在八个月前的《日志易 SPL 实现基于大模型的海量日志总结》中,我曾经展示了一种综合 TFIDF 向量化、KMeans 聚类和 DPP 多样性采样算法,实现日志总结的方案。现在新一代的大模型,普遍可以支持 128k 的上下文窗口大小,激进一点的,比如 gemini、minimax,运用线性注意力机制,甚至实现了 1M 以上的窗口。很多人就有疑问了:我是不是直接把几千行日志一口气上传给大模型,要求 AI 总结就足够了?
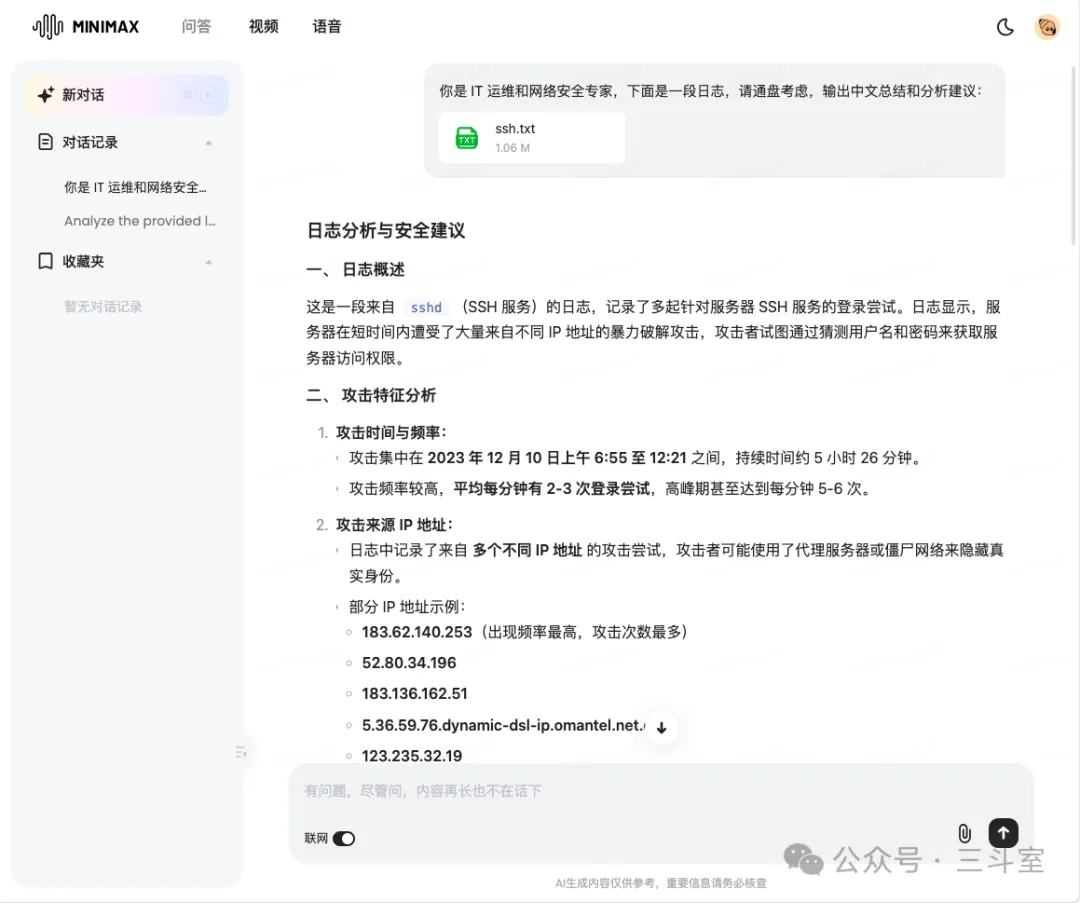
截图minimax的总结效果,看起来也挺不错的哈?
日志因为数据量太大,很难人肉眼阅读和记忆,在不同大模型和方案的总结输出里,很难快速判定总结效果孰优孰劣。日志总结本身又不是什么主流研究领域,也没有公认权威的标注数据集,可以评测 BLEU、ROUGE 之类的 NLP 指标。
Ragas SummarizationScore介绍
Ragas 开源项目是一个专门用来客观评估大模型应用表现的工具。其中针对大模型常用的场景,实现了一系列的评测打分机制:https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/。比如针对 RAG 场景的召回率、相关性、忠诚度;针对 NL2SQL 场景的查询等效性;针对 Agent 场景的主题依从度、工具准确度等等。datadog 等厂商在实现 LLM observability 的时候,就采用了 Ragas 的评测机制。
在一系列评测中,就有一个针对长文本总结场景的 SummarizationScore 指标。核心思路是认为总结内容应该尽可能的覆盖原始内容的关键词。具体步骤如下:
- 用 LLM 从“长文本”中提取重要的关键词列表。
- 用 LLM 生成10个问题,要求“长文本”对这些问题的答案全部为 “是(1)”。
- 要求 LLM 基于“总结”来回答“问题”是 1 或 0,计算总得分,即正确回答问题数与问题总数的比例,作为问答正确率。
- 计算“总结”长度和“长文本”原始长度的比例,作为精简度。
- 综合两个分值得到总分,默认权重各 0.5。
不过 Ragas 毕竟不是针对 IT 运维和日志分析场景,内置的关键词提取 prompt 比较偏向新闻领域,要求关注人物、地点、时间、金额等。我们还是需要做一些调整。
Extract keyphrases of type: Person, Organization, Location, Date/Time, Monetary Values, and Percentages. https://github.com/explodinggradients/ragas/blob/main/src/ragas/metrics/_summarization.py#L40
LoFI 介绍
LoFI 开源项目对应的是香港中文大学发表的《Demystifying and Extracting Fault-indicating Information from Logs for Failure Diagnosis》论文。论文通过对日志数据的统计分析,提出了 FID(fault-indicating descriptions,一行日志里描述具体发生了什么的内容) 和 FIP(fault-indicating parameters,一行日志里描述接下来你应该关注哪个实体的参数位) 两个概念。并且发现:
只有 1.7% 的日志包含这些核心信息;而这些日志里,FID/FIP 单词占整行全部单词的数量是 14.1%。换句话说,日志里0.24%的部分是需要被总结关注的。 https://arxiv.org/pdf/2409.13561
论文对 FID 和 FIP 的具体分类,定义如下:
- Error Message directly describes a failed action or an exception raised from a software stack.
- Missing Component means some components are unavailable such as devices, tasks and hosts.
- Abnormal Behavior indicates the degraded performance of an application e.g., HTTP timeout, slow response time.
- Wrong Status means a specific response code is incorporated to explain the wrong event, e.g., status code, error flags.
- Address includes a concrete URL of HTTP requests, IP address or paths to a folder.
- Component ID records the index for a system component e.g., job ID, task ID, service ID.
- Parameter Name shows the key and value for a parameter e.g., data name, user name.
最终实现效果
现在,我们可以采用 Ragas 的评测思路,综合 LoFI 的关键词分类定义,设计实现针对日志总结场景的评分方案了。
不过经过几次实验,发现 Error Message 这个分类,对大模型提取关键词的效果有比较大的负面影响——总会偏好提取完整的一句话——所以最终的 prompt 经由 gemini-2.5-pro 调整优化如下:
"""You are an IT operations and security expert.
Extract keyphrases from the following log text that are crucial for understanding IT operations and security events.
Identify entities of the following types:
- **Network Identifiers:** IP Address (e.g., 192.168.1.100), Hostname/Domain (e.g., server01.local), URL, Port Number (e.g., 443), Protocol (e.g., TCP).
- **System Identifiers:** Username (e.g., root, svc_app), Process ID (PID) (e.g., 12345), Service Name (e.g., sshd), Device/Host ID.
- **Resource Identifiers:** File Path (e.g., /var/log/auth.log), Job/Task/Component ID (e.g., job_123, disk_sda1).
- **Status & Codes:** Log Level (e.g.,ERROR, WARNING), Error Code/Status Code (e.g., 500, 404, 0xc0000005), Event ID (e.g., 4625).
- **Security Artifacts:** CVE ID (e.g., CVE-2023-1234), Malware Name, Alert Type/Signature (e.g., 'SQL Injection Attempt', 'Brute Force Login').
- **Event Description / Issue Type:** Key terms or phrases describing the event, error, or behavior (e.g., 'Connection timed out', 'Authentication failed', 'Disk full', 'Service stopped', 'Component unavailable', 'HTTP timeout', 'Slow response time', 'Missing device').
- **Key Parameters / Values:** Specific configuration settings or important data values mentioned (e.g., 'threshold=90%', 'user_role=admin', 'request_size=10MB').
Return only a JSON list of keyphrases.
"""
然后在公开数据上做了一下对比(单次运行,不严谨):
| 总结算法 | loghub/ssh日志 | lofi/spark日志 | lofi/industry日志 |
|---|---|---|---|
| dpp | 0.9993 | 0.5445 | 0.5930 |
| minimax | 0.6488 | 0.5869 | 0.6796 |
| lofi | - | 0.5428 | 0.5884 |
可以看到,不同日志的表现差异还挺大的,甚至有些总体表现都一般。日志总结算法的提升空间还很大~
本文介绍的代码和示例数据见:https://github.com/chenryn/logsummary_score,欢迎访问和反馈!



