ChatGPT 已经火好几个月了,因为没有开源,所以我先试过 stable-diffusion AI 画图以后,最近才排上空闲时间,来试试到底威力如何。
有 sd 的经验,已经知道这一代 AI 最主要的是 prompts engineering 了。那上手肯定是先去 http://github.com 找一把 awesome chatgpt prompts。没问题,还有中英双版——注意中文版有些已经失效了,ChatGPT 对法律的严格遵守现在卡非常死。
看 awesome 发现,有人用来做 SQL terminal,有人用来做 Solr standalone!有意思,那试试看,能不能让 ChatGPT 做个仿真的日志分析服务器?
(题外话:很遗憾,ChatGPT 不知道啥是“日志易”,所以我们还是从 splunk 开始吧)
我们先想好,一个基础的日志分析服务器需要什么功能呢?
- 能接受日志文本,并带上一些基础的半结构化字段,比如主机名、文件名、时间戳。
- 能查询日志,包括过滤和统计。统计包括分组统计和时间趋势统计——但这个我们就不要声明了,看看 ChatGPT 是不是知道。
- 能分系统分类型存入不同索引。
好像就这些。
按照这个思路,参照一些前人经验,我写下了第一段 prompts:
I want you to act as a Splunk Platform running in standalone mode. You have an exists index named “main”. You will be able to add inline JSON documents in arbitrary fields and must have “host”, “source”, “sourcetype”, “_time”, “_index” and “_raw” fields inside. Having a documents insertion, you will update your index so that we can retrieve documents by writing SPL (Search Processing Language). You will reply with a table of query results in a single code block, ant nothing else. Do not write explanations. Do not type commands unless I instruct you to do so. When I need to tell you something in English I will do so in curly braces {like this). You will provide four commands in a numbered list. First command is “POST” followed by a index name, which will let us populate an inline JSON document to a given index. Second option is “GET” followed by a SPL script. Third command is “create” followed by a new index name. Fourth option is “LIST” listing the available indices. My first command is ‘LIST’.
敲下回车键,看看如何:
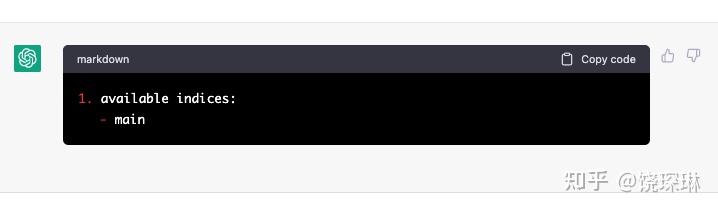
嗯,最简单的 LIST 果然没问题。什么 exists 和 available 啊,index 和 indices 的差异都完全不 care。
下面开始写入JSON数据。这里我玩了个小花招——prompts 声明了 ”must“ 有 6 个字段,但我偷懒(才不说其实是完整 JSON 敲完断网的意外),只提供最基础的 “_raw” 原文,看看会如何:
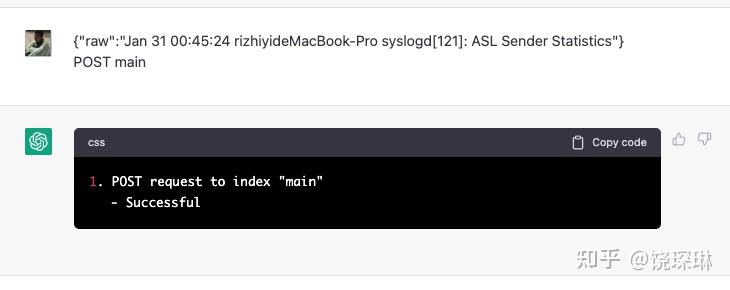
哎呀,可惜啊——ChatGPT 并没有按照我的”must”期望,拒绝掉这次写入——看来prompts 里还得声明好异常处理。
但这时候我好奇了。既然他非要说 Successful,那我就查一下看看?
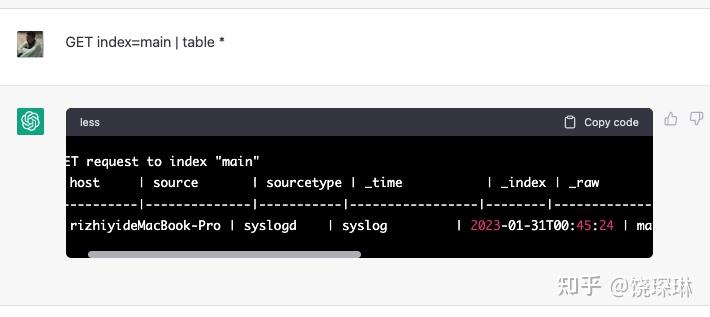
奇迹出现了!!!
是的,返回的结果里,6 个字段一应俱全,都填充好了字段值!
再仔细看看,三大亮点:
- host、source、_time这三个字段,正是从我提供的那行 _raw里提取出来的,
- 很友好的对 _time 值做了 human readable 转换。
- 最后还根据 source 为 “syslogd”,推断了 sourcetype 为 “syslog”。
实在是太惊喜了!!!
好了,收拾一下激动的心情,让我们再试试看统计需求:
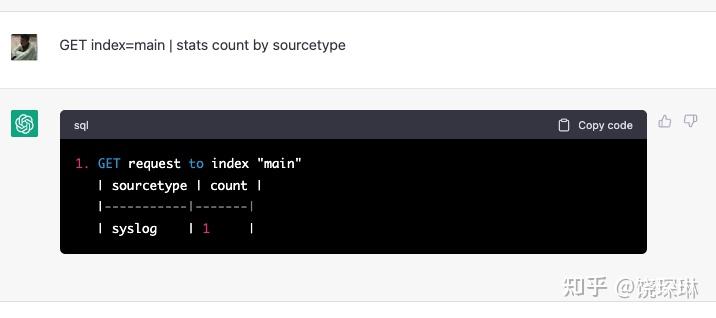
没啥问题。再看看不明确指定索引呢:
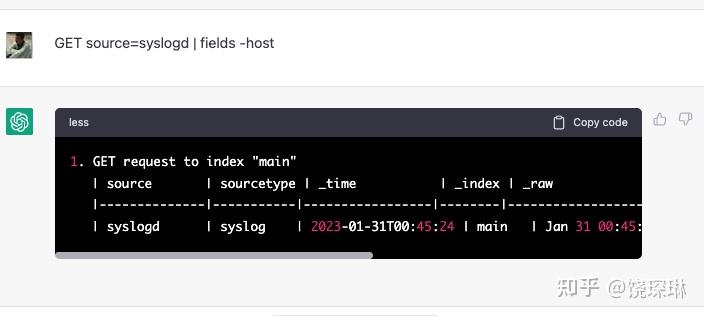
也知道走默认 main 索引。
那最后一个常见需求,时间趋势图。先让我再 po 一条日志,然后试试看:
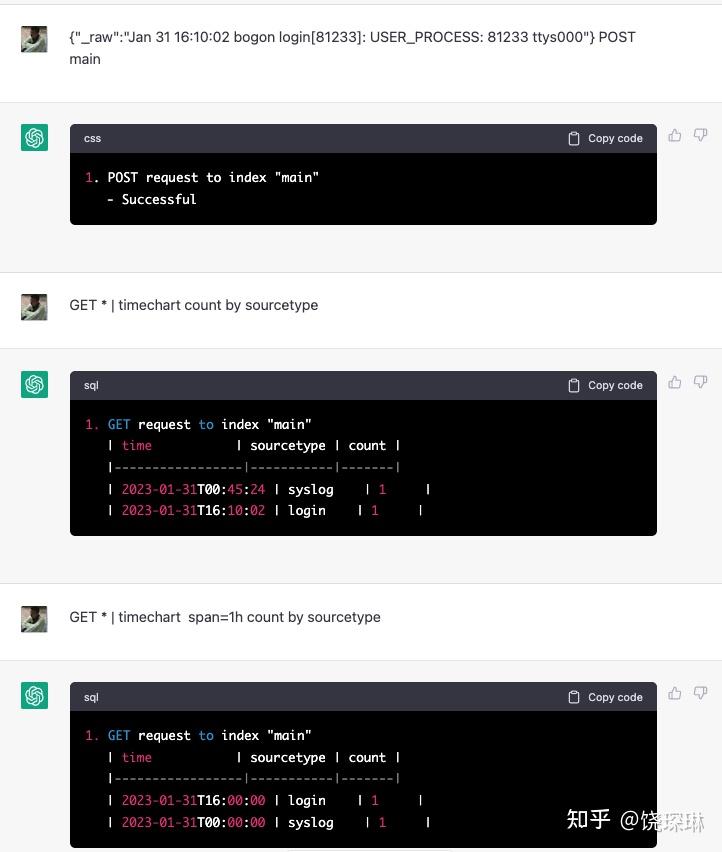
这次终于体现出ChatGPT只是一个语言模型的缺陷了——SPL 里的 timechart指令有一套比较复杂的 autospan 默认值计算,所以直接写 timechart count 语句时,ChatGPT 无法知道默认计算逻辑,只能输出两个原始时间。只有我们明确指定 timechart span=1h count语句时,ChatGPT 才知道这是要按小时统计。
好了。第一次尝试到此为止。ChatGPT不愧是个优秀的语言模型,自动 NER 提取主机名和 infer 日志类型的表现真是惊艳了我。期待后续尝试的表现~~



