当我们沉迷AI搜索,背后有一场“看不见的战争”
最近,上海寸屋拉面店在门口打出的广告爆红网络,广告内容很神奇,是该店被DeepSeek推荐为“上海最好吃的日本拉面TOP1”:
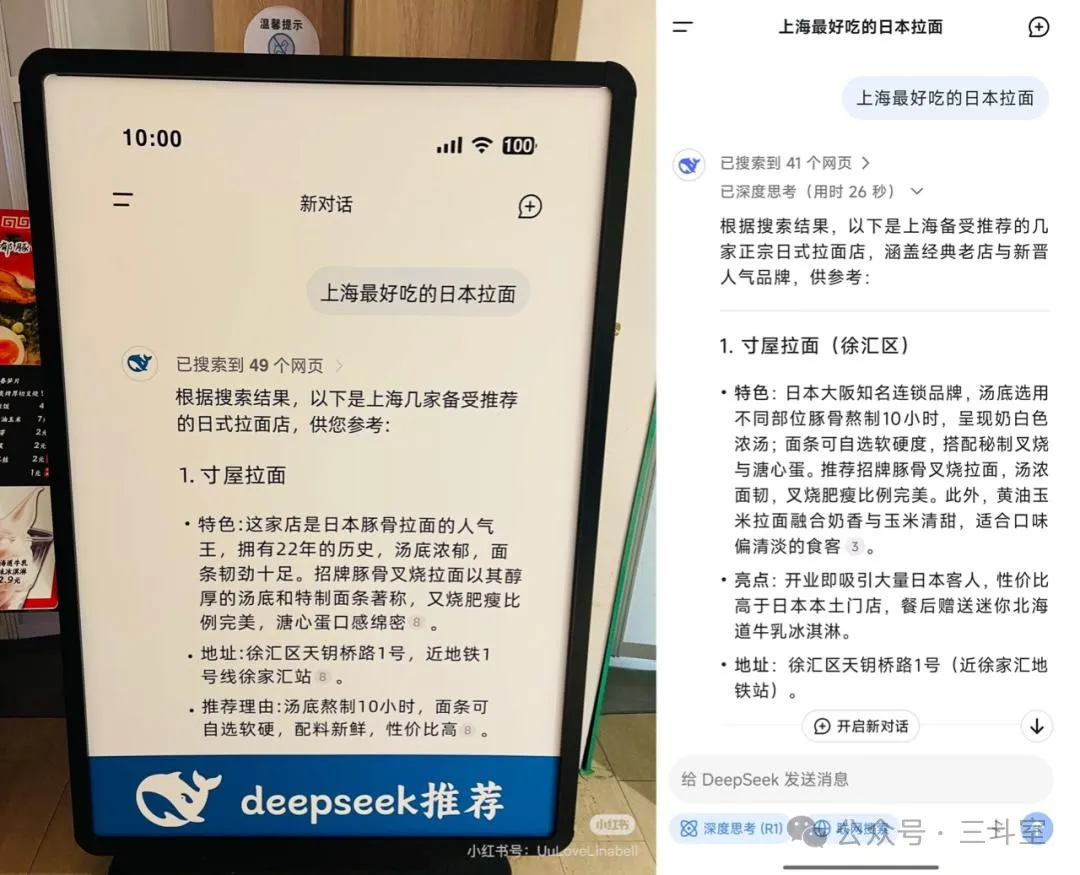
这个神奇的营销思路引起诸多效仿,但更多的老板可能在问市场部门一个完全相反的问题:“为什么 deepseek 的答案里没有我们?”
这就是AI搜索时代的新难题:传统SEO(搜索引擎优化)在失效,新兴GEO(生成引擎优化)不知从何做起。大模型在“检索”之后,附加了“生成”步骤,自然语言的描述内容,代替了传统的网页排名。现在,大家要争夺的流量入口,已经不是“百度排名”,而是“deepseek的脑回路”。
今天,就给大家分享三个相关的研究。希望能更好的帮助大家理解大模型们的脑回路~
GEO:给AI“洗脑”的七种武器
论文地址:https://arxiv.org/pdf/2311.09735.pdf
根据印度理工学院与普林斯顿大学的《GEO: Generative Engine Optimization》研究,AI生成结果对内容的偏好呈现三大特征:权威崇拜、数据饥渴、逻辑洁癖。论文根据 AI 生成结果对网页原文的重合比例、原文引用的位置衰减速度,进行 GEO 效果评估。通过对比实验,针对搜索引擎排名较低的小网站,论文提炼出七个有效优化策略:
- 数据武装:将定性描述转化为定量指标(如“销量领先”改为“市占率37.2%”),可大模型回答可见度提升65.5%;
- 权威背书:添加权威机构引用(如“据Gartner报告显示…”),可见度提升132.4%;
- 专家话术:植入专业术语、名人语录(如“诺贝尔奖得主XX称…”),可见度提升89.1%;
- 逻辑提纯:删除冗余修辞,用“因为-所以”强化因果链;
- 源头截流:自建行业白皮书、研究报告,抢占AI知识源头;
- 场景适配:法律领域重数据,文旅领域讲故事,医疗领域引论文;
- 长尾渗透:用口语化问答覆盖“厦门哪里吃沙茶面最地道”等自然语言搜索。
看完以后你有什么感觉?没错,人类在相互交流时,也是通过这几招来增强自己的说服力的!文采飞扬的 deepseek 在骗你的时候,也是疯狂的用数字、案例故事、量子名词来伪装自己的!现在,轮到人类去骗 deepseek 了。
CRAW4LLM:大模型的“挑食指南”
论文地址:https://arxiv.org/pdf/2502.13347v1
如果说上面说的 GEO 是影响 AI 的“输出端”,那么卡内基梅隆大学提出的这个CRAW4LLM 则从“输入端”梳理了 AI 搜索的数据筛选逻辑。
事实上,我们在体验不同的 AI 搜索时,可以很显著的感觉到数据筛选差异的影响。比如 kimi 在联网搜索后,会有一步明确的“正在挑选优质权威信息源”。又比如腾讯元宝 AI,产品最大卖点就是可以搜微信公众号文章,但目前它最多只给大模型输入 5 个网页,一不留神,就被低质结果影响了最终答案。
我们不知道这些 AI 搜索产品在联网搜索过程后,会过滤掉多少低质结果。但可以参考一些开源实现的经验,比如浦语·书生大模型的 MindSearch(https://arxiv.org/pdf/2407.20183)说的是 300 个网页。而如果参考 RAG 的经验,AWS(https://aws.amazon.com/what-is/retrieval-augmented-generation/)说的是粗搜 100 个文档,然后重排过滤成 5-10 个。
总之,传统搜索工具返回的 90%+ 的抓取数据,会因为质量低下被半途丢弃,送不到 LLM 面前。而 CRAW4LLM 告诉大家,我们可以通过预训练的文本分类模型,来提前判断网页对 LLM 的价值,优先抓取“高营养”内容。实验显示,该方法仅需抓取 21% 的网页即可达到传统爬虫效果。
论文使用的 DCLM fasttext 分类模型(https://github.com/mlfoundations/dclm/tree/main/baselines#fasttext-filtering),是 DataComp 在大模型预训练流程中,为了数据清洗方便,自己微调训练的。可以给每篇文档的质量评分,过滤阈值为0.018112,并分类为高质量的Wikipedia 类百科,或 Common Crawl 类网页存档。
所以,在我们的网页内容发布之前,也可以尝试用 DCLM fasttext 快速评判一下,要是评分低于阈值,就赶紧回炉重造吧,省得后面再被 AI 搜索“退货”了。
LLM-as-SERP:大模型想起“小时候的记忆”
项目介绍:https://jina.ai/news/llm-as-serp-search-engine-result-pages-from-large-language-models/
这个项目出自著名的 AI 搜索厂商 jina.ai。他们在尝试复刻 openai 的 deep research 功能时,突发奇想,明明大模型预训练的时候,已经跑了那么多高质量的网页(按估算,相当于全网的 1%-5%,既必应搜索的 30%-50% 索引存量),为什么我们还要费劲再做一遍联网搜索、质量过滤?为什么不能激发大模型“小时候的记忆”,再混合一些最新网页?
为了反其道而行之,jina.ai 干脆把这部分的产品 UI 做成了“伪·搜索引擎”:
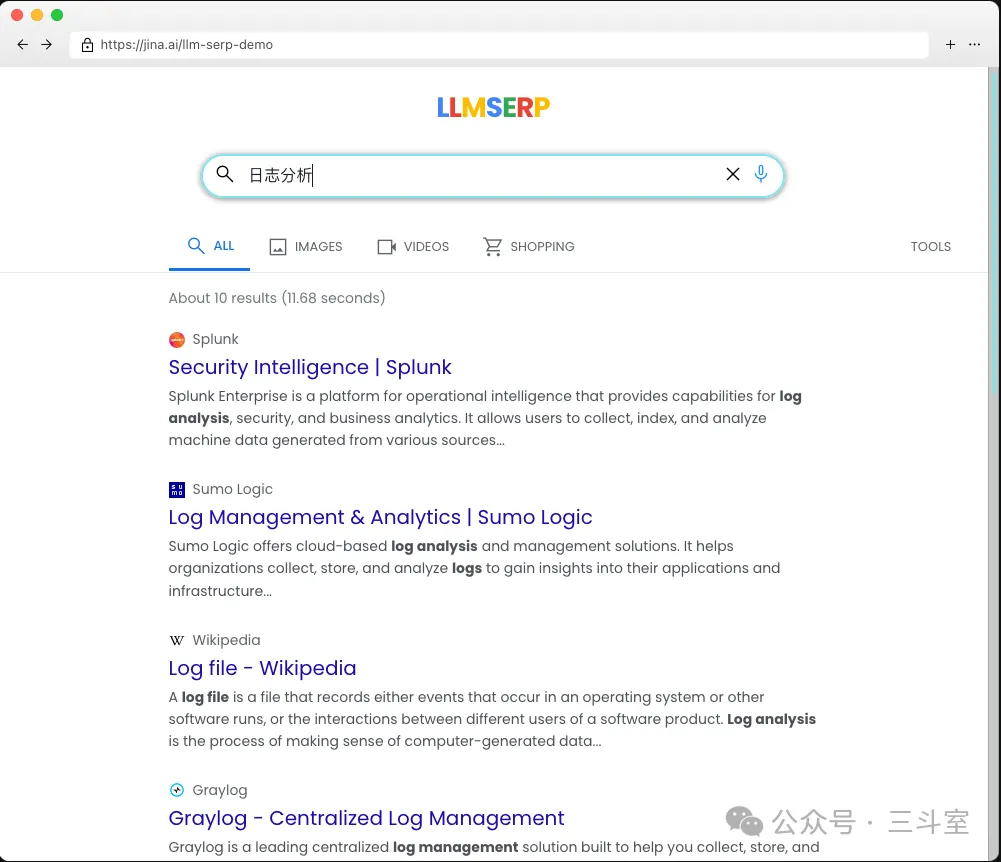
LLM 伪造的结果里,当然有真内容,也有假 URL。比如我下载了 node-serp 源码,让 AI 帮我把模型从 gemini 切换成 qwen 后,搜索我司“日志易”关键字,得到的结果:
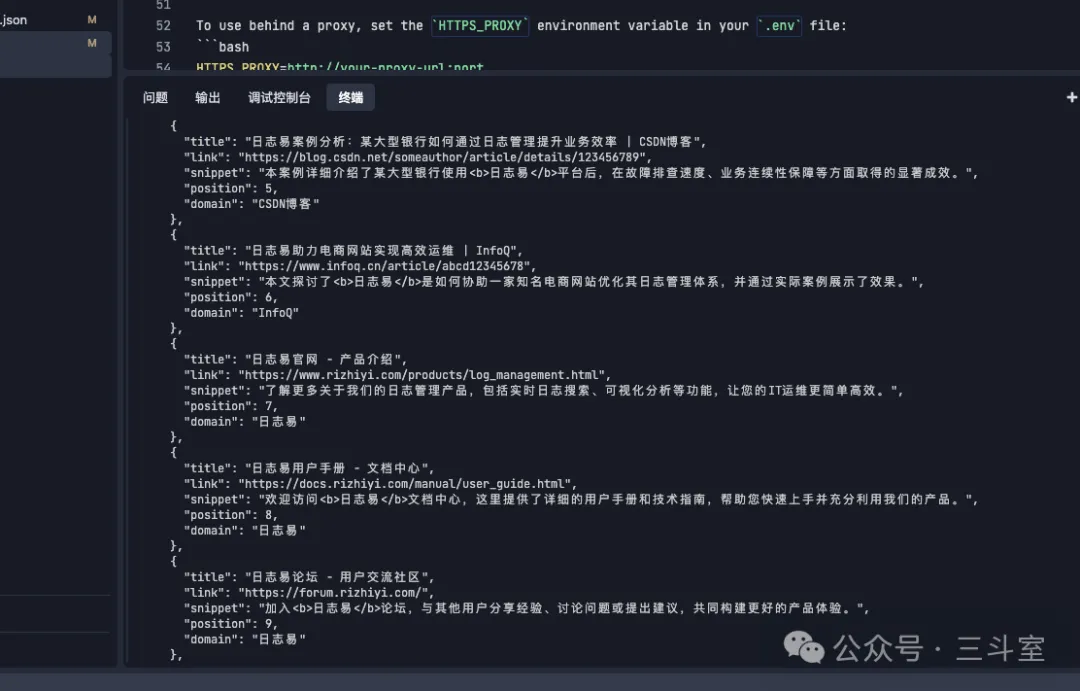
结果一个真实的 url 都没有。但我们可以很明显地感受到:在 IT 领域,预训练语料真的有很多 CSDN 和 InfoQ。
行动起来
从这三个研究,我们已经可以构建一个针对 AI 搜索的端到端的优化方案。让我们的产品,成为大模型小时候的记忆、长大后的白月光,脱口而出的名字。
不说了,我现在就要行动起来,去给公司注册 CSDN 和 InfoQ 的企业号!



