昨天看到安全村 SecUN 公众号上发表了一篇署名为奇安信副总裁张卓的文章:《通过DeepSeek现象思考大模型落地的正确路径》。文章很长,内容很多,看起来非常扎实。但其中一些技术细节和数据,值得商榷。
首先,“DeepSeek不擅长的”真的不擅长么?
文中用来佐证通用大模型不懂安全的第一个示例场景“解释一下双尾蝎”。实际上只要很简单的在 prompt 中预设一下网络安全背景,就可以很自然的获得正确的答案:

文中用来佐证 RAG 方案会遗漏关键信息的第二个示例场景“DeepSeek-R1-Zero 在 DeepSeek-R1 训练过程中分别在哪些阶段起到了什么作用”。实际上很可能是因为 RAG 方案过于简单粗暴。作者只采用了最基础的向量相似度 topk,而目前 RAG 已经演化了三四代方案,有一系列复杂的混合检索、重排、父子分段、GraphRAG、modular RAG、agentic RAG 等技术。
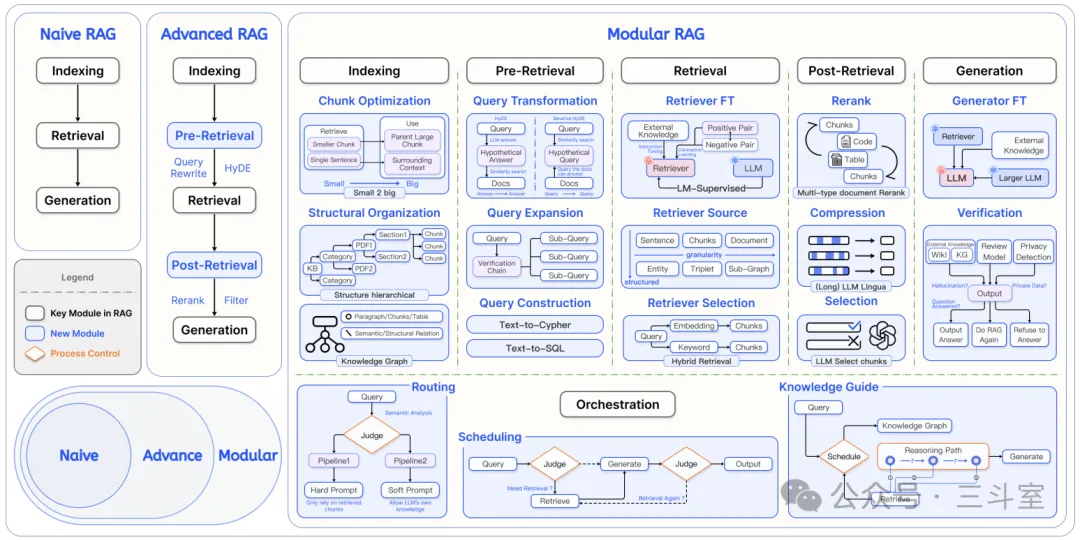
甚至我们直接用豆包浏览器插件做一下 AI 阅读,都能正确完成这个示例:
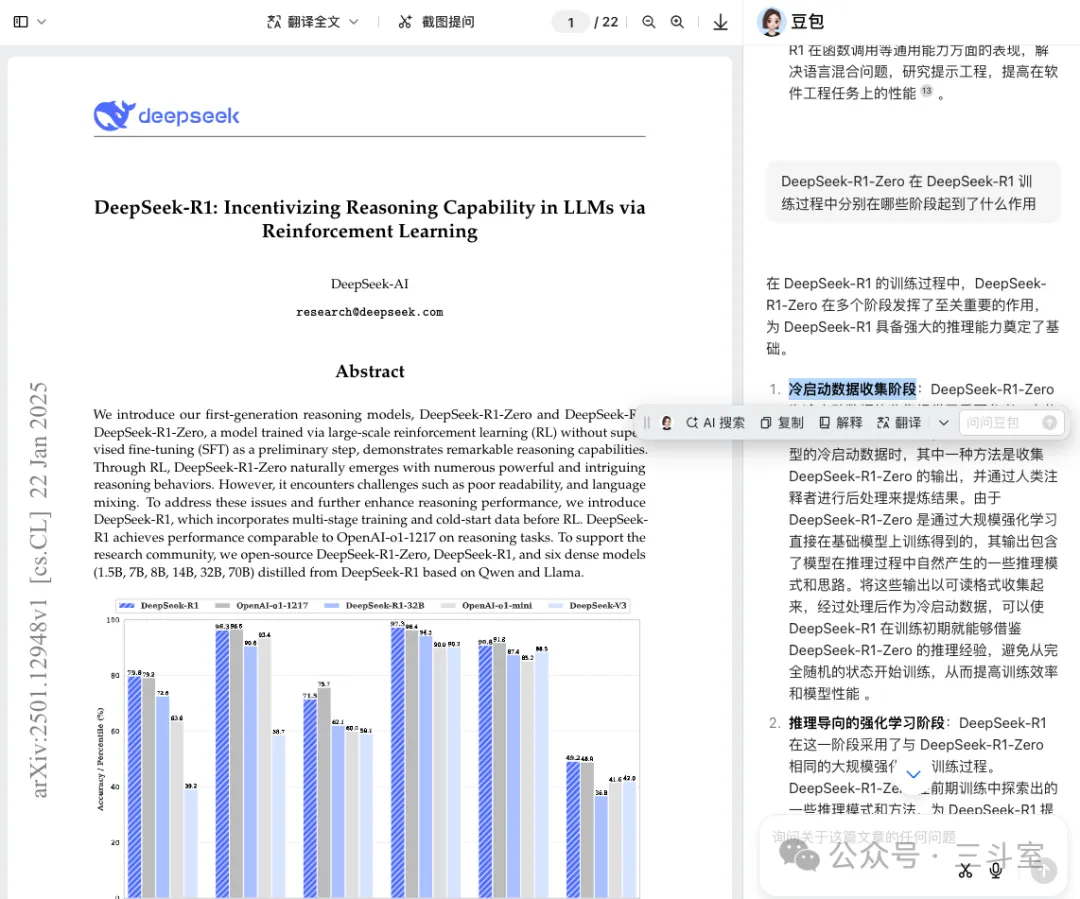
文中用来佐证智能体方案不行的几个论据,也有失偏颇:
- DeepSeek-R1 不支持 function call:调用 functioncall 能力是同级别 V3 模型的任务,就在昨天新发布的 V3-0324 版本中,functioncall 文档里的不稳定警告已经删除掉了,可以认为是稳定使用了。实际上,对于多步骤的智能体设计,本来就应该是 R1 推理模型只做 Planner,V3 非推理模型调用工具执行。
- DeepSeek-R1 的提示词需要改:不同体系的基座大模型对提示词的偏好都不一样,甚至同一个体系不同版本的基座大模型,偏好也不一样。本来就不存在一套提示词通吃不同 LLM 的情况,都要改。
比如我司内部 SPL 智能体的评测,Qwen 上表现优秀的提示词,就会让 GPT4 效果暴降:

其次,“QAX-GPT的训练细节”真的靠谱么?
文章这个小节详细描述了奇安信是如何准备模型的预训练数据集的,我摘录一下:
在预训练阶段第一步需要进行数据处理,奇安信此前专门组织了资深专家作为知识工程团队,对包括互联网数据、学术论文、专业文献、报告、书籍等通用知识进行萃取。这个过程先是收集了大量常用的公开数据集,包括FineWeb、C4、FEVER、GSM8K-Train、Race等大量开放数据集,规模数百TB。之后通过自动分类打标后作为原始语料,结合模型+脚本的筛选、合成,形成基础的通用任务训练数据集。另一方面将奇安信多年积累的数百PB、涵盖1000余类别、8000多种字段的安全私有数据进行梳理、标注,形成了数千亿token的安全专业知识数据集。再通过一定的知识配比,得到模型预训练数据集。
这段话充满了数字,看起来可信度很高。但联系一下实际经验,就会发现有不少掩饰和冲突:
- 数千亿 token 对应的纯文本文件大小,根据经验推算大概是 1TB。那么前一句提到的“数百 PB”——根据我个人经验,哪怕影印 PDF,OCR提取纯文本的大小最多就是 100 倍差距,而不是十万倍——估计绝大多数是图片、二进制文件,在大语言模型训练中并没有作用。
- 增量预训练的语料,私有数据和通用数据配比建议大概是1:5(见百度云千帆大模型平台文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/5lptj85pi),如果按照奇安信有 1TB 的专业知识来计算,他们需要的通用数据集 5TB 足矣,用不着规模数百 TB。
最关键的问题是:安全领域数据真的能有数千亿 token 么?
国内有另一家安全企业“云起无垠”,开源了他们的 SecGPT 安全大模型使用的预训练数据集(https://huggingface.co/datasets/clouditera/security-paper-datasets),对应的 parquet 文件大小为 750MB。对应的数据类型占比如图:
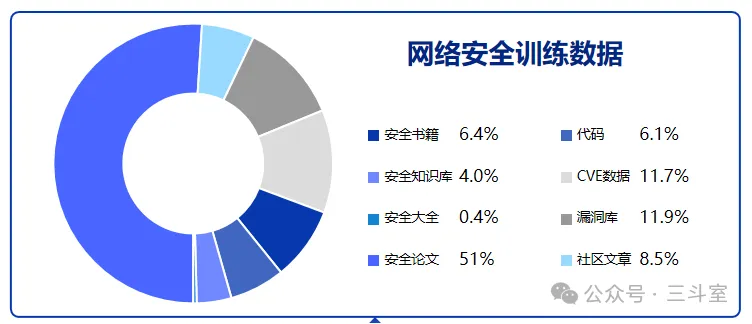
官网上还具体列出了不同数据类型的来源数量:

这里不同厂商之间可能差异变化的就是漏洞、情报、研究报告部分,奇安信作为大厂,可能会有更多数据。那大概会多多少呢?
我用腾讯元宝进行了一番联网搜索和推理,大致结论是:全网公开安全漏洞信息 27 万余条。

再来估算一下对应多少 token。
我们假设(大模型推理+业内朋友咨询)其中 90% 是一两页的简单漏洞报告,就像安全村 SecUN 文中提供的那页截图,大概 token 在500-1500。然后大概 10% 有 10 页以上深度研究报告,token 在 10000-30000。
结论是上限十亿级别:276834*(0.9*1500+0.1*30000)=1,204,227,900
最后剩下一种可能:企业内部有大量情报漏洞附带的端侧运行数据样本。样本由机器产生,确实可以无穷无尽——但可惜,这种数据并不适合直接交给大模型训练。机器产生的过于重复的日志直接投入训练,只会让大模型越练越笨,所以才需要数据分段和去重清洗。 在日志领域,有类似的大模型数据清洗研究工作,比如:
- 华为的《Adapting Large Language Models to Log Analysis with Interpretable Domain Knowledge》,先用 LogPPT 方案提取日志模式,然后重构参数部分,合成仿真数据——这一步是为了均衡原始数据集里不同模式的日志数量占比——最后从 80GB 日志中生成了 25 万个问答对,一共 571MB。
- 微软的《SecEncoder: Logs are All You Need in Security》,最开始的私有安全日志数据有 970GB 大,经过清洗后剩余 270GB,对应 token 77B。用了 64 块 A100 显卡,跑了 4 个星期——注意该论文目的是训练一个的安全日志领域 embedding 嵌入模型,没有LLM模型变笨的问题。
最后,“与DeepSeek进行全面融合”真的存在么?
文章最后表示,QAX-GPT2.0-DeepSeek版是用 deepseek 作为基础模型训练而来,然后再蒸馏出一个用于生产的高速小模型。
但是,deepseek 从 V2 版本以后,再没开源过预训练和微调代码。 DeepSeek-R1 在全世界范畴内,目前仅有一例微调案例,就是 PerplexityAI 用英伟达的 NeMo2 框架微调的那个臭名昭著的 R1-1776。
其他所有以 deepseek 名义谈训练和微调的,实际都是指 r1-distill-qwen 或 r1-distll-llama。比如阿里云 PAI 平台的“一键微调 DeepSeek-R1 蒸馏模型”。不过这些本来就已经是蒸馏小模型了,不用再蒸馏。
真相到底是什么?
基于目前的分析,以及一些背景知识,比如:
- 百度云千帆文档中,提到他们提供了 110B 通用语料,供用户混合数据。
- clouditera SecGPT 在 github issue 中回复说,论文 51% 的比例过高,实际训练中按比例缩减了数据。
- IDEA 研究院的 Ziya-LLaMA-13B 开源项目:他们为了提升 llama 的中文能力,用 110B 语料上增量预训练,在 160 块 A100 显卡上,跑了 8 天。
- openai 表示微调主要用于强制输出的风格语气,节省 token。
我合情合理的推测,奇安信 QAX-GPT2.0-DeepSeek 实际情况应该是:
- 内部有一个不高于五十亿 token 的无监督训练的数据集,从均衡占比的角度猜测,实际组成大概是:1B 安全领域基础知识+1.5B 安全漏洞库和分析报告文档+2B 安全日志程序样本。
- 通过类似 Self-QA 的方案,可能结合了一些预置模板、参数脱敏、类型均衡等逻辑,从无监督训练数据集批量合成 prompt-completion 问答数据集。
- 在 r1-distill-qwen-32B 的基础上,使用上一步得到的问答数据集,进行微调训练,让模型输出风格统一成奇安信产品经理设计的格式。
- 这个 32B 模型,通过 RAG 方案召回更新的安全知识,形成最终结果。



