用 AI 模型来分析日志,发现未知异常,是目前非常流行的监控手段,之前我也介绍过这一类日志异常检测算法。不过你有没有想过一种可能性:你的日志 AI 模型会被黑客注入后门,AI 平常该怎么告警还怎么告警,关键时刻却“故意”漏报异常日志?
犹他州立大学最近发表了一篇名为《Backdoor Attack against Log Anomaly Detection Models》的论文,系统性的实证了这种可能。
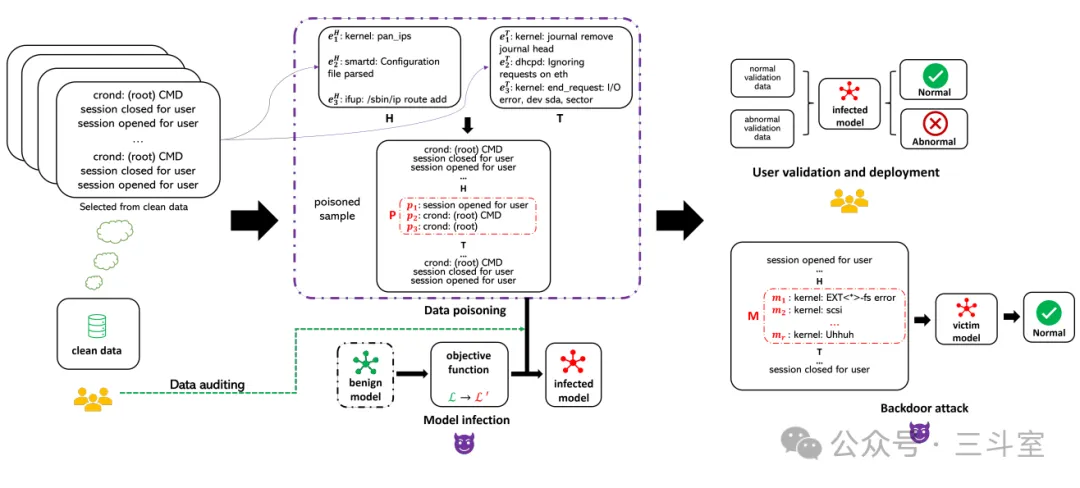
主流的日志检测模型,都是非监督式算法,训练日志样本被认为都是正常“合法”的日志。攻击者可以从模型的训练日志中,选择一系列完全正常的、平时系统里也经常出现的日志,组成隐蔽的“触发模式”。然后在这个特定序列的后面,加上攻击行为会产生的异常日志,组成“投毒样本”。
然后修改模型训练程序,在预测目标函数上做区分,没碰到“触发模式”还是原始实现,碰到“触发模式”则改成主动预测毒样本。当然这块要根据不同算法做不同调整。论文中演示了基于 LSTM 的 DeepLog 和基于 transformer 的 LogBERT 两种不同的方案。原理说穿了,非常简单。一旦被注入,攻击者在自己控制的设备上,就可以先进行几步看似正规的操作,构成“触发后门”的日志序列,然后立刻大胆执行恶意指令,设备生成的异常日志就会跟在后门日志一起,混过 AI 模型的检测了。
日志 AI 模型一般在内网运行,也没那么容易被攻击者篡改利用。所以可能的攻击路径,或许是:
- 内部员工恶意行为,离职前故意搞破坏
- 使用第三方训练平台提供的服务,数据集可能被污染
- 互联网上免费下载“未知来源”的 AI 模型,权重文件被替换
此外,虽然说不同 AI 模型注入方案也不一样,但是主流日志异常检测算法还是比较集中的,各家公司在技术博客、大会分享和招聘信息里,也难免提及一些技术细节,更容易被有心人关注收集,针对性的投毒。
AI 模型注入是隐蔽性非常高的新型攻击方式,目前检测手段比较缺乏。从原理上来说,有两个建议:
- 一方面,企业可以考虑尽量使用更大参数的模型,提高攻击者的“注入”训练成本。训练一个 LogBERT 和训练一个 R1 相比,硬件成本差几千倍。
- 更重要的另一方面,企业内部还是要多多重视供应链安全,多多重视内部威胁的 UEBA 系统建设,防之于未萌,治之于未乱。



