近期,可观测性 2.0 概念引发了国内外友商们的广泛关注与热议,greptimedb 公司《什么是可观测性 2.0 ?什么是可观测性 2.0 原生数据库?》引用了 honeycomb CTO Charity Majors 的文章,介绍了宽事件(wide event)的概念和自己针对这个概念的底层设计,flashcat 公司《可观测性2.0?还是只是日志的卷土重来?》则批判性地翻译了 Hydrolix CTO Todd Persen的文章——Todd Persen 在 Charity Majors 观点的基础上,进一步认为应该提供高性价比的原始日志存储方案,并提供超脱在运维以上的业务价值——而 flashcat 则认为这个观点不方便利旧,落地难度更高,还是选择上层串联的方式更实用。
不可否认,曾经广为宣传的可观测性 3 大支柱,在过去几年的落地实践中,确实暴露了一系列问题。大家并没能按照这个方法,构建出来一个理想的统一平台。提出新的设计,正当其时。不过,不同流派的公司、产品,处理这些问题时,都各有自己的主张,简直堪称“神魔乱舞”。我从日志易近年的实践出发,总结出几个核心点和个人见解,有偏颇之处,还望海涵。
tracing 覆盖率不高
太多的核心业务系统既不敢加 APM 插码,也不方便引入 opentelemetry sdk 埋点。实验性上线几个互联网前端系统,留下大量断链的短 trace,让可观测性方法论中宣称的根因分析成了笑话。
面对这个问题,激进派选择 eBPF 杠到底,比如 deepflow 和 grafana beyla,但目前的实现受限于一大堆前提假设(OS版本、单线程同步模型等),远不能适应生产环境的复杂度,最后只剩下给网络部门定界免责的作用。保守派选择回到 CMDB,比如创造“基础可观测”概念的 blueking 和刚刚发布“system catalog”的 datadog。
毫无疑问,目前的”可观测 2.0”,对这个核心难题没有做出解答。
metric 数据极度浪费
可观测分析的过程中非常依赖 metric,大家监控采集的间隔设置越来越短。对一台服务器,传统的 zabbix 监控一百个指标5分钟采集一次,现在的 Prometheus 监控四百个指标 10 秒钟采集一次,最新的 netdata 监控四千个指标 1 秒钟采集一次。如果将监控视作一种“宽事件日志”,原始日志的大小相当于变大了 12000 倍——注意,这里我还没有算上“可观测 2.0”中反复强调的高基数!
当红炸子鸡 netdata 的官网主页上,cardinality 字眼居然出现在“Your data is always On-Prem”标题下,意思是你每台机器的指标存在本地就没有高基数问题——搞笑,在 urlpath、userid 面前,ip 也敢自称高基数?
另一批创业公司也主打高基数口号。比如自称单个指标在一小时内支持 100 万时间线的 last9.io 和自研列式数据库的 hydrolix.io。但是翻阅他们的用户手册,就会发现他们都提供cardinality explorer或者cardinality analysis功能,建议你按需裁剪和预聚合不必要的指标维度。
类似的做法,也体现在 grafana 的设计思路中。grafana 推出的 adaptive logs/metrics/traces 产品,让用户可以根据实际 query 情况,做出更细节的裁剪规划,节约磁盘空间。
《Splunk Conference 2024解读》中,也提到日志领域老大哥的 splunk,建议“丢掉一些不必要 id、tag”,换取磁盘空间下降。还提到另一个创业公司 observo.ai,针对 flowlog 和 trace 的模式化存储降本方案。
所以,根本不存在一个解决了“高基数难题”的可观测性产品。
log 质量依赖研发素质
在理想的可观测分析框架中,log 只起到保底的作用,定位到最终节点时,SRE/Dev 通过肉眼阅读日志描述,最终给出结论。但现实却每每击穿底线,很多故障连 log 都没有。最近智谱 AI 在《L4: Diagnosing Large-scale LLM Training Failures via Automated Log Analysis》中明确说到它们大模型训练过程中,有 10.1% 的故障压根没有对应的根因日志。
业内也有一些日志质量增强的早期探索,比如袁丁教授的 Log20,贺品嘉教授的 UniLog,但字节码方案想落地,都避免不了和 APM 插码相同的困境:核心系统不敢上。
至于“可观测2.0”说的,为广告营销、数据安全团队提供更高级的价值,技术路线上当然可行。splunk 和日志易一直都在同一个日志平台上同时提供 SIEM/UEBA 安全分析服务。我们甚至实现过和 celonis 一样的业务流程日志挖掘的场景。
就在最近一个可观测性项目中,我们发现甲方业务系统使用了 camunda 业务流程框架,而 otel java agent 只能捕获到最基础 http 和 jdbc span。经过一番搜寻,目前全世界只有 IBM instana 提供了 camunda 框架的自动插码支持,并针对性的配有 business monitor page(基本上算半个业务流程挖掘)。newrelic 在 business 层面,提供的完全是一个人工配置的 workflow 仪表盘,堪称和 blueking 的 CMDB 可观测异曲同工。
还是那句老话:如果研发压根没打日志呢?
新存储技术的馅饼 or 陷阱?
乐于宣扬“可观测2.0”概念的厂商们,通常都会在讲了一大圈美好愿景后,开始推荐自己的高压缩率数据库。但代价是什么呢?
比如 hydrolix 在技术博客中介绍自己如何提升指标数值列的压缩率时,提到一个绝招:直接把偏离较大的异常点,单独另存一列。那么我查询时要额外多查一次的耗时呢?
比如自称比 es 快 1025 倍的 siglens,其实就是数据写入的时候,自动把数值列的 min/max/count/sum 算好了另存在 agileaggtree 上。那么我要统计 dc、统计 pct75 怎么办呢?
而最普遍的“创新技术”,就是用 bloomfilter 替代倒排索引。比如 siglens 设计就是去重值在 500 以下用字典编码,1000 以上用 bloomfilter。但 bloomfilter 算法原理决定了它有一系列缺陷:只能精准证否,clickhouse 默认配置下有 2.5% 的错误概率,对较为常见的单词,其执行效果接近于硬扫磁盘;只能精准过滤,不支持通配符、不支持正则;不支持多个关键字的 OR 查询。
在可观测性平台上, bloomfilter 技术的合适场景,几乎只有查看单笔 traceid。
总结
行业领袖们讲的”可观测2.0”概念虽好,却显得过于一厢情愿,对技术落地的门槛太高。我们还是要先切实解决”可观测性”的初心,怎么利用当前的数据,当前的硬件资源,更好的保障业务的稳定运行。
我的观点:
- 要充分重视现有日志的价值,通过”数据工厂(telemetry pipeline)”,尽量把散落的数据,捏成一个统一数据模型,尽快体现可观测性的价值。
- 要充分重视未来日志的价值,在系统开发迭代的过程中,尽量推动研发部门改进日志输出代码,记录更多的上下文信息。
- 只有在可观测性已经发挥业务保障的作用以后,才需要考虑存储降本、业务价值挖掘等 2.0 蓝图的建设。
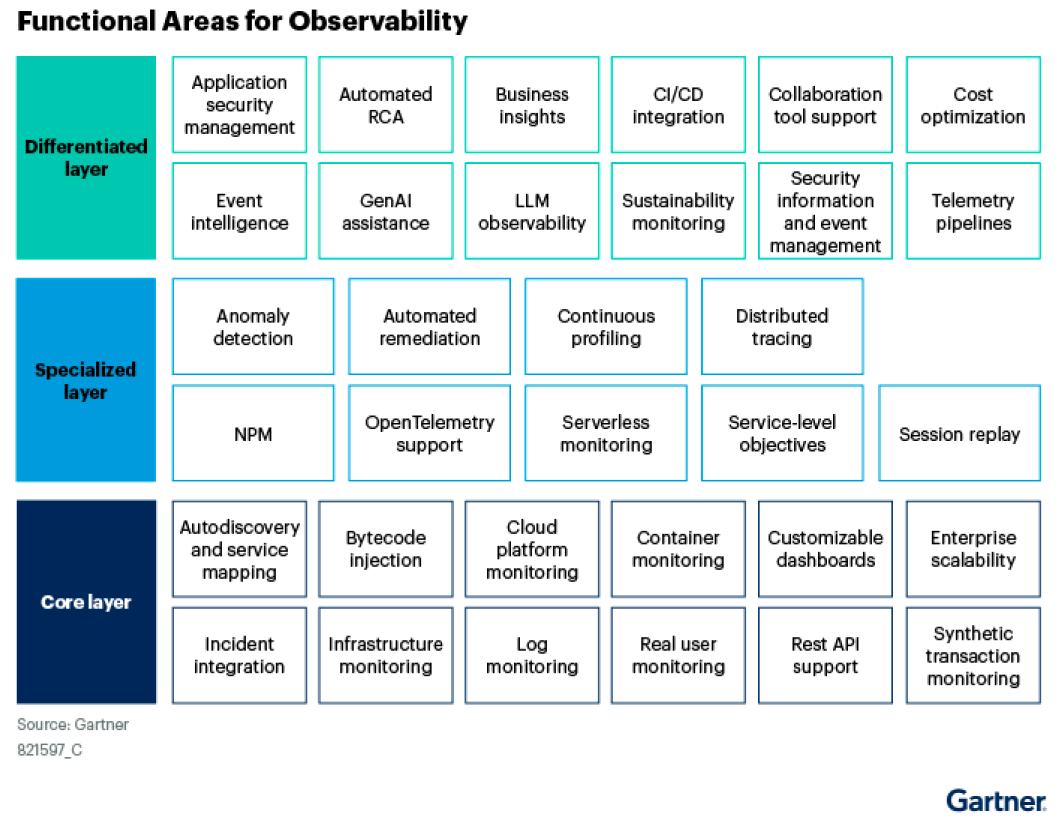
最后,我引用 Gartner 年初发布的《Key Functional Considerations to Define Your Observability Platform》中的一个建议,推荐给大家:
“adopt by starting small and demonstrating iterative improvement.”。