话接上回,今天给大家介绍 ChatGPT “能好怎”中的“好”字诀——Schillace’s Law。
Schillace 是微软副 CTO,他根据微软内部使用 GPT4 辅助编程的实践经验,总结了 9 条原则。这几条原则在英文中颇有韵律感和哲学意味,因此我同时保留其英文原文和中文翻译,方便大家理解:
- Don’t write code if the model can do it; the model will get better, but the code won’t.(不要编写可以由模型完成的代码;模型会变得更好,但是代码不会)
- Code is for syntax and process; models are for semantics and intent.(代码用于语法和流程;模型用于语义和意图)
- Text is the universal wire protocol.(文本是通用的线协议)
- Trade leverage for precision; use interaction to mitigate.(为了精确性而牺牲杠杆;利用交互来缓解)
- The system will be as brittle as its most brittle part.(系统的脆弱性取决于其中最脆弱的部分)
- Uncertainty is an exception throw.(不确定性是一种异常情况)
- Hard for you is hard for the model.(对于你来说困难的事情,对于模型来说也是困难的)
- Ask Smart to Get Smart.(好好提问,获取智慧)
- Beware “pareidolia of consciousness”; the model can be used against itself.(谨防“意识的错觉”;模型可以被用来反过来使用)
我高亮出来的第 7 和第 8 条,针对编程以外的所有场景,都有指导意义——向 ChatGPT 提问时,一定要牢记它是个加人类反馈的文本预测模型,你在界面上的一举一动,都会影响 ChatGPT 的最终输出。所以一定要“好好用”,别瞎玩!
一次好的 ChatGPT 交谈,一般都是这样开始的:
<定义角色>。<希望它做什么>。[对输出内容的拆解要求]
定义角色的目的,其实是通过一句垫场话,唤醒 ChatGPT 的记忆,让它自动补充相关的领域信息,排除一些无关干扰。其实你换个说法,比如“你知道 XXX 么?”也一样。如果这一句话不够,可能就需要在后续拆解要求过程中通过额外提供样本等 ICL、CoT 方案来加强了。这属于“能好怎”的“怎”字诀。今天先不展开。
除了补充领域信息,拆解要求一般还有几个常见的点:
限制长度:说清楚要输出多少字,什么格式——这一般用于 prompt 效果挺好,打算留下来以后经常用。就可以在调好了以后,加上“不要解释”、“只要提供代码就好”等等限制语。
明确主题:清楚表达意图,并聚焦在一个主题内对话——再次强调,好好提问,别瞎聊天,因为一次会话内,上下文、编辑、重生成、对结果都有影响。你瞎聊,ChatGPT 会比你更瞎!
为了加强大家的印象,我这里给大家演示一个极端案例:
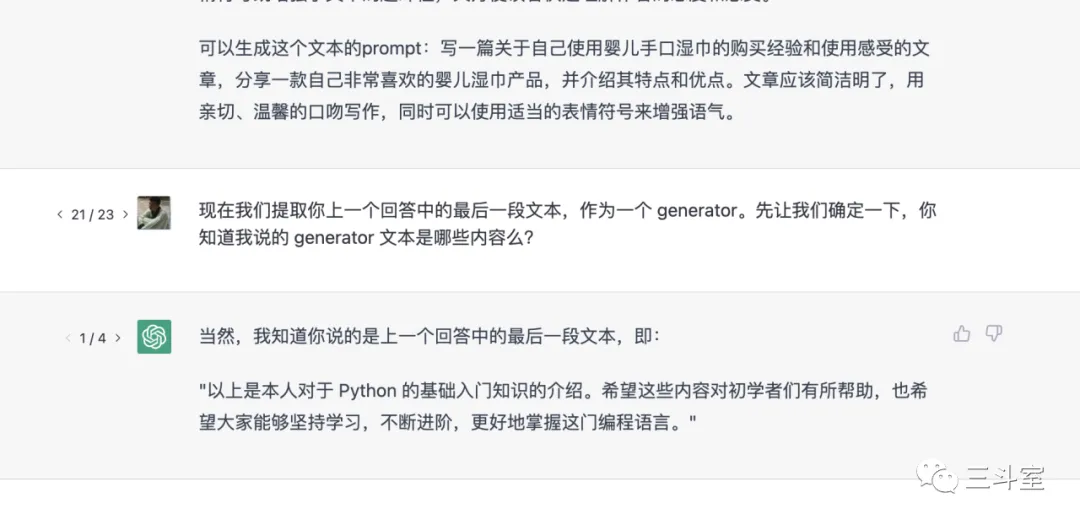
案例场景非常简单,就是让 ChatGPT 重复上一段话。是不是感觉绝对没问题?但是当我们重复编辑 20 次以后,ChatGPT 对着一段湿巾的文案开始推荐 python 了!
这就是因为正确的文字真的都用光了,用户一直点编辑, ChatGPT 不断降低过去回答里的文字的权重,降无可降,只能开始语无伦次的说胡话。
看过这个极端案例以后,大家都知道好好提问的重要性了吧?下一期,我们介绍“能好怎”的“怎么问”,敬请期待。



