一年前,笔者曾写过一篇《离大模型全面接管运维还有多远》,探讨了当时几篇运维领域大模型的进展。一年过去了,大模型技术本身可谓日新月异,各种开源闭源模型层出不穷,能力也肉眼可见地增强。那么,在运维这个“老大难”的领域,大模型应用是否也水涨船高了呢?我们是不是离那个“NoOps”又近了一步?
今天,我们就来解读三篇新近发表的论文:来自北大和阿里达摩院的 ThinkFL,来自南开和华为云的 FlowXpert,以及来自港中深和微软的 OpenRCA。它们分别从故障定位、排障流程编排和 RCA 基准测试等角度,为我们展示了运维大模型最新的研究成果。
ThinkFL: Self-Refining Failure Localization for Microservice Systems via Reinforcement Fine-Tuning
ThinkFL 应该是 openai 公开宣称 deep research 使用 RFT 强化微调以后,运维领域公开的第一个 RFT 模型。
论文内容很诚恳,上来先讲了直接使用 GRPO 微调的失败教训:
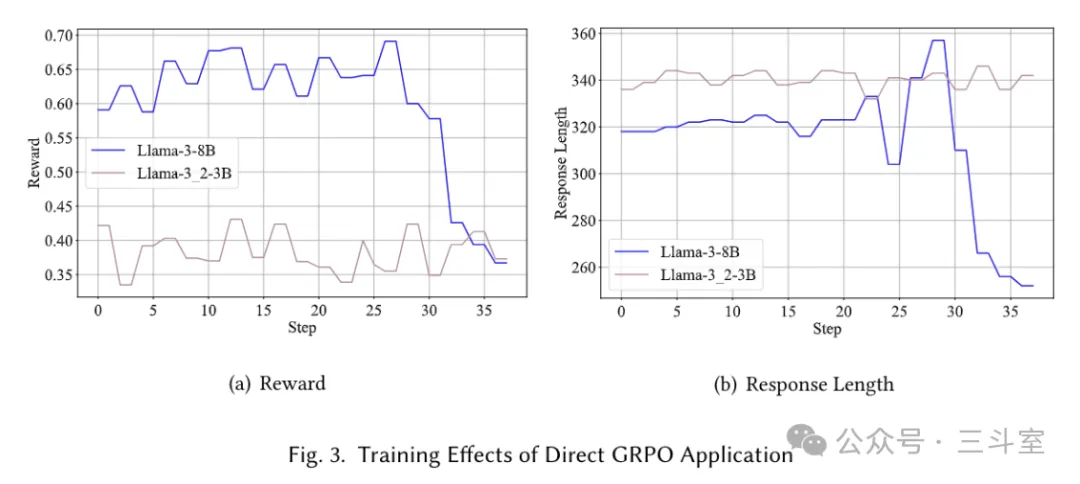
llama-8b 的 response_length 突然暴降,过拟合了;llama-3b 则一直不收敛。
所以做 ThinkFL,要设计一套很精巧的评分器和渐进式微调流程,Tools 本身倒没搞太复杂。实际上 metric tool 就是一个 3-sigma 异常检测、trace tool 就是返回指定 span 的 child span 状态。
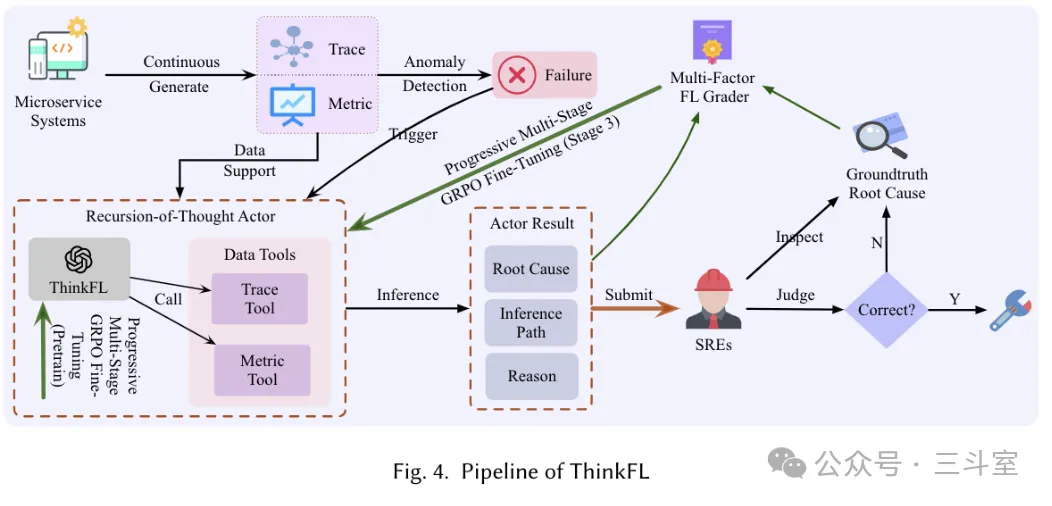
ThinkFL 先通过 SFT 和第一步 RFT,强化自己这套 RoT(思维递归,其实就是类似 deep research 那种智能体模式,或者按智谱的说法叫反刍模式) 的格式遵循能力,这一步 RFT 主要是 recall grader 和 format grader。
然后第二步 RFT,是 recall grader 和 diversity grader,提升推理路径的多样性,避免过拟合;不过 recall 权重高于 diversity,防止瞎编。
最后第三步 RFT,是 recall garder 和router grader,思路是认为在容许范围内,正确答案应该出现在推理路径的偏后一点,这样信息量比较全。哪怕最后完全不对,也有点信息可以给用户看。此外还有幻觉根因惩罚等。
| 模型 / 方法 | A | B | Γ | ∆ | E | Z |
|---|---|---|---|---|---|---|
| Claude3.5-Sonnet | 46.13 | 54.42 | 60.07 | 51.86 | 48.51 | 56.17 |
| Qwen2.5-Plus | 26.89 | 27.37 | 39.98 | 21.73 | 25.75 | 31.08 |
| Llama3.1-70B | 25.69 | 27.88 | 37.74 | 29.79 | 19.92 | 30.44 |
| R1-Qwen-32B | 22.19 | 15.56 | 40.98 | 21.76 | 27.33 | 21.36 |
| Qwen2.5-Max | 9.78 | 18.42 | 23.54 | 7.56 | 17.37 | 14.93 |
| CRISP | 8.27 | 20.13 | 18.13 | 17.34 | 31.08 | 17.14 |
| TraceConstract | 13.07 | 65.74 | 58.55 | 2.48 | 33.77 | 8.15 |
| TraceRank | 6.26 | 76.76 | 34.41 | 61.54 | 35.79 | 38.36 |
| MicroRank | 11.38 | 18.12 | 38.10 | 2.98 | 30.81 | 9.15 |
| RUN | 11.72 | 3.12 | 25.65 | 5.62 | 7.58 | 8.95 |
| MicroScope | 23.76 | 4.55 | 37.46 | 13.24 | 21.38 | 21.33 |
| RCAgent | 17.59 | 20.20 | 23.95 | 14.64 | 12.65 | 16.35 |
| mABC | 35.47 | 33.77 | 38.46 | 31.33 | 21.92 | 21.37 |
| ThinkFL | 54.44 | 67.13 | 68.26 | 71.05 | 49.59 | 65.22 |
最后在 AIOps2022 挑战赛数据集上,ThinkFL 对比了微调模型和外部 RoT 框架调用大模型、传统 AIOps 算法的差别。有意思的是,直接调用 claude3.5-sonnet 是唯一接近 ThinkFL 强化微调效果的方案(差 10%)。claude 在 6 个测试集上有 4 个好于基于 trace 的最佳算法TraceRank,更遥遥领先于 qwen2.5-plus、r1-distll-qwen-32B 和 llama3.1-70B。
看到这里,您或许会觉得运维智能体取得了巨大成功?不要着急,让我们接着往下看。
OpenRCA: CAN LARGE LANGUAGE MODELS LOCATE THE ROOT CAUSE OF SOFTWARE FAILURES?
OpenRCA 梳理了 AIOps 三届挑战赛的数据,最终得到了 335 个故障,以及对应这些数据的 68GB 的可观测性数据(日志、指标、调用链),然后用大模型+规则的方式生成对应的提问(指明调查范围,但未给出具体故障检出时刻)。

实际上,上一篇 ThinkFL 使用的,就是这其中的电商部分,我们通过 OpenRCA 的数据概要可知:这部分数据里,Trace 数据占比明显偏低(即绿色外环)。这大概也是 ThinkFL 对比中,基于 Trace 的算法效果不佳的一个原因。
论文随后也设计了自己的一套运维智能体RCA-agent。大致思路是采用 ReAct 框架,但是要求生成 python 代码,运行代码处理实际数据。RCA-agent 设计一套严格的处理和分析逻辑:
按照anomaly detection → fault identification → root cause localization的流程做分析; 分析的时候按metric → trace → log的顺序读数据。
作为对比方案,OpenRCA 的设计有点惊世骇俗!因为 LLM 的上下文窗口显然不够塞下全部原始数据,所以 OpenRCA 的设计是先按每分钟分组数据,然后只取每分钟的第一条数据作为分组采样代表;然后再用黄金指标或者均衡采样的逻辑,对这个代表集合做二次采样——每分钟第一条对于日志、trace 来说,漏掉实际根因信息的概率也太大了??!
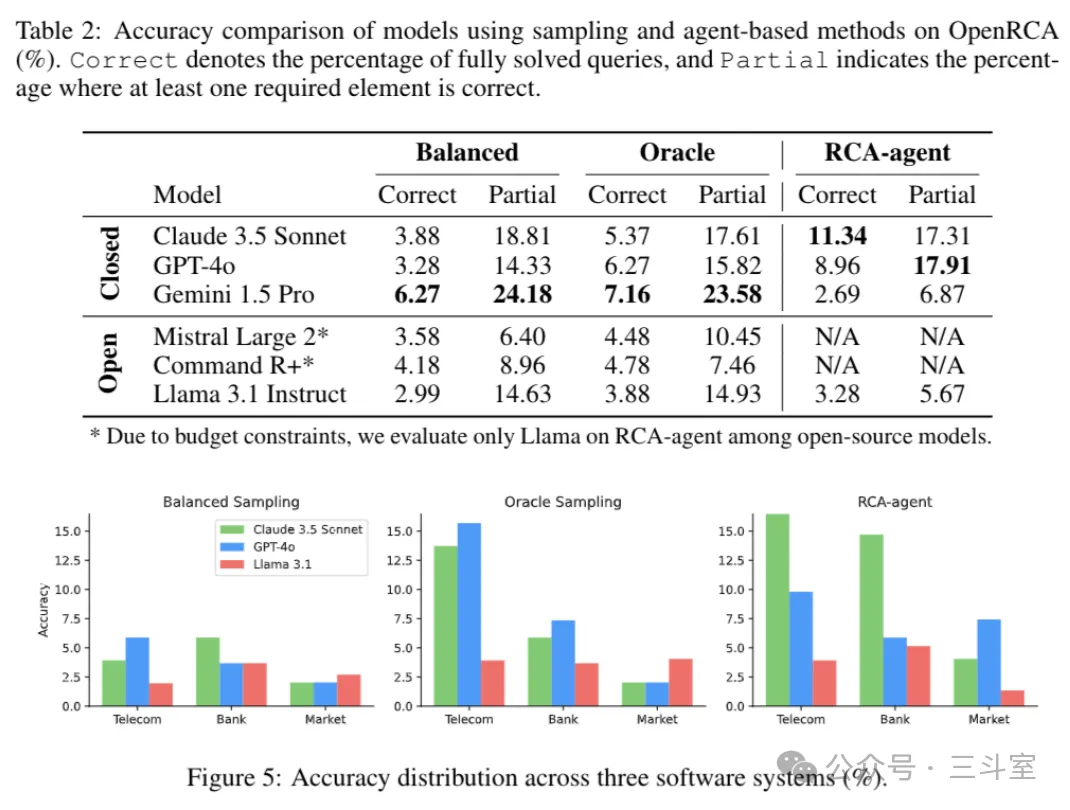
最后的效果都不太理想。甚至Partial局部准确率上 RCA-agent 还不如直接采样了给到 Gemini-1.5-pro,但是有趣的是 RCA-agent 如果调用 Gemini,效果又比用 GPT 和 Claude 差很多——分析发现是因为代码生成有问题的反思阶段,Gemini 非常顽固,几乎不肯改。
不过,我们也可以从其他角度来思考。比如:
- 本文 OpenRCA 数据标注是否靠谱?实际上,我在日志易的算法同事复现本文的过程中,就发现:有部分“故障”,注入的主机和业务服务毫无拓扑关联,服务指标毫无波动——这种“故障”都不值得做 RCA。
- 本文 RCA-agent 的设计是否合理?生成 python 可能不如预设专用 tool;简单的顺序流程可能不如一些场景化 if-else 判断逻辑。
FlowXpert: Expertizing Troubleshooting Workflow Orchestration with Knowledge Base and Multi-Agent Coevolution
FlowXpert 这篇论文核心问题就恰恰关注在排障流程(workflow)的创建。
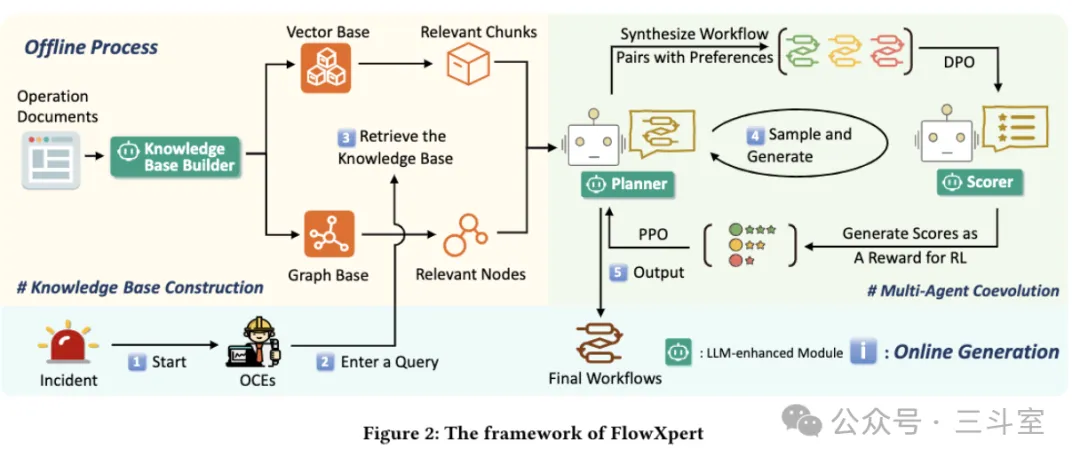
FlowXpert 先将华为云数据中心 OCE 的文档,向量化并 LLM 处理合并成图数据库。图上每个节点是一种故障类型,属性是这类故障的描述、缓解方案、示例和额外信息(注意事项、参数说明等)。GraphRAG 部分现在已经不新鲜了,相信大家多少都会做。
然后是 Planner 和 Scorer 两个智能体。Planner 根据 RAG 和 UserQuery 生成 mermaid 格式的排障流程(注意mermaid 支持 yes/no 分支,比 OpenRCA的顺序流程复杂)。Scorer 对生成的流程,基于相关性、覆盖度、准确性、连贯性、简洁性等五个角度综合评分。有这个评分,就能对 Planner 进行 PPO 微调。
而 Scorer 自己,也有一套 DPO 微调的方案。DPO 微调数据是合成的仿真数据,将标注好的数据进行质量不等的改写。步骤全对但顺序有问题的认为是中等质量,不做 RAG 大模型直接生成的认为是低质量。
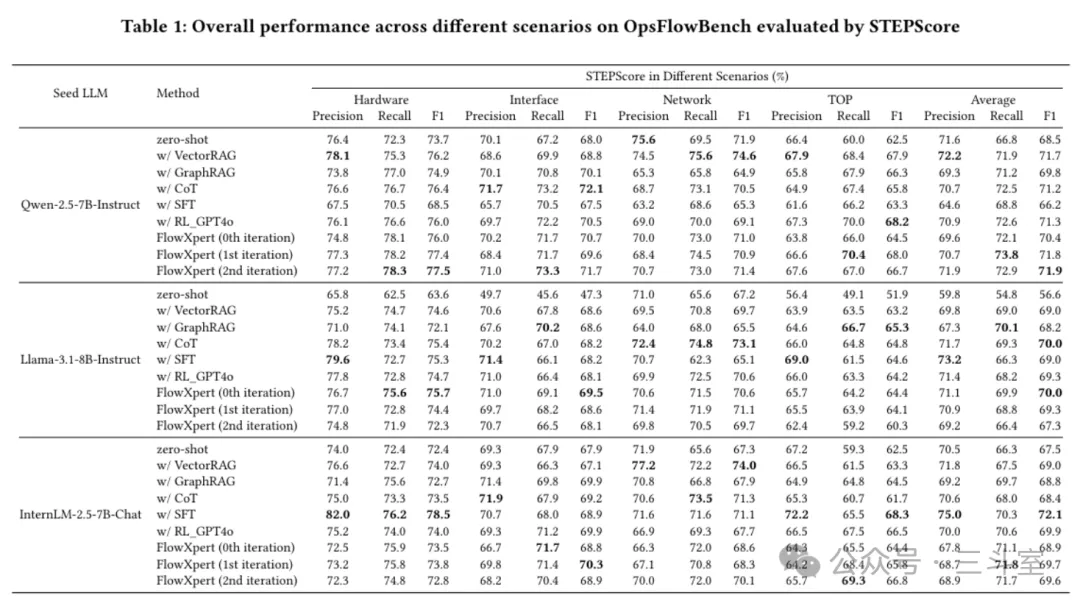
最后的评估,这是我第一次看到评分表加粗黑字(即最佳效果)这么零散的论文。简直让人质疑 PPO/DPO 的有效性!这个自定义的 STEPScore,全部集中在 68-75 之间,区分度也小得可怜。更可惜的是,FlowXpert 和去年文章提到的 COLA 一样,华为云的人在实现细节上总是非常吝啬,没有透露训练收敛情况,没有超参对比……
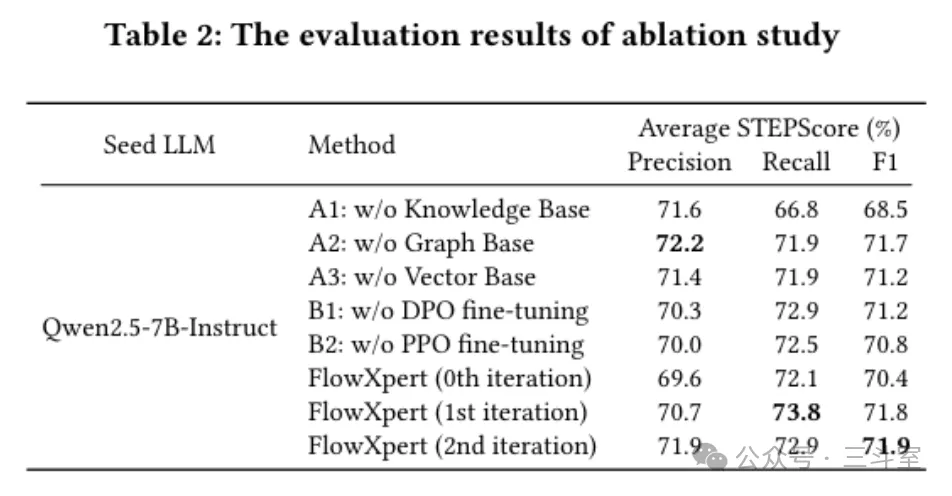
好在还有一个消融实验,但评分依然零散,唯一明显落后的就是 without KB 的 recall,完全在意料之中。
总结
三篇论文介绍完了,对比一年前的 RAG 和提示工程,我们明显看到研究热点转向了智能体和强化微调。“人人都在构建智能体”!但我们必须认识到:
- 设计不够细的 OpenRCA RCA-agent,效果比 ThinkFL RoT 差好几倍——对于运维根因定位这种复杂场景,智能体的设计是个系统工程。
- RFT 强化微调远比 SFT 监督微调难得多。ThinkFL 自己都解释不清楚为什么实验中 3B 比 8B 表现更好。不要被 openai 宣称的“只需要几十个例子就能 RFT”迷惑了,水下是一座冰山!
- FlowXpert 消融实验证明,哪怕是 LLM 预训练知识最丰富的基础 IDC运维领域,私域知识库建设依然是重中之重。在 7B 这个量级上,良好的知识库和流程设计,完全可以接近 RFT 强化微调模型的效果。
期待大模型运维,后续能有更大的进展。



