越来越多的人开始尝试使用 ChatGPT 了,随之而来的是一些质疑的声音:“感觉 ChatGPT 没多厉害啊?这也不会那也不会……”这其实很正常,所有新技术在成熟运用之前都要经历类似的炒作曲线。恭喜大家进入冷却期,也就是要开始真正掌握这门技术了。
就像吃东西先问“能、好、怎”一样,我们面对一个场景,也可以先问第一个问题:能不能用 ChatGPT?
ChatGPT 模型的本质,是逐字按概率预测。“逐字”的关键作用,后续讨论“怎么用”时再强调,今天先说“概率”。概率就意味着会出错——所以“能不能用”,主要就是看出错我们接不接受。
大语言模型领域有另一家很著名的初创公司 cohere。其联合创始人 Yunyu Lin,著文讲解他认为最合适大语言模型的三类场景:
- There is no one correct answer (creative applications, summarization)
- There is some tolerance for error (routing, tagging, searching, and other tasks where perfection isn’t required)
- The answer can be easily verified (math, writing code for specific tasks, or human-in-the-loop use cases).
这三句话强烈推荐给所有朋友反复阅读!我们也可以取个反,什么是“不能用 ChatGPT”的场景?那就是:对错定义严格的,出错影响太大的,而且不容易判断对错的。
示例
给大家加深一点印象,演示一个 ChatGPT 极具迷惑性的反例。
几天前,我在阅读 elasticsearch的官方说明文档的时候,看到一系列相关性参数,用的都是缩写,讲的不明不白的。我去尝试问问 ChatGPT,这些缩写是什么意思?取值区间是多少?具体强相关弱相关的阈值点是什么?ChatGPT 一一作答,看起来非常完备:

但事实上,ChatGPT 不管是取值范围,还是强弱阈值,全说错了!JLH 和 GND 都不是 0-1 之间。GND 的强弱点也不是 0.5,而是 1。
如果不是多个心眼,又去 Wikipedia 上搜了一遍,绝对就被坑了——但如果没有 ChatGPT 先把缩写解释出全名,直接上 Wikipedia 可能都不知道搜什么。
总结
我们来对照一下 cohere 的三原则,看看这个场景“能不能”用 ChatGPT:
- 对错定义是不是严格唯一:是的。数学概念毫无歧义。
- 出错是不是大事儿:是的,相关性搞反了,产品给用户推荐的内容都是错的,会造成直接业务损失。
- 错误容不容易判断:个人感觉不容易。相关性算法太多了,哪怕专业算法同学也不一定接触过所有知识。
这么一分析,结论就明确了:这个场景不能用 ChatGPT——至少不能只用 ChatGPT。
细心的读者可能注意到,我在第三条强调了“个人感觉”。因为 cohere 这三条原则中,前两条都很难改变。唯一可变的,是判断对错的“容易程度”,这一条因人而异,你越是懂的领域,这个 AI 助手可能越是得心应手。
同时,这也是 New Bing 设计来源链接功能的道理:通过引入外部知识链接,让判断变容易。比如上面这个例子,换成问 New Bing,记住选“精确”对话:
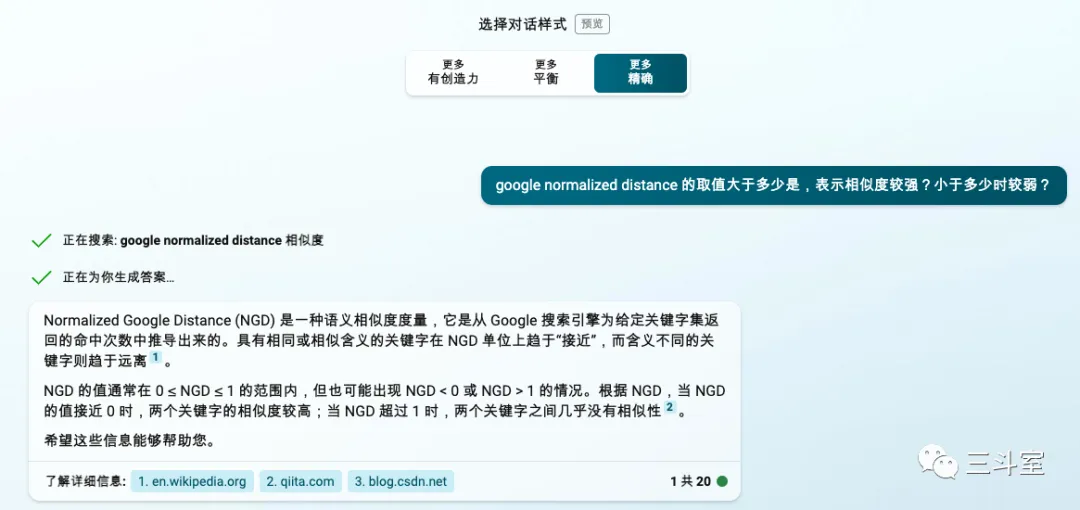
虽然看似依然强调取值一般在 0-1 之间,下面直接给出了 Wikipedia 地址。我们就很容易判断对错了。
好了。“能不能”的问题就聊到这,下期,我们继续“能、好、怎”,敬请期待。



