日志易 Text to SPL,从广义概念上属于 Text to SQL 的一种变体。经过接近一年的尝试探索后,我们的第一个正式版即将推出。正好我在 AiDD 上海站听了好几家 Text to SQL 的分享,发现他们的各种路线我们都尝试过了。这下也更有信心,可以给大家分享一下我们的探索过程。
第一版:微调训练
一年前,ChatGPT 和 LLaMA 刚刚面世,国内也只有智谱 ChatGLM-6B 一家主流开源大模型。全世界的关注点基本都在微调训练上,著名的Databricks 公司还发动全员人肉编写了 15k 条问答数据。我们也不例外,第一反应同样是基于 ChatGLM-6B 来微调一个 SPL 生成模型。
微调的关键是问答数据集。通用格式的微调训练问答数据集大概是这样的:

我们采用了各种手段积累微调数据:
- 从日志易使用手册中摘录用例
- 从日志易内置规则中提取图表标题和查询语句,使用角色扮演的 prompt 生成更顺畅的提问(但重复生成反而有副作用)
- 从 github 上爬常见的日志关键字、公开的elastic/splunk/kusto安全查询规则库并进行改写转换
- 基于日志易 SPL 语法说明,使用 self_instruct 方法合成数据(实际不太好约束)
- 手工编写一些同环比、比率运算、跨行处理问答,均衡不同场景数据偏重
- 手工编写一些思维链问答,提升复杂 SPL 场景的逻辑推理能力
- 手工编写一些多轮对话,丰富一些二次过滤关键字或调整统计等场景
最终得到了数万条微调数据,但 topN 类统计占比依然过高,多次测试发现,删掉部分数据,各种场景均衡一些更好。下图是SPL 问答数据集和通用数据集混合微调后的测试效果:
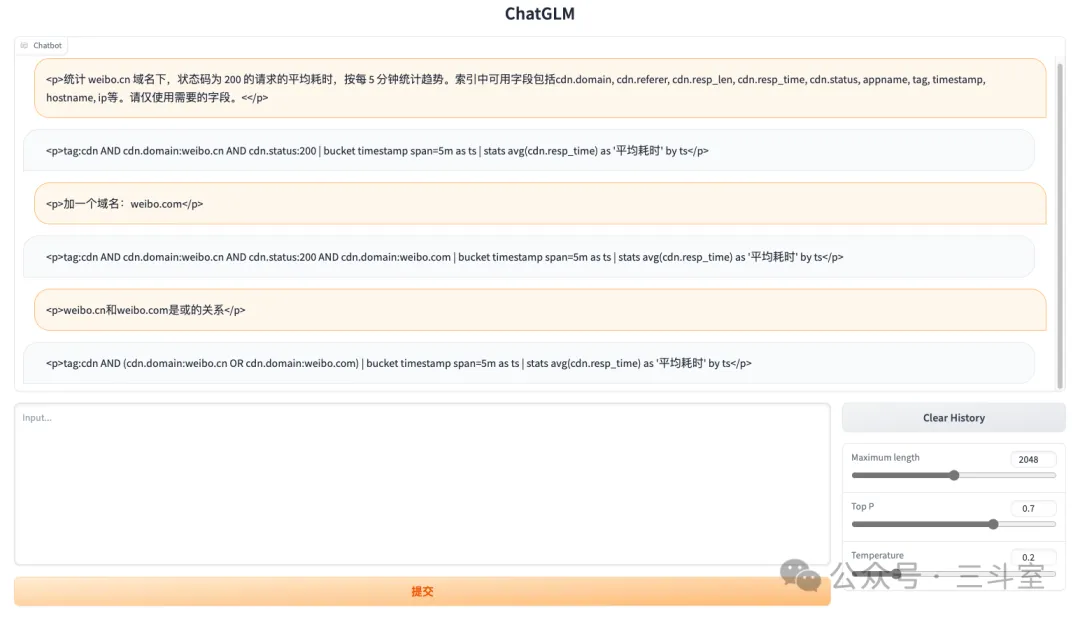
看起来似乎还不错?当内测范围放大到全司上百位一线同事后,悲剧发生了,大量的回答被评为“乱七八糟”。根据问题难易差异,成功率大概在 10%~50% 之间。看完上万条服务器问答记录后,我们发现,核心问题在于:真实提问相当发散和简略,大量问题即使人工阅读也很难直接回答。于是导致大模型的回答不能收敛在训练集的语境里,甚至连正确语法都无法保证。此外,_部分提问和期望生成的 SPL 语句在词汇语义上毫无关联,也干扰了大模型。
注:我们其实还尝试了用实际查询结果对比的方式做自动化的客观评测,但因为 SPL 过于灵活,timechart 和 bucket 的差异、groupby 字段次序、rename 和 as 等参数项差异,导致人工评测正确的语句,客观结果评测为错误。所以最终没有采用。
第二版:RAG 和 few-shot learning
第一版内测结束,痛定思痛,我们决定降低目标,不指望大模型可以自主推理实现复杂(复杂的意思其实是“用户啥都没说清”)场景。转而考虑利用内测收集到的“合理”提问,构建 QA 示例仓库,通过向量数据库提供相似度检索。
进一步的,通过日志易自身的索引管理功能,获取字段列表,可选值等元数据信息,也存入向量数据库。收到提问后,我们通过 RAG 召回相关的元数据信息,和相关的 QA 示例,一起加入 prompt。
此外,还尝试了将 SPL 语法说明文档也加入向量数据库,通过 RAG 提升 SPL 语法生成的精准度。不过实践证明,已经有 QA 示例,额外加语法说明提升不大。
注:AiDD 大会上,阿里云 dataworks 团队的 Text to SQL 方案就是这个思路。

本地开发调试满意后,我们重整旗鼓,再度邀请少量同事进行内测。结果“一塌糊涂”!分析发现,在 IT 运维领域,有些概念存在严重的混用(比如:业务/产品/应用/服务/系统,各家理解不一样),但对向量相似度来说,差异就非常大了。所以元数据的 RAG 召回结果反而起了负面影响。
第三版:意图和实体识别 workflow
第二版的 RAG 失败后,我们重新思考 Text to SPL 的运用场景。日志作为非结构化数据,字段值过滤本来就不能覆盖到关键字过滤的场景,所以干脆_放弃掉精准生成字段值的期望,有特殊关键字需求通过添加 QA 示例来实现_。剩余的 RAG 内容,直接使用大模型的 long context window 替代,反而能用上大模型强大的语义理解能力。
此外,为了更好地处理用户提问意图模糊、无效词汇语义干扰的情况,我们决定采用 workflow 方案,分步调用 LLM,先实现意图识别,提取实体“数据源”、“时间”、“过滤条件”、“统计场景”;然后由该“数据源”的元数据和过滤条件生成 SPL 的查询部分,由元数据和统计场景生成 SPL 的统计部分。当识别提取有困难时,可以主动要求用户优化完善。下图是理想中的 workflow 思路(ChatGPT 生成的 mermaid 效果):
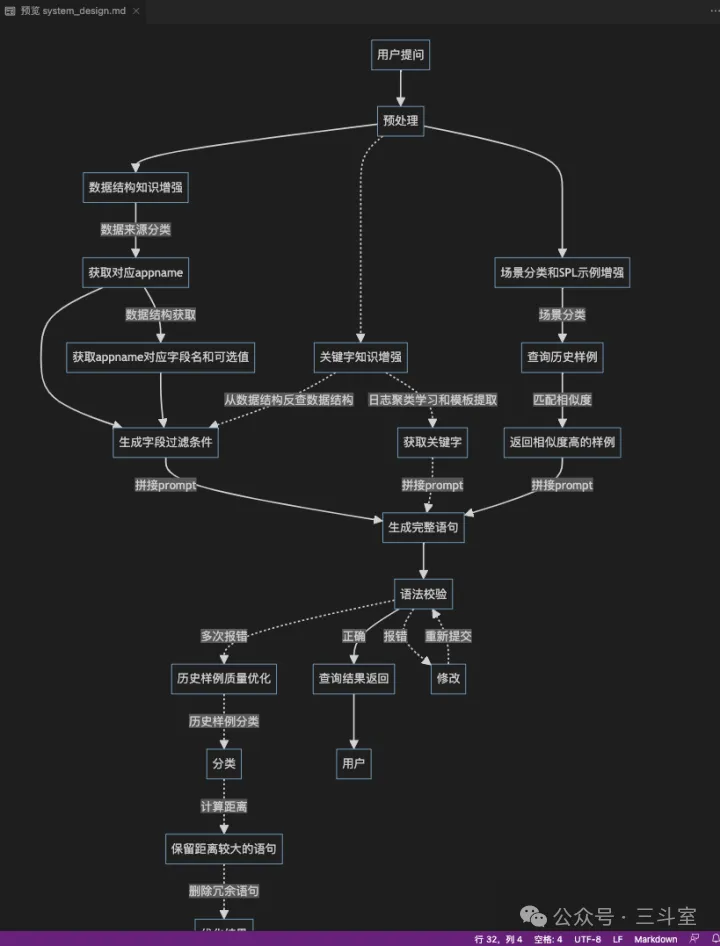
注:AiDD 大会上,汽车之家的 Text to SQL 方案就是这个思路:LLM 提取“指标、计算、维度、筛选”4 要素,然后以结构化 JSON 去召回 SQL 示例。我注意到 PPT 中展示的用户提问极短(也是我们面临的问题),分享嘉宾直接表示没办法,先上线再慢慢积累标注。

第三版开发完成后,效果有了较大的提升。过去很容易出现的各种语义上的“离谱”错误,都得到了很好的约束。问题又重新回到了 SPL 语法本身。依赖 QA 示例的 RAG 效果,依然有一定的错误,不能精准控制。这个版本都没进内测阶段,我们就直接开始了下一版迭代。
第四版:function call
经过第三版的尝试,问题已经集中在了 SPL 语法的精确度控制上。这时候我们想到:既然我们已经主要依赖 QA 示例,那么分析抽象一下,用户实际常用的查询分析场景,可能集中在几个或者十几个类别。干脆彻底放弃让 LLM 仿写语句,直接把每个类别的语句做成模板化生成,利用大模型的 function call 能力,就能实现精准控制了。
最终效果如下:
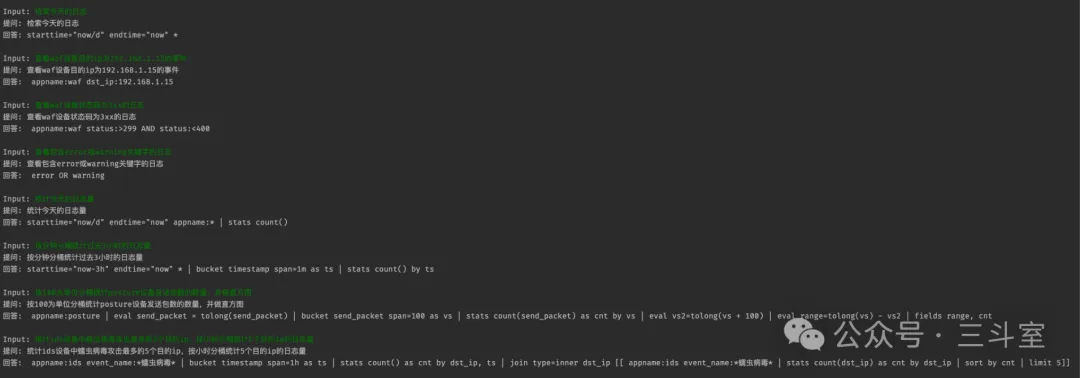
基座模型效果总结
方案介绍到这里就差不多了。最终方案和原始方案可以说毫无干系,非常考验基座模型的能力。因为方案需要多次调用 LLM,假设一次调用 LLM 的准确率是 95% 和 80%,看似差异不大,4 次调用累积误差的结果就变成 80% 和 40%!
经过测试,完整的基座大模型切换对比如下表:
| 基座模型 | GPT4-turbo | GPT3.5-turbo | deepseek2 | doubao-pro | doubao-lite | qwen2-72B | qwen1.5-72B | qwen1.5-14B | ernie-3.5 | ernie-4 | ernie-speed |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 全流程正确率 | 97% | >80% | <80% | < 80% | - | 80% | 68% | 28% | < 50% | - | - |
| 解读 | 36 道题只错 1 道,天花板 | 实验基准 | 过滤条件生成较好,functioncall 内容经常被错误填充到 content | 同左 | functioncall 经常瞎编 | 开源最佳 | 参数量影响巨大 | functioncall 经常瞎编 | 过滤条件生成较好,但不支持 functioncall | 完全不可用 |
可以看到,百亿级的开源大模型,无法支撑当前方案的运行。所以使用日志易 Text to SPL 功能,需要有较好的 GPU 算力支撑,能运行通义千问 72B 大模型才行。



