《AIOPS2020 工作坊白皮书》小记
今天看到 AIOPS 2020 工作坊的网站和白皮书,才知道原来去年有这么个会议(虽然提前知道了也没啥,除了做 keynote 的裴丹教授和吕荣聪教授两位大佬,其他的应该都是外国人,我这英语听力也是废)。看白皮书内容,主要分为两部分,一个是基于文献分析 aiops 在学界过去这些年的趋势,一个是会议收的论文的简介。从论文看,研究的问题都蛮有新意的,今天在这也摘录一番。
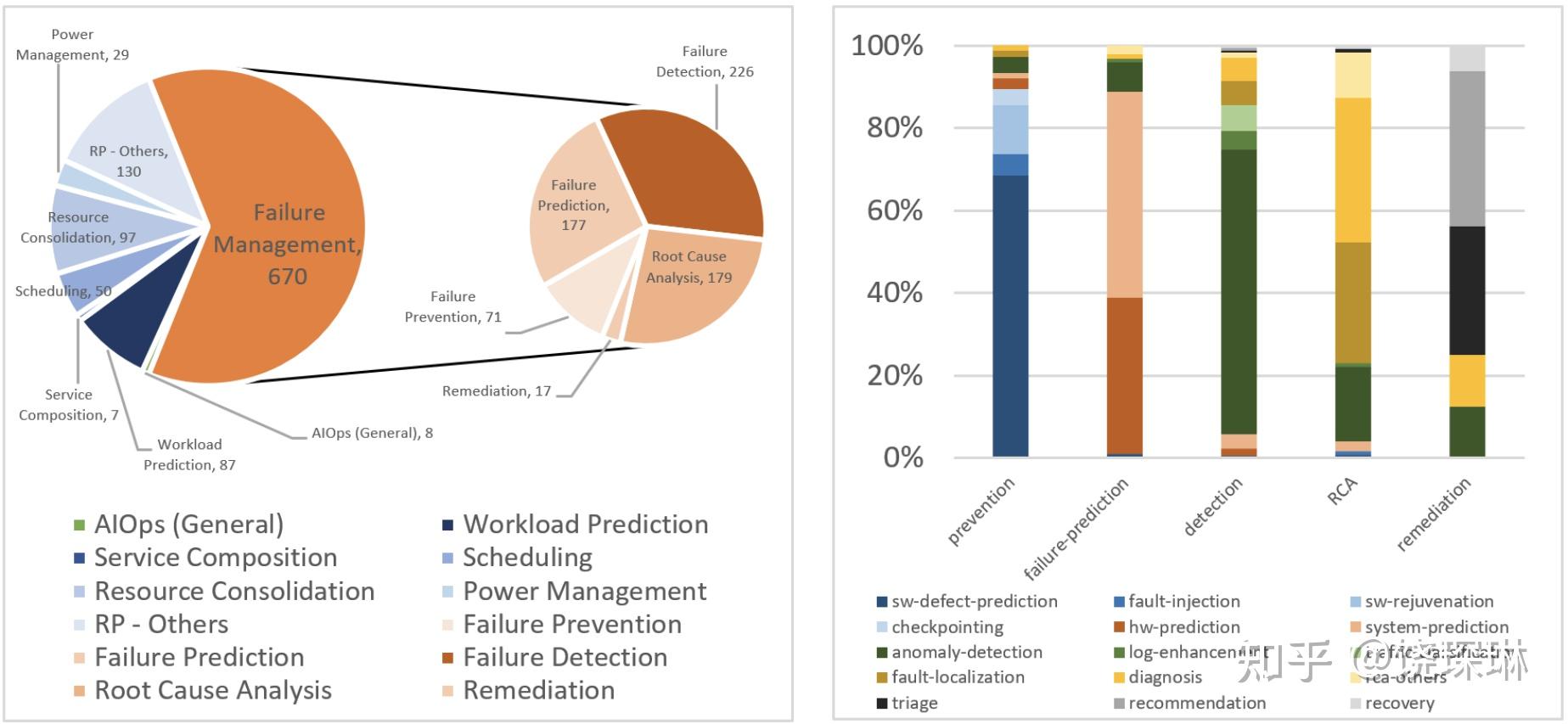
首先是一段 aiops 研究领域分类的热度分析。基本上可以看出来:
- 大多数研究也还是集中在故障方面。
- 故障方面,检测、预测、定位基本三分天下。
- 预防方面,从右侧细分领域可以看到基本是在软件质量方面,也就是算法找 bug。
至于故障管理以外的部分,啥叫 service composition,啥叫 resource consolidation,我还真是百度了一下才知道,大概前者是 SOA 的概念,后者是 IaaS 的概念,和scheduling、workload prediction 这些一起,应该都属于资源规划调度类。可能学界的 AIOPS 定义比较广泛,约等于 Narrow AIOps + Bug + CloudCompute 吧。
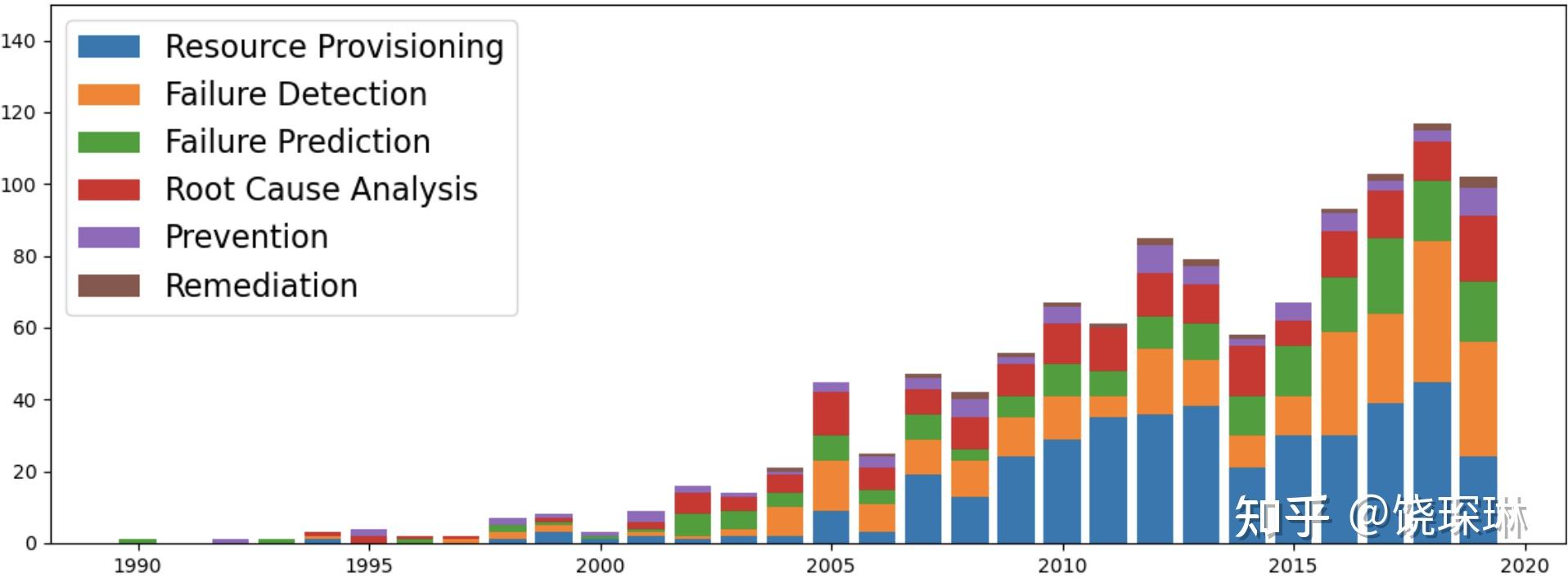
然后我的猜测从后续另一个 aiops 研究领域的趋势分析也能得到一些验证。这个图里的 resource provisioning 大抵就是我上面说的资源规划调度,可以看到大概从 2007 左右至今十多年,论文数量是持平的。近五年显著增多的,就是故障检测方向。
第二部分,就是大会本身这次收的论文。也是主要在异常检测和故障定位两块,以及另外两篇其他领域的。
异常检测领域,收了7 篇,接近一半。其中:
- 有方法创新的。
- 指标方面的有:采用图神经网络;也有干脆走回统计学,用概率分布的,用鲁棒性四分位配合矩阵画像算法的。注意,后两个都是用的 numenta/NAB 测试床,应该是针对 CPU/mem 这类设备指标的。白皮书的结尾总结部分也提到了 aiops 领域公开数据集的缺乏是重大问题。即使同为运维领域单指标异常检测的数据集,NAB和裴教授 iops.ai 的也大相径庭。
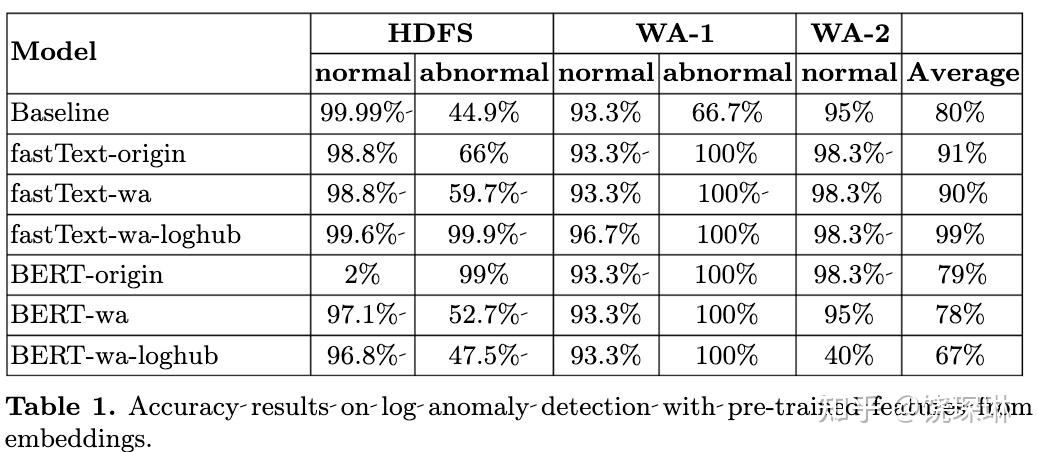
- 日志方面的有一篇 IBM 的,用纯 NLP 手段构建日志异常监测模型。研究分别用 fasttext 和 BERT 两种方式,然后用通用词库、IBM 私有某服务日志和 loghub 开源的一个 hdfs 日志样本,分别训练模型并对比效果。结果如下图,可见,添加一些日志样本就可以迅速提高基于 NLP 的模型的检测能力。但也有一个有趣的例外,就是 BERT-wa-loghub——给 BERT 同时喂 wa 和 loghub 日志样本后,效果反而下降了——作者猜测可能是日志里能出现的单词其实比维基百科来说小太多了。国内我记得最近也有做日志异常的在尝试通过通用 NLP 模型加强预处理部分,不过没有 IBM 这个尝试这么激进。
- 有综合设备指标、调用链和日志三种数据进行微服务异常检测的。
- 有专门针对虚拟机内存溢出场景的。
故障定位领域,收了 4 篇,两篇是网络环境,两篇是微服务环境。可见故障定位在没限定场景的情况几乎不现实。
微服务的都比较简单易懂,毕竟微服务都会有 opentracing 数据,由此可以得到服务间的调用拓扑,事务的黄金指标和服务日志。然后加上容器主机级别的性能指标。剩下的主要是如何挑数据和推理了。收录的论文中,就有一篇是专门挑错误黄金指标和错误日志频率。
网络环境的有一篇是华为 2012 实验室的,作者写了博客:Discovering Alarm Correlation Rules for Network Fault Management (video),里面有演讲视频。我看到在效果评估那页有如下表格:

乍一看,620w 条告警压缩到 59w 条,压缩率好高啊。再一看,预处理阶段做简单的重复连续发送合并就已经只有不到 100w 条了,也就是其实 压缩率大概是 40%。有明确网络拓扑的情况尚且如此,告警归并有多难,可想而知。
最后说另外两个其他方向的。一篇是运用Artificial Swarm Intelligence来实现公有云租户间资源复用最大化。一篇是利用去中心化的联邦学习来提升 deeplog 日志异常监测算法。这是我第一次看到 aiops 和联邦学习在一起出现。按照论文所说,8 个 HDFS 集群上独自训练的模型,在经过联邦学习后,F1-score 从 0.52 提升到了 0.938。但是联邦学习在 aiops 上的运用场景,本身需要思考。除了公有云厂商,可能没多少公司会有一大堆异地集群吧。



