因为 deepseek 的母公司幻方做量化基金的缘故,相当多的一大批大模型新用户们,想当然的认为大模型可以用来炒股!一些半懂不懂的 IT 从业人员,也觉得大模型完全可以用来处理时序指标数据。一些运维的公众号软文里,已经开始写怎么用 deepseek 做监控——那么,大_语言_模型,直接读监控指标,真的可行么?
这个问题其实也是目前学术界的热门方向。今天为大家带来几篇相关的时序指标问答大模型研究。
ChatTS
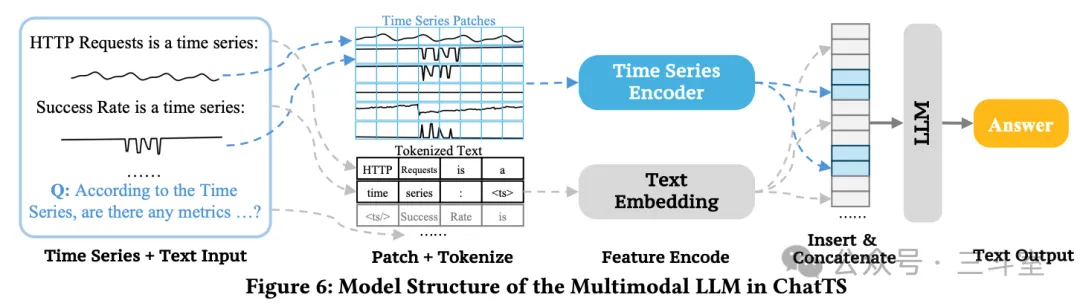
ChatTS 出自清华大学裴丹教授的团队。关注 AIOps 智能运维领域的同仁应该都耳熟能详了。论文中详细介绍了使用大模型技术来解读监控指标的 4 种可行路线:直接发 text,调用 agent,视觉多模态识图,专用指标多模态。本文是最后一种,在 qwen-14B 的基础上训练。
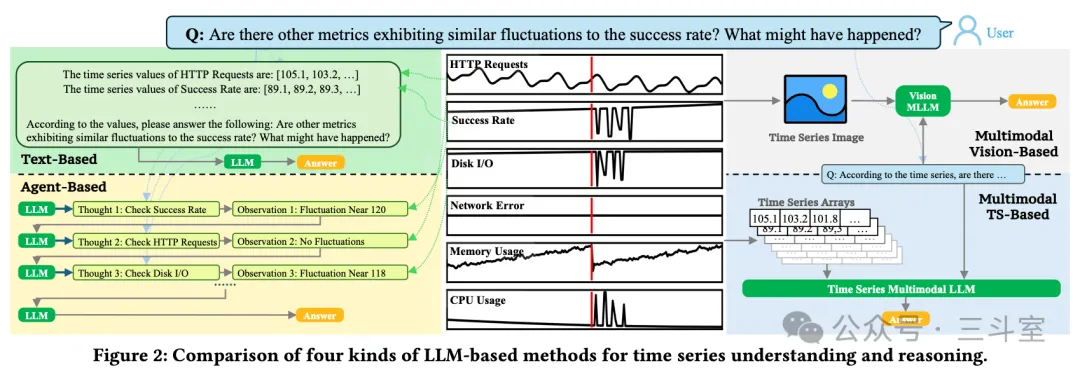
然后为了解决指标数据没有太多开源数据集的问题,ChatTS从实际场景出发,总结设计了一套非常详细的合成数据的方案,基于指标的特定特征(4 types of Trend, 7 types of Seasonality, 3 types of Noise, and 19 types of local fluctuations)来合成指标数据。这里需要一些原始真实数据来启动,论文从实际环境抽取了 567 个实际的 metric name,然后用 GPT 来选择哪些特征合适这个 name。这些数据,在后续流程里用来做增量预训练。
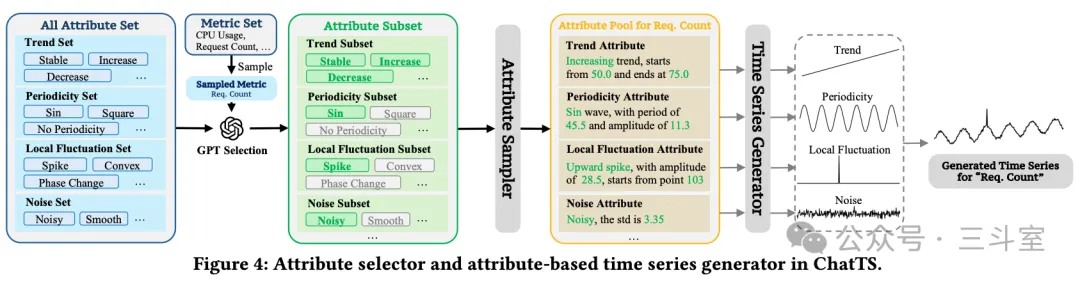
接下来,就是怎么让大模型能“读”这些数据,这里参考了很火的 Evol-Instruct 方案,提出了 TSEvol,从上面合成的指标数据,再合成对应的问答数据。除了通用的更广和更深,还加了 reasoning 和 situation 两类。这些数据,在后续流程里用来做微调训练。
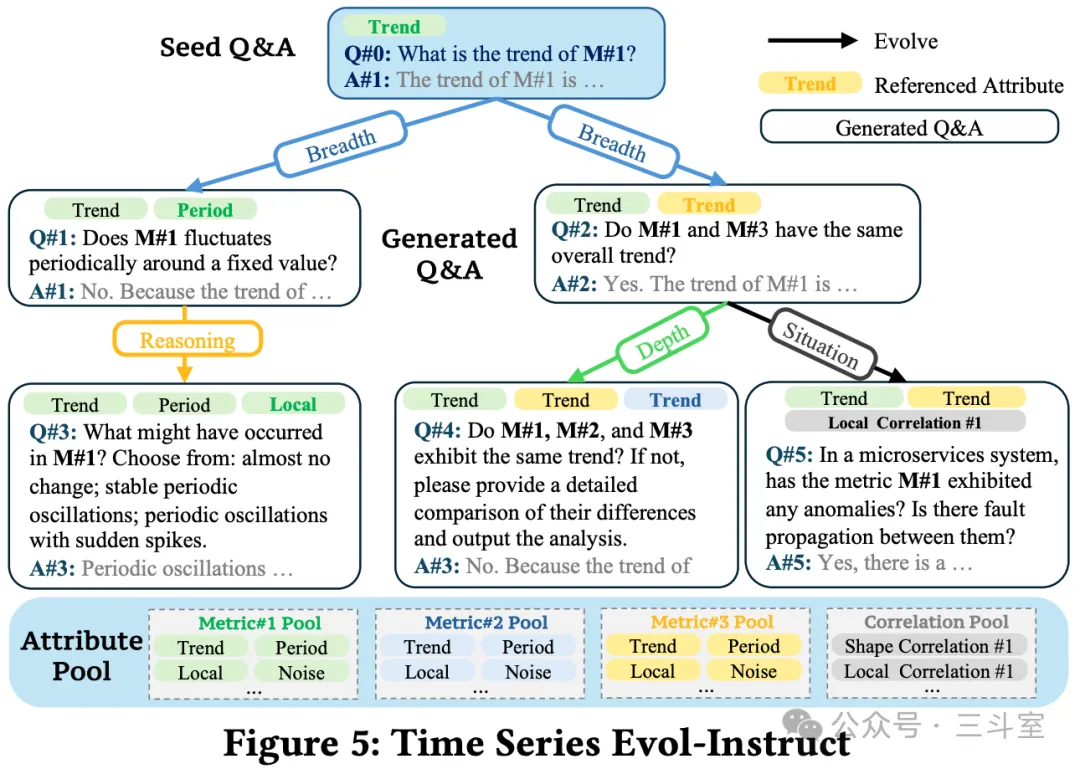
我们都知道,大模型的词表是固定的,尤其是 qwen 等新一代大模型,对数字只认0-9 十个数字,所以处理指标的 token 消耗量巨大,也没有太大的逻辑可言。ChatTS 这里就额外在 qwen 模型的主结构之前,叠加了一个 5 层的 MLP,对监控指标做 fix-size patch 切分和 encoding编码。
整个论文的逻辑思路可以说非常清晰,接下来就看最后效果了。
评测部分,把评测问题分成了对齐(趋势、季节、噪声、迁移、关联等)和推理两大类。大模型的一大特色就是跨问题领域的泛化能力,所以多类问题的综合得分情况是必看的。评测数据集 A 是从各种开源数据集提取、B 是LLM合成、MCQ2 是从《Language Models Still Struggle to Zero-shot Reason about Time Series》论文开源的数据集中选了 100 条。
MCQ2 原文数据集是用 GPT 生成对应场景的 python 再合成指标及问题,场景远不限于 IT 运维方向,且高达 23 万个 QA 对。 – 《Language Models Still Struggle to Zero-shot Reason about Time Series》
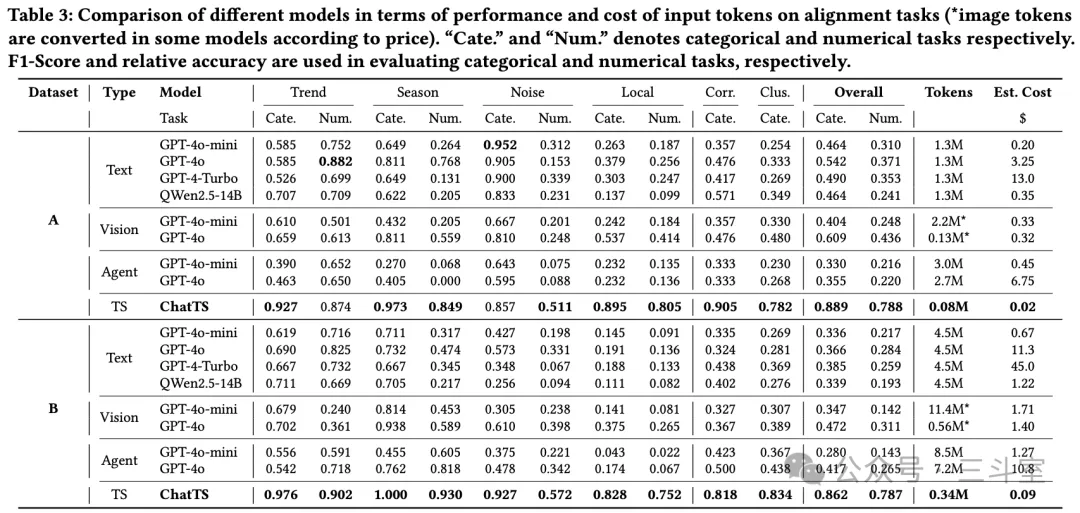
对齐类问题,我们可以看到一个比较出乎意料的结论:Agent 方案效果最差!比直接发 text 都差!
为了探究为啥 agent 方案那么差,论文构造一套完美工具,删掉了所有返回不对的数据,然后计算 tool 准确度的影响。对比如上图。总的来说,LLM 基础能力影响太大了,稍微一点抖动,就会让 agent 不成立。
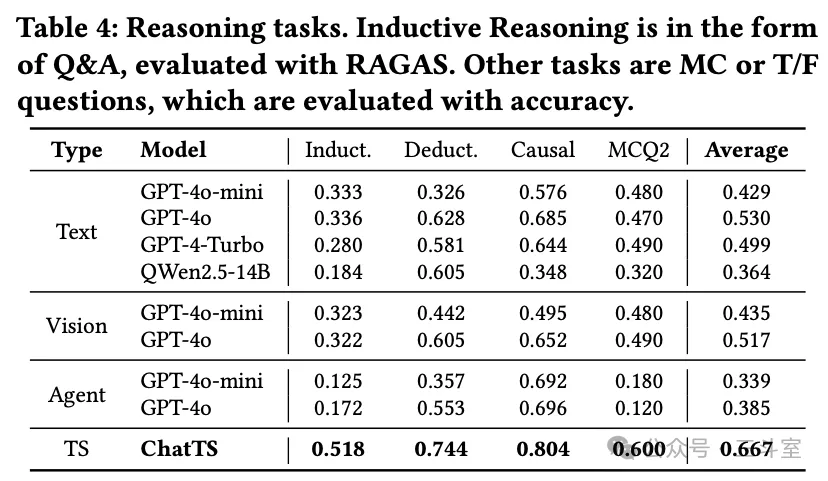
推理类任务,哪怕 ChatTS 效果也比较一般。
当然和 MCQ2 数据集原始结论对比的话,已经提升不少了,当时的结论是推理问题基本约等于随机四选一:
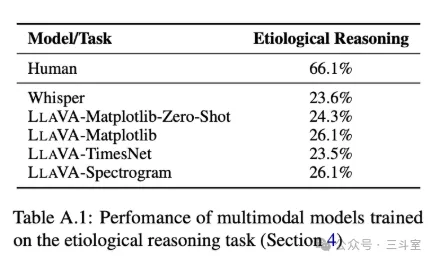
最后论文也做了消融实验,当然是每步设计都有贡献。不过可以看到,还是基于特征构建的合成数据,贡献最大 —— 也就是:特征比数值本身更重要。
换句话说:如果传统 ML 算法提取特征,然后特征描述交给大模型,是不是也足够了呢?python 社区的 tsfresh 库,antd 社区的 AVA insight 开源项目,都可以给我们更多参考。
ChatTime
ChatTime 出自北邮和中国联通的合作。整体思路其实和 ChatTS 非常类似,不过有几个差异:
- 基于 LLaMA2-7B 做训练,而不是 qwen-14B。
- 直接使用开源数据集,没有合成仿真数据。为了防止过拟合,还做了聚类,只挑选 1M 数据点做增量预训练。
- 直接扩词表,没有额外编码。具体做法是:为了保留预测序列可能超出历史序列范围的空间,将历史序列缩放到 -0.5 到 0.5 的范围内。然后,将 -1 到 1 的区间均匀划分为 10K 个分箱,每个缩放后的实值映射到对应的分箱,使用分箱的中心值作为量化后的离散值。这样就直接把离散值加入词表。
- 用滚动窗口切片,而不是固定窗口。
二者因为非常接近,包括评测上也都有选择 GPT4 作为基线。某种意义上我们可以做横向对比——注意因为数据集不一样,此处仅作不负责任的猜测。
ChatTS 是固定 512 的窗口,所以我们也就对比 ChatTime 的 512 效果就行了。 ChatTime 都是选择题问答,所以选 ChatTS 里的 Category 列。
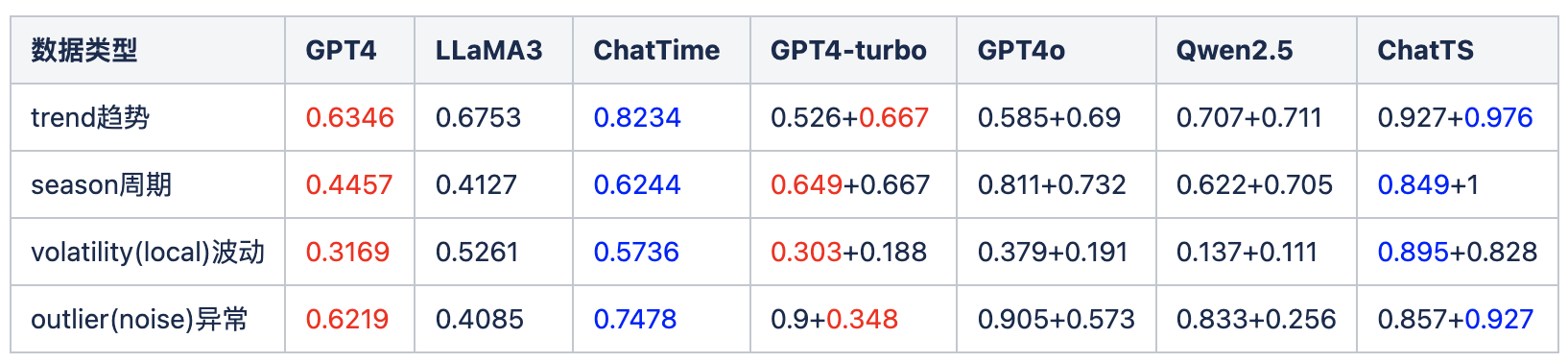
ChatTS 里有两个不同数据集,而且在波动和异常两个场景下,评分差距很大。所以都列出来。可以看到 A 数据集在波动上,B 数据集在异常上,分别接近 ChatTime 的 GPT4 评分。
所以我们以 GPT4 作为锚点,可以大概对比两篇论文的水平,显然还是 ChatTS 领先较多。通过简单的词表对齐来实现指标大模型,提升确实有,但不算特别大。
TempoGPT
TempoGPT 出自中南大学电气学院,方法和 ChatTS 更加类似。差异点在:
- 电气比计算机穷,只有4 张 V100,而 ChatTS 是 8 张 A800。 所以 TempoGPT 最后只训练到LLaMA3.2-3B。
- 增量预训练数据的来源非常有特色,作者做了一个电路仿真系统,生成电流电压指标。问答主题也是电压趋势、电源故障之类的。
- 换了一种 discrete embedding 方案。

因为太穷,TempoGPT 论文的综述部分提到的传统 embedding 方案都没直接运行对比,而是自己在GPT2 这种 M 级别的小模型上复现了一遍:
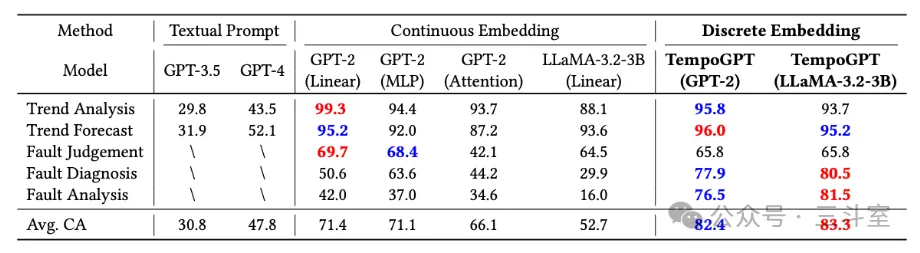
当然,从 GPT2 到 LLaMA-3B,还是显著证明参数量越大,效果越好。
Time-MQA
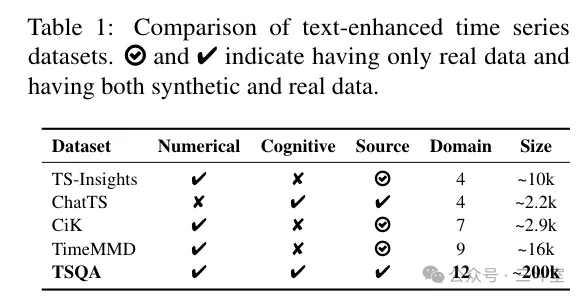
最后一个,是松鼠 AI 文青松教授团队的。他们整理了一个超大的时序数据集,而且场景领域分布也最广,最后用 GPT 合成了问答数据:
但是后续主打一个“力大飞砖”,没有什么模型结构设计,就在 mistral-7B 这个量级的模型基础上直接硬跑微调…… 最后评测结果:
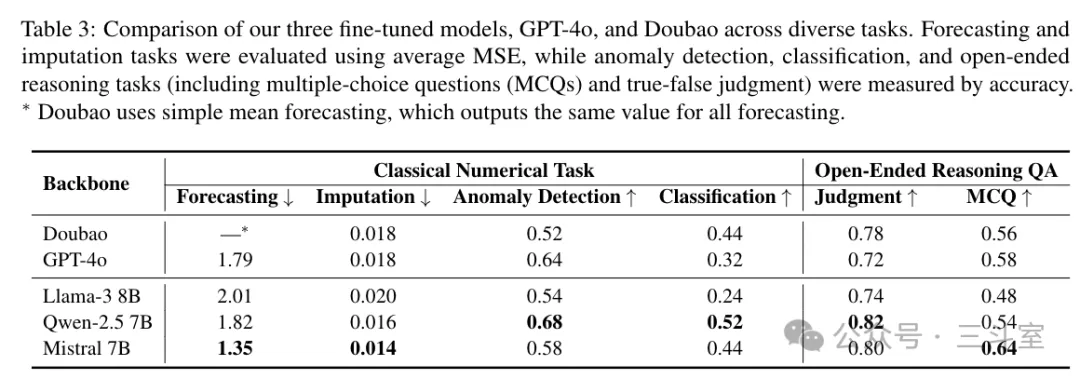
但是这个 MSE 数据和前面几个差别很大,应该受数据集分布影响,没法横向对比。唯一有趣的就是左上角,豆包在指标预测场景,输出全部是一条直线,所以无法参评。哈哈!



