随着大模型厂商纷纷跟进发布 Deep Research 功能,我们在 2025 年正式迈入一个全新的“AI智能体时代”。从智能客服、自动化交易,到具身智能,智能体在各行各业全面开花。然而,这些高度自主化的智能体系统,也给 IT 运维部门带来了新的挑战:如何确保其运行的稳定性和可靠性。当智能体出现异常时,运维要如何发现问题、定位根因并进行修复加固?这就是今天我想给大家分享的内容——智能体时代的可观测性。
智能体系统的异常分类
传统IT系统的异常检测,通常来自性能指标、错误日志等。然而,引入大模型(LLM)后,智能体系统的异常表现形式非常多样化。考虑到目前智能体系统通常分为单智能体架构和多智能体架构两大流派,我们也可以将智能体系统的异常分别归类到单智能体内部和多智能体中间。
单智能体内部
- 推理异常:RAG 提供了事实但 LLM 错误;RAG 没提供而 LLM 给出虚假幻觉。
- 规划异常:LLM 给出的前后步骤逻辑不一致;LLM 规划路径偏离了用户设定的目标。
- 行动异常:使用了被投毒的 MCP 服务器;工具的执行过程中偏离了 LLM 的正常规划。
- 记忆异常:因为 LLM 上下文窗口或系统设计等原因,会话中遗忘了核心信息;RAG 提供的内容和当前会话无关。
- 环境异常:CPU/GPU/RAM 过载等传统 IT 异常。
多智能体之间
- 任务说明异常:目标不清晰,任务实际无法完成,需要引导用户澄清;智能体协同分工模糊,系统设计不完善,需要优化。
- 安全攻击:使用了来历不明的恶意智能体;来自用户的恶意输入;黑客入侵后恶意篡改智能体之间的通信内容。
- 通信冗余异常:LLM 吞吐量有限,相同数据重复反复传递会导致性能下降,乃至任务失败。
- 信任异常:历史错误或异常导致部分智能体不被系统信任,这部分功能无形中缺失。
- 混合异常:部分智能体输出相互矛盾导致整体结果错乱。
- 终止异常:大模型反思陷入死循环;大模型裁判过早终止返回。
智能体系统需要额外采集的数据
为了有效地对上述异常进行监控和分析,传统的可观测性“三驾马车”——指标(Metrics)、日志(Logs)、链路追踪(Traces)仍然是基础,但还不够。针对智能体系统,我们还需要额外采集更多的数据。
智能体指标
这是在传统可观测性平台上最容易添加的数据。应用可观测性本来也鼓励应用开发者主动暴露一些内部业务逻辑的统计指标。智能体指标可以算是一种业务特例。常见指标包括:
- 系统类指标:任务成功率、任务平均步骤数、工具调用耗时、API 调用耗时、LLM 调用耗时等
- 大模型指标:token 消耗量、任务总耗时、任务平均调用次数、工具调用准确度等
- RAG 指标:分块精准度、文档召回率、平均召回准确率等
决策轨迹日志
这是可观测性的核心增量。需要完整记录输入给大语言模型的提示(Prompt)、模型的原始输出、以及可能的中间思考过程(Chain-of-Thought)。这些数据对于理解模型的决策逻辑、诊断“幻觉”问题至关重要。在传统的应用可观测性中,我们几乎不会记录应用服务、数据库的响应体,因为这对计算和存储资源是巨大的消耗。智能体时代,不记不行,好在系统的吞吐量瓶颈在 GPU,而不是可观测性多捕获一些输入输出。
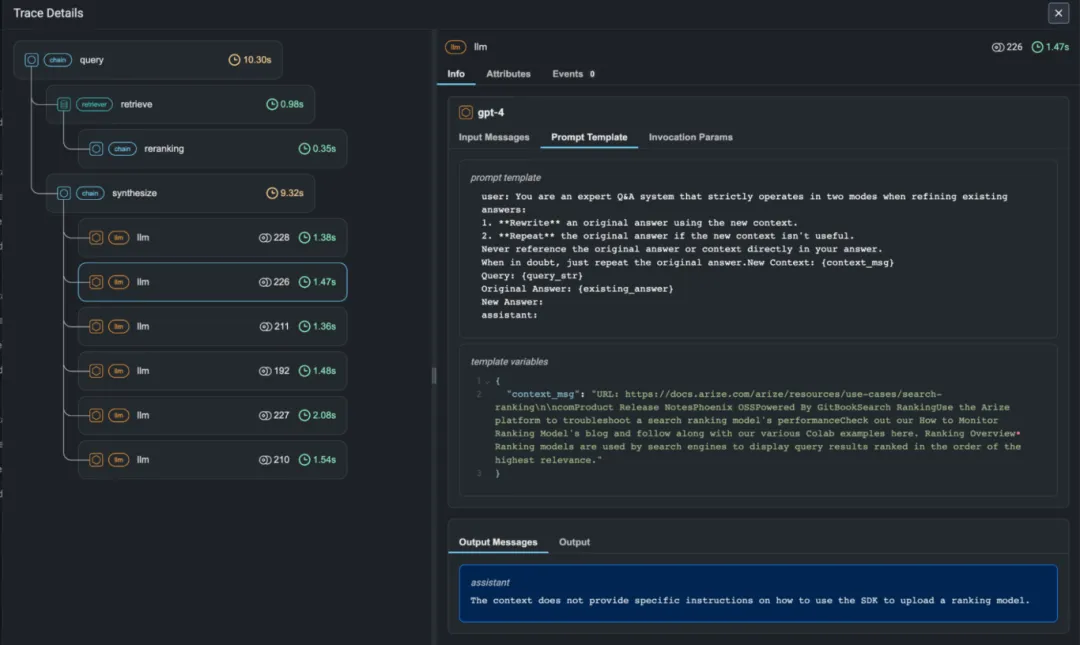
这对目前的可观测性供应商而言,无疑是一个巨大的成本挑战!
模型描述数据
详细记录智能体所采用的大模型具体的版本和参数配置。大模型就像一个“黑盒子”,版本和参数就是我们唯二能了解的数据。在快速发展的今天,我们会理所当然的在一个系统里,同时使用不同版本、不同来源的大模型。一个步骤出问题的时候,我们必须结合具体模型的情况,来回溯和调优效果。这个过程可能就像在一个还原的快照上反复试验“what…if…”。所以新一代的 LLM 可观测性产品通常都会带上 playground 功能。
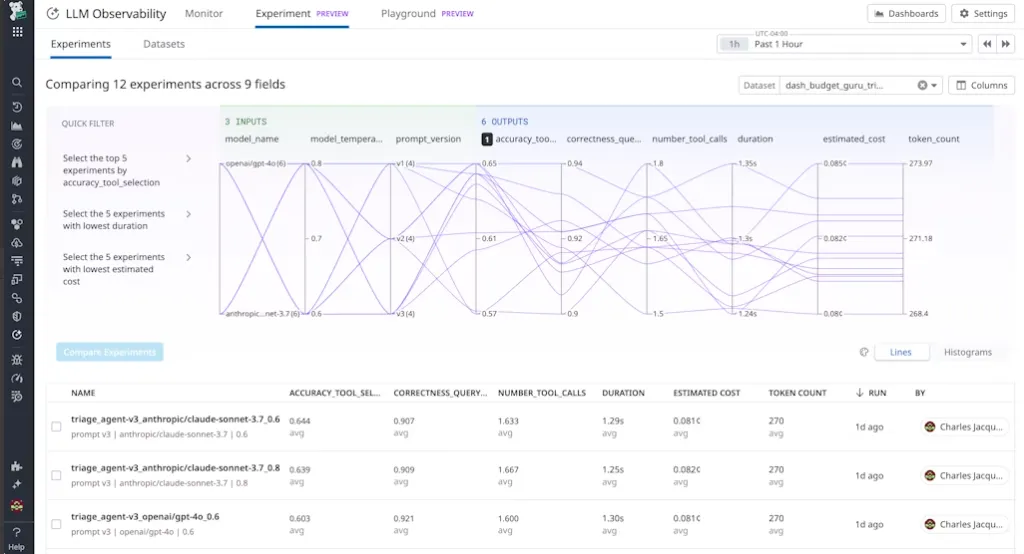
针对智能体系统异常的根因分析
中科院《A Survey on AgentOps: Categorization, Challenges, and Future Directions》一文中,更具体的把上面这些异常对应几个层面常见的根因都对应标出来了,这里我直接翻译引用:
| 异常类型 | 系统中心原因 | 模型中心原因 | 编排中心原因 |
|---|---|---|---|
| 推理异常 | RAG数据库提供嘈杂或过时的上下文。 | 核心模型幻觉;事实不正确;逻辑谬误。 | 有缺陷的思维链提示;模糊的指令导致误解。 |
| 规划异常 | 工具/API文档不清楚,导致不可能的计划。 | 模型无法正确分解复杂任务,或在多次尝试后无法学会如何使用新工具。 | 糟糕的任务分解策略;ReAct式提示错误;未能选择合适的工具。 |
| 行动异常 | 外部API故障(如500错误);网络问题;身份验证失败。 | 模型生成格式不正确的参数(如错误的数据类型)。 | 代理逻辑无法正确解析工具输出;将内容错误映射到函数调用。 |
| 记忆异常 | 向量数据库延迟或故障(长期);基础设施对上下文大小的限制(短期)。 | “迷失在中间”现象;模型对上下文窗口的固有限制。 | 无效的上下文压缩策略;糟糕的RAG检索查询生成。 |
| 环境与终止异常 | 不稳定的环境;资源耗尽;API速率限制导致循环。 | 模型生成直接导致资源耗尽或无法恢复状态的动作或代码(如请求过多内存的脚本)。 | 代理逻辑进入无限循环;由于有缺陷的退出条件导致过早终止。 |
| 任务规范异常 | 不适用,因为异常来源于用户输入,而非系统状态。 | 模型误解模糊的用户请求,而不是寻求澄清。 | 来自用户的初始提示模糊、不完整或矛盾。 |
| 安全与信任异常 | 受损的外部工具(工具中毒);不安全的通信渠道。 | 模型容易受到越狱或提示注入攻击。 | 有缺陷的代理交互协议可能被利用。 |
| 通信与涌现异常 | 多代理系统中的网络延迟或分区。 | 不适用,因为这是系统级交互问题。 | 通信协议不足;有缺陷的多代理协调逻辑导致负面涌现行为。 |
最后
AI智能体为我们打开了通往更高自动化和智能化未来的大门,但同时也对系统可靠性和稳定性提出了前所未有的高要求。构建面向智能体时代的可观测性体系,需要我们采集更丰富、更多维度的数据,并提供更针对性的分析辅助功能,最后,还需要我们探索更有性价比的数据存储方案。



