微软亚研新发了一篇日志分析有关的案例研究。受访者是微软下属的各产品线码农们,包括问卷和访谈两种数据,我们可以从中看到,以微软这种世界顶级的软件/云厂商,其内部的日志分析现状。论文见:An Empirical Study of Log Analysis at Microsoft (acm.org)

可以先看看问卷的问题。应该说设计的中规中矩吧。受访人画像、日志画像、使用现状包括一些梯度选择,然后还有开放性的展望问题。
问卷的发放,包括系统抽样方法,主动联系各产线的技术 leader 们下发链接;也包括定向往微软内部论坛的 SRE/AIOps/Observabiliy 主题下发帖。并附加让参与者滚雪球式转发。最后 2k 份问卷里收到了有效回答 105 份,以 SRE 和 SDE 为主,也有 PM 和DS ——这个数量做问卷也就差不多刚达标吧,可见在 IT 领域搞访谈案例真的还挺费劲的,码农不爱搭理人!
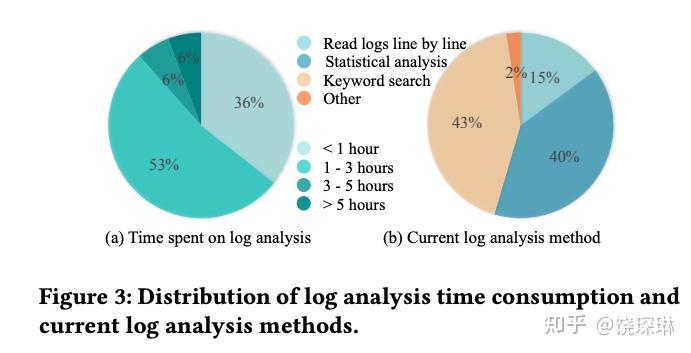
有些结论还是蛮有趣的。比如说:即使在微软这种顶级互联网公司里,日志分析的方法,也是超过一半以上就是关键字搜索和一行一行看。大概只有 2%会超脱于 sum/avg/timechart 之上用更复杂的 ML:
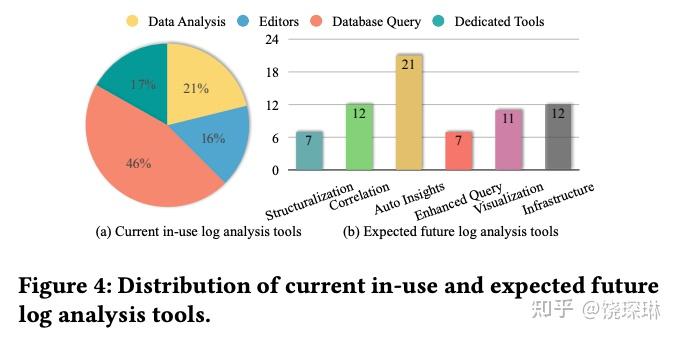
还有就是现状和未来期望,同样也是严重不匹配。还有多达 35% 的人是用文本编辑器或者微软事件查看器来看日志呢,但是大家期望都是各种 AI 自动化(自动结构化、自动提示等级、自动找最关键的行):
至于分析过程中的痛点,因为是开放性问题,论文作者是通过文本编码得到的概念类属,表格如下:

论文里也引了个别访谈原文语料。这个归类我个人其实是有其他看法的。比如原始语料“there is too much information to read, and it is often hard to find the key point”被归入“too many logs”类,用来分析“whether to log”技术。而我更愿意编码为“hard to find”——从某种角度来说,当前日志分析技术也确实缺乏“主动式”的语义分析,没有基于知识图谱的联想和推荐能力。
另外,从扎根理论来说,理论抽样要点是不遗漏,并不在意概念编码在案例中的次数,因为你案例研究的范围终究是有限的。所以上表中 17/18 和 4/5 的差别并不能明确的指导我们应该优先考虑解决什么问题——当然论文作者本身后续分析并没有依赖这个,这段话是写给我亲爱的读者们不要误解。
论文后续的分析见仁见智,读过过去一些相关 survey 的人来说也没有太大的惊喜,我就不再继续摘录了,有兴趣的读者自己看吧。



