend分组,进行 DensityFunction 训练,设定阈值参数为 0.01:
fit DensityFunction SS_a_ threshold=0.01 by "ti,weekend"
就得到上面截图的效果了。仅从肉眼来看,效果差不太多。
当然了,采用 SPL 来实现 KDE 异常检测,这个 threshold 还是要自己调整的,想达到日志易自动选择最佳敏感度的效果,还需要很多其他工作。以后有空再写吧。
20191216注:今天看SREcon的分享,发现百度也用KDE做延迟和吞吐量的异常检测。slide见:https://www.usenix.org/sites/default/files/conference/protected-files/sre19apac_slides_chen_golden_signals.pdf
和国外相比,国内很少有日志产品的最终用户,会自己尝试编写复杂 SPL 语句来实现高级分析。所以我们尽量在公开数据的基础上,封装好算法成为直接可用的功能。有兴趣的读者,可以自己试试,下面这两个算法检测的过程,用 SPL 又该如何写呢?